Microsoft posts root cause analysis for this week's big Microsoft 365 login issues
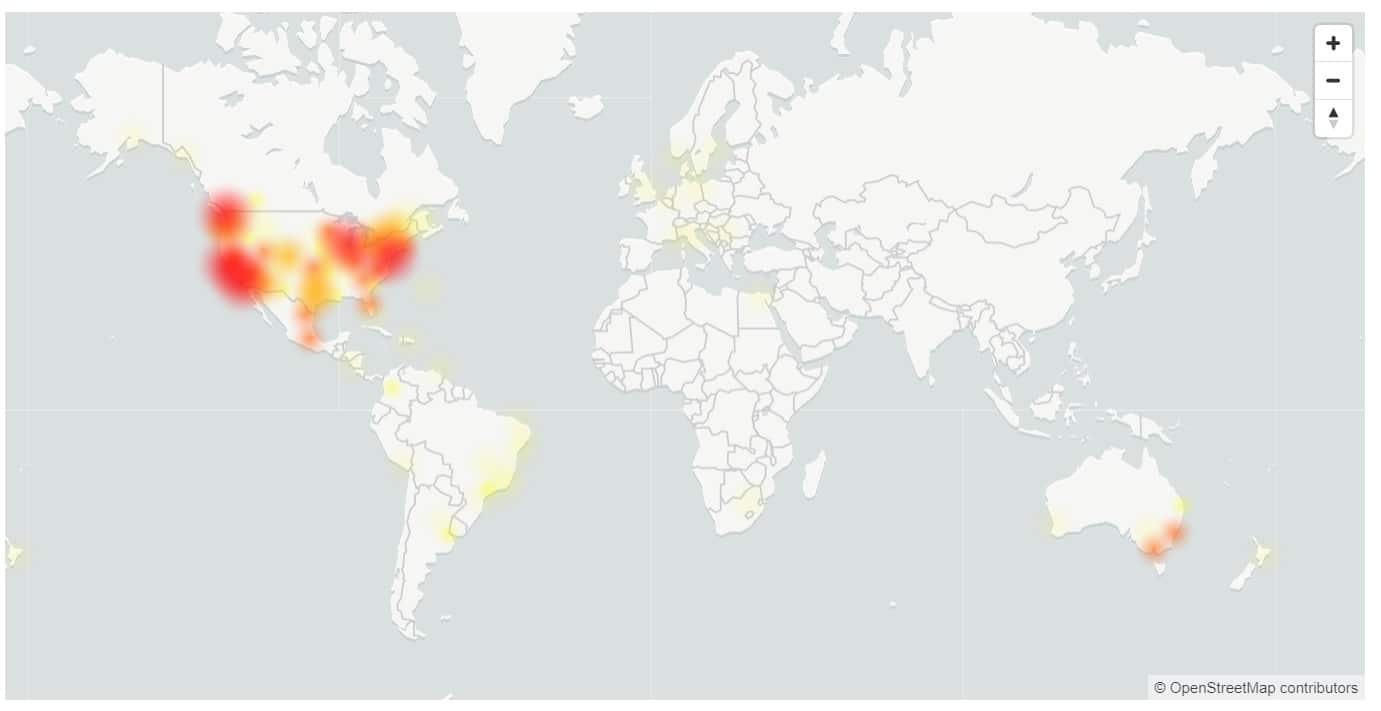
This week we had a nearly 5-hour long downtime for Microsoft 365, with users unable to log in to multiple services, including OneDrive and Microsoft Teams.
Today Microsoft published a root-cause analysis of the issue, which Microsoft says was due to service update which was meant to be targeting an internal validation test ring but which was instead deployed directly into Microsoft’s production environment due to a latent code defect in the Azure AD backend service Safe Deployment Process (SDP) system.
Microsoft says that between approximately 21:25 UTC on September 28, 2020 and 00:23 UTC on September 29, 2020, customers encountered errors performing authentication operations for all Microsoft and third-party applications and services that depend on Azure Active Directory (Azure AD) for authentication. The issue was only completely mitigated for all by 2:25 the next day.
USA and Australia were the hardest hit, with only 17% of users in USA able to sign in successfully.
The issue was compounded by Microsoft being unable to roll back the update due to the latent defect in their SDP system corrupting the deployment metadata, meaning the update had to be manually rolled back.
Microsoft apologized to impacted customers and say they are continuing to take steps to improve the Microsoft Azure Platform and their processes to help ensure such incidents do not occur in the future. One of the planned steps includes applying additional protections to the Azure AD service backend SDP system to prevent the class of issues identified.
