Microsoft introduces Phi-3 family of models that outperform other models of its class
![]() 2 min. read
2 min. read
![]() Updated on
Updated on
Share this article
Improve this guide
Read our disclosure page to find out how can you help MSPoweruser sustain the editorial team Read more
Back in December 2023, Microsoft released Phi-2 model with 2.7 billion parameters that delivered state-of-the-art performance among base language models with less than 13 billion parameters. In the past four months, several other models that got released outperformed Phi-2. Recently, Meta released Llama-3 family of models that outperformed all the previously released open-source models.
Last night, Microsoft Research announced Phi-3 family of models via a technical report. There are three models in the Phi-3 family:
- phi-3-mini (3.8B)
- phi-3-small (7B)
- phi-3-medium (14B)
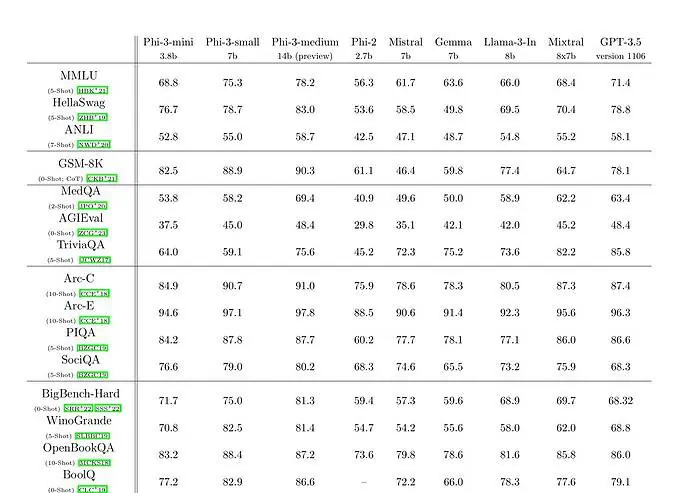
The phi-3-mini with a 3.8 billion parameter language model is trained on 3.3 trillion tokens. According to benchmarks, phi-3-mini beats Mixtral 8x7B and GPT-3.5. Microsoft claims that this model is small enough to be deployed on a phone. Microsoft used a scaled-up version of the dataset which was used for phi-2, composed of heavily filtered web data and synthetic data. According to Microsoft’s benchmark results on the Technical Paper, phi-3-small and phi-3-medium achieve an impressive MMLU score of 75.3 and 78.2 respectively.
In terms of LLM capabilities, while the Phi-3-mini model achieves a similar level of language understanding and reasoning ability as those of much larger models, it is still fundamentally limited by its size for certain tasks. The model simply does not have the capacity to store extensive factual knowledge, which can be seen, for example, with low performance on TriviaQA. However, we believe this weakness can be resolved by augmentation with a search engine.


User forum
0 messages