GPT-4 now available to ChatGPT Plus subscribers
![]() 3 min. read
3 min. read
![]() Published on
Published on
Share this article

Improve this guide
Read our disclosure page to find out how can you help MSPoweruser sustain the editorial team Read more

OpenAI finally unveiled GPT-4. According to the company, its latest AI model is more precise and efficient as it can handle more input without confusion. In addition to that, GPT-4 indeed has multimodal capability, allowing it to process images. GPT-4 is now available to ChatGPT Plus subscribers, and developers can now access it as an API.
After reports about its arrival last week, GPT-4 is finally here, delivered via Azure’s AI-optimized infrastructure. It was trained on Microsoft Azure AI supercomputers and has some notable differences from GPT-3.5. In particular, GPT-4 scored in the 88th percentile and above in different tests and benchmarks.
“In a casual conversation, the distinction between GPT-3.5 and GPT-4 can be subtle,” OpenAI says in a blog post. “The difference comes out when the complexity of the task reaches a sufficient threshold — GPT-4 is more reliable, creative and able to handle much more nuanced instructions than GPT-3.5.”
In general, OpenAI said it is 82% less possible the new model will respond to restricted topics and requests, making it safe for users. The quality of its response is also improved, with up to 40% likelihood of producing factual answers.
A huge part of GPT-4 focuses on its ability to handle queries more effectively. As OpenAI noted, it can now accept 25,000 words of text without experiencing confusion. This is good news for users who want to use the model’s full potential, as they will be allowed to provide more details and instructions in their questions and requests. The biggest highlight of GPT-4, though, is the addition of a multimodal capability, which was one of the biggest expectations from the model since it was reported last week. Using this new capability, GPT-4 can now process image inputs and describe them through texts, though it isn’t available to all OpenAI customers just yet as it is still technically under test with the help of Be My Eyes and its Virtual Volunteer feature.

“For example, if a user sends a picture of the inside of their refrigerator, the Virtual Volunteer will not only be able to correctly identify what’s in it, but also extrapolate and analyze what can be prepared with those ingredients,” OpenAi described the function. “The tool can also then offer a number of recipes for those ingredients and send a step-by-step guide on how to make them.”
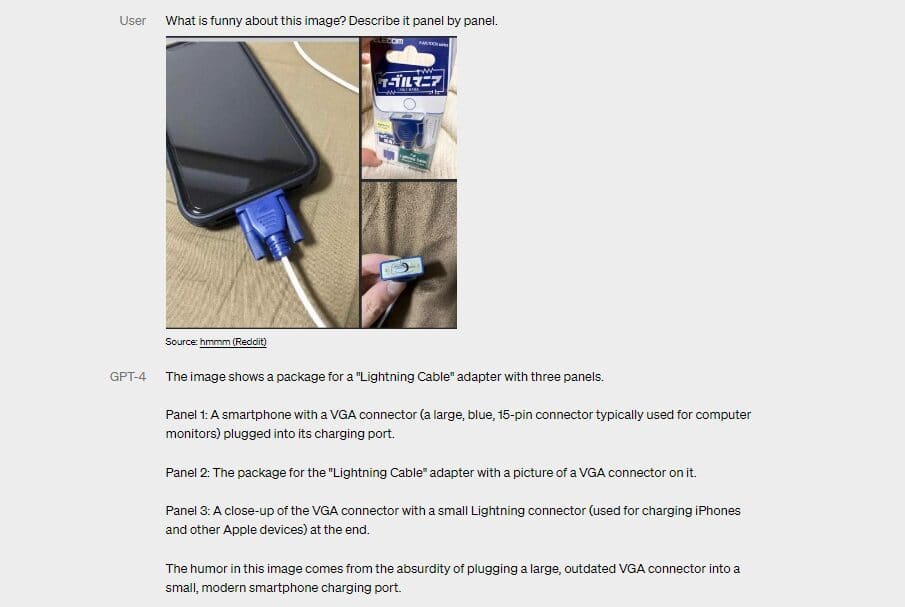
Wow Bing can now actually describe images, now that it knows that its using GPT-4!
byu/BroskiPlaysYT inbing
Nonetheless, this multimodality capability seems to be partially brought into the new Bing. Microsoft said the chatbot of its search engine has been running the model since last week. However, it is important to note that Bing’s multimodal feature is still limited. To start, it can only accept images via links provided on the web, which it will describe as a response. Meanwhile, when asked for images using descriptions, the chatbot will provide the most relevant content, including image results and more.
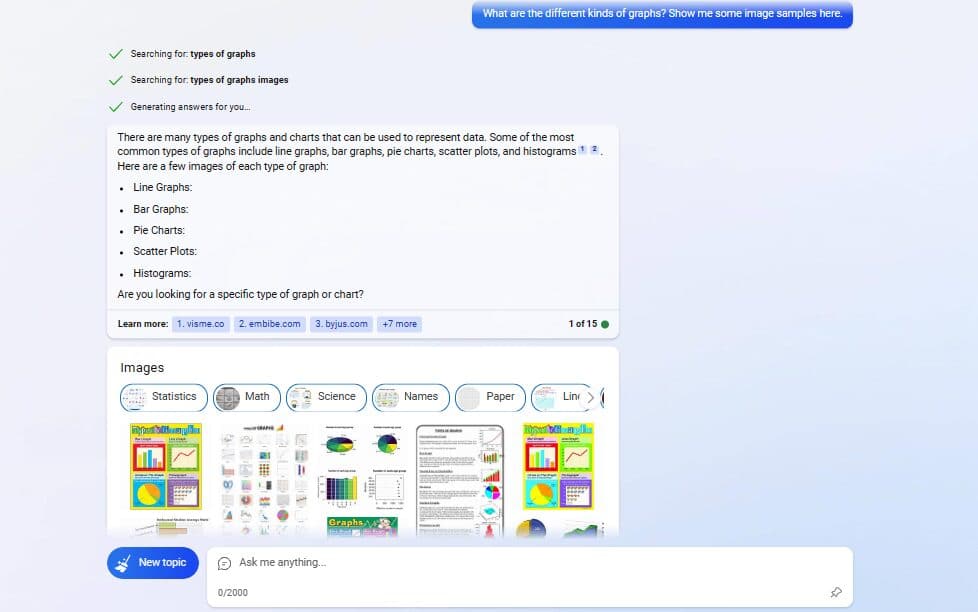
On a side note, these improvements in GPT-4 don’t mean the end of existing issues commonly present in all generative AI products. Though OpenAI promised the model to be safer than GPT-3.5 in terms of refusing to respond to harmful instructions, it can still generate hallucinations and social biases. OpenAI CEO Sam Altman even described GPT-4 as something “still flawed, still limited.” Despite this, the team is dedicated to continuous improvement of the model as it continues to attract more attention from the public and as Microsoft injects it into more of its products.



User forum
0 messages