Read the full analysis below:
RCA – Authentication errors across multiple Microsoft services and Azure Active Directory integrated applications (Tracking ID SM79-F88)
Summary of Impact: Between approximately 21:25 UTC on September 28, 2020 and 00:23 UTC on September 29, 2020, customers may have encountered errors performing authentication operations for all Microsoft and third-party applications and services that depend on Azure Active Directory (Azure AD) for authentication. Applications using Azure AD B2C for authentication were also impacted.
Users who were not already authenticated to cloud services using Azure AD were more likely to experience issues and may have seen multiple authentication request failures corresponding to the average availability numbers shown below. These have been aggregated across different customers and workloads.
- Europe: 81% success rate for the duration of the incident.
- Americas: 17% success rate for the duration of the incident, improving to 37% just before mitigation.
- Asia: 72% success rate in the first 120 minutes of the incident. As business-hours peak traffic started, availability dropped to 32% at its lowest.
- Australia: 37% success rate for the duration of the incident.
Service was restored to normal operational availability for the majority of customers by 00:23 UTC on September 29, 2020, however, we observed infrequent authentication request failures which may have impacted customers until 02:25 UTC.
Users who had authenticated prior to the impact start time were less likely to experience issues depending on the applications or services they were accessing.
Resilience measures in place protected Managed Identities services for Virtual Machines, Virtual Machine Scale Sets, and Azure Kubernetes Services with an average availability of 99.8% throughout the duration of the incident.
Root Cause: On September 28 at 21:25 UTC, a service update targeting an internal validation test ring was deployed, causing a crash upon startup in the Azure AD backend services. A latent code defect in the Azure AD backend service Safe Deployment Process (SDP) system caused this to deploy directly into our production environment, bypassing our normal validation process.
Azure AD is designed to be a geo-distributed service deployed in an active-active configuration with multiple partitions across multiple data centers around the world, built with isolation boundaries. Normally, changes initially target a validation ring that contains no customer data, followed by an inner ring that contains Microsoft only users, and lastly our production environment. These changes are deployed in phases across five rings over several days.
In this case, the SDP system failed to correctly target the validation test ring due to a latent defect that impacted the system’s ability to interpret deployment metadata. Consequently, all rings were targeted concurrently. The incorrect deployment caused service availability to degrade.
Within minutes of impact, we took steps to revert the change using automated rollback systems which would normally have limited the duration and severity of impact. However, the latent defect in our SDP system had corrupted the deployment metadata, and we had to resort to manual rollback processes. This significantly extended the time to mitigate the issue.
Mitigation: Our monitoring detected the service degradation within minutes of initial impact, and we engaged immediately to initiate troubleshooting. The following mitigation activities were undertaken:
- The impact started at 21:25 UTC, and within 5 minutes our monitoring detected an unhealthy condition and engineering was immediately engaged.
- Over the next 30 minutes, in concurrency with troubleshooting the issue, a series of steps were undertaken to attempt to minimize customer impact and expedite mitigation. This included proactively scaling out some of the Azure AD services to handle anticipated load once a mitigation would have been applied and failing over certain workloads to a backup Azure AD Authentication system.
- At 22:02 UTC, we established the root cause, began remediation, and initiated our automated rollback mechanisms.
- Automated rollback failed due to the corruption of the SDP metadata. At 22:47 UTC we initiated the process to manually update the service configuration which bypasses the SDP system, and the entire operation completed by 23:59 UTC.
- By 00:23 UTC enough backend service instances returned to a healthy state to reach normal service operational parameters.
- All service instances with residual impact were recovered by 02:25 UTC.
Next Steps: We sincerely apologize for the impact to affected customers. We are continuously taking steps to improve the Microsoft Azure Platform and our processes to help ensure such incidents do not occur in the future. In this case, this includes (but is not limited to) the following:
We have already completed
- Fixed the latent code defect in the Azure AD backend SDP system.
- Fixed the existing rollback system to allow restoring the last known-good metadata to protect against corruption.
- Expand the scope and frequency of rollback operation drills.
The remaining steps include
- Apply additional protections to the Azure AD service backend SDP system to prevent the class of issues identified here.
- Expedite the rollout of Azure AD backup authentication system to all key services as a top priority to significantly reduce the impact of a similar type of issue in the future.
- Onboard Azure AD scenarios to the automated communications pipeline which posts initial communication to affected customers within 15 minutes of impact.
Provide Feedback: Please help us improve the Azure customer communications experience by taking our survey: https://aka.ms/AzurePIRSurvey
via ZDNet
Read our disclosure page to find out how can you help MSPoweruser sustain the editorial team Read more


Improve this guide



User forum
0 messages