Is Claude 3 really better than GPT-4? Promptbase's benchmarking says different
Head-to-head tests show GPT-4 Turbo edges out Claude 3 in all categories.
![]() 2 min. read
2 min. read
![]() Updated on
Updated on
Share this article

Improve this guide
Read our disclosure page to find out how can you help MSPoweruser sustain the editorial team Read more
Key notes
- Anthropic recently launched Claude 3, touted to outperform GPT-4 and Google Gemini 1.0 Ultra.
- Posted benchmark scores indicate Claude 3 Opus excels in various areas compared to its counterparts.
- However, further analysis suggests GPT-4 Turbo outperforms Claude 3 in direct comparisons, implying potential biases in reported results.

Anthropic has just launched Claude 3 not too long ago, its AI model that’s said to be able to beat OpenAI’s GPT-4 and Google Gemini 1.0 Ultra. It comes with three variants: Claude 3 Haiku, Sonnet, and Opus, all for different uses.
In its initial announcement, the AI company says that Claude 3 is slightly superior to these two recently launched models.
According to the posted benchmark scores, Claude 3 Opus is better in undergraduate-level knowledge (MMLU), graduate-level reasoning (GPQA), grade school math and math problem-solving, multilingual math, coding, reasoning over text, and others more than GPT-4 and Gemini 1.0 Ultra and Pro.
However, that does not entirely paint the entire picture truthfully. The posted benchmark score on the announcement (especially for GPT-4) was apparently taken from GPT-4 on the release version from March 2023 last year (credits to AI enthusiast @TolgaBilge_ on X)
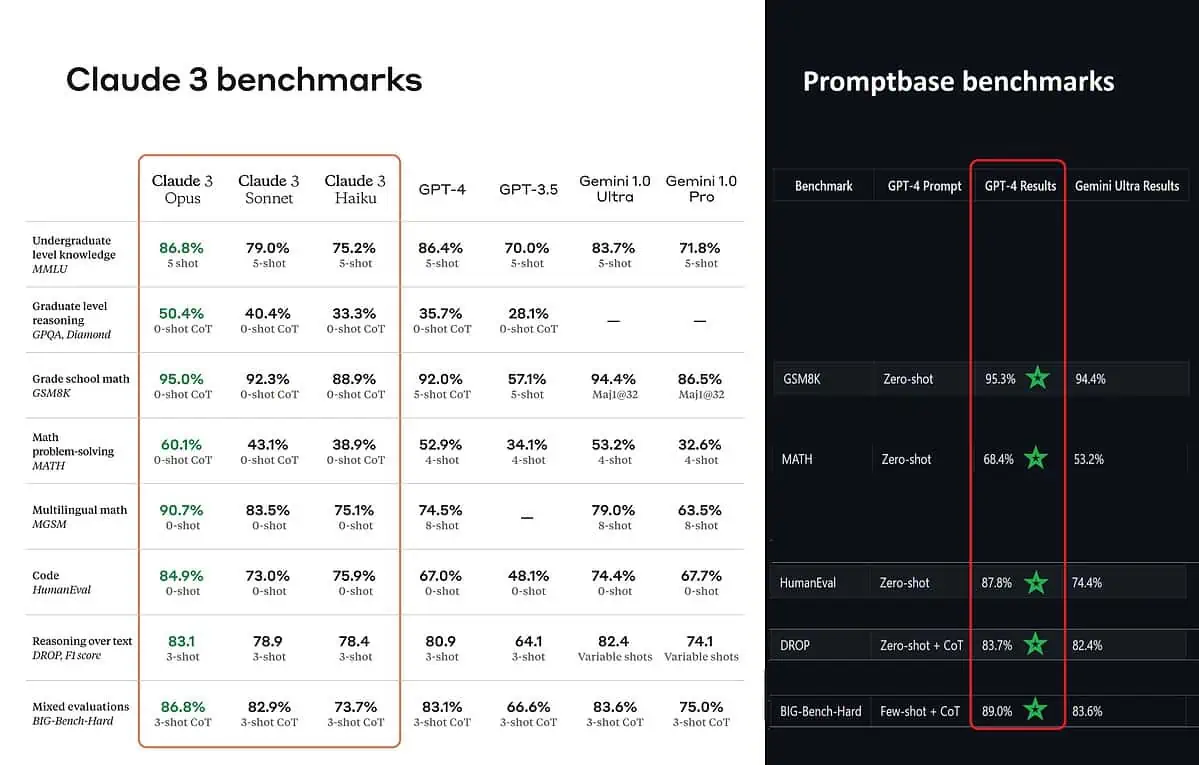
A tool that analyzes performance (benchmark analyzer) called Promptbase shows that GPT-4 Turbo actually does beat Claude 3 in all the tests they could directly compare them on. These tests cover things like basic math skills (GSM8K & MATH), writing code (HumanEval), reasoning over text (DROP), and a mix of other challenges.
While announcing their results, Anthropic also mentions in a footnote that their engineers were able to improve GPT-4T’s performance further by fine-tuning it specifically for the tests. This suggests the reported results might not reflