Microsoft announces general availability of Apache Spark for Azure HDInsight
![]() 3 min. read
3 min. read
![]() Published on
Published on
Share this article

Improve this guide
Readers help support MSpoweruser. We may get a commission if you buy through our links.

Read our disclosure page to find out how can you help MSPoweruser sustain the editorial team Read more


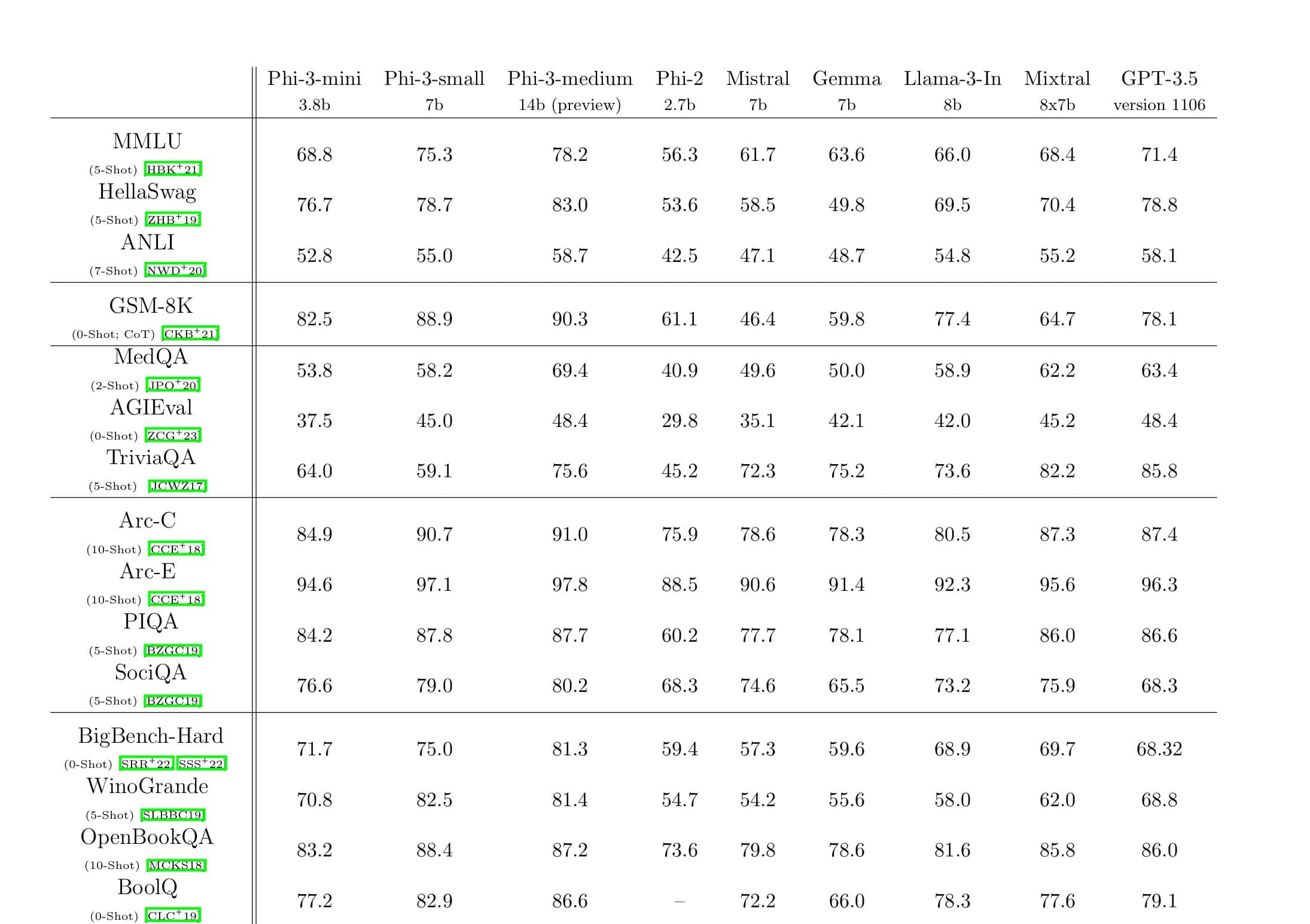
Microsoft today announced the general availability of Apache Spark v1.6.1 for Azure HDInsight. Microsoft highlighted that Spark for HDInsight has gained rapid adoption since the public preview period and is now 50% of all new HDInsight clusters deployed. Microsoft is also announcing improvements to the availability, scalability, and productivity of our managed Spark service.
Spark for Azure HDInsight features:
- For high availability, Microsoft worked with Hortonworks to add capabilities to the YARN resource manager and co-led “Project Livy” with Cloudera and other organizations to create an open source Apache licensed REST web service for managing long running Spark contexts and submitting Spark jobs. This new capability was designed to make Spark a more robust back-end for running interactive notebooks and allow other applications to leverage Spark for their interactive workloads. By ensuring high availability with Spark, we now offer the highest guarantee for Spark in the market with a 99.9% service level agreement.
- To ensure that Spark will run at scale, we are announcing integration between Spark and Azure Data Lake Store. This will allow Spark to store and process data of any size built on a repository designed for the cloud to capture data of any size, type and speed without forcing changes to your application as data scales.
- For securing Spark, we are enabling role-based data access at the storage level through the integration of Spark and Data Lake Store.
- For the data engineer and developers, we introduced deep integration with the IntelliJ IDE. This allows developers to code with native authoring support for Scala and Java, local testing, remote debugging, and the ability to submit Spark applications to the Azure cloud.
- For data scientists, we introduced out-of-the-box integration with Jupyter (iPython) notebooks allowing you to create narratives that combine code, statistical equations, and visualizations that tell a story about the data. This environment is ideal for extracting data from any source and iteratively building ML models while writing exploratory queries to visualize and understand properties of the data. We made this possible by working with the Jupyter OSS community to enhance the kernel to allow Spark execution through a REST endpoint. As a result, Jupyter notebooks are now accessible within HDInsight out-of-the-box.
- For the business analysts, we offer integration with Power BI alongside other BI tools like Tableau, SAP Lumira, and QlikView. This lets you build interactive visualizations over data of any size. In addition to the traditional dashboards, Power BI offers a streaming connector that has integration with Spark allowing you to publish real-time events from Spark Streaming directly to Power BI.
Read more about it in detail here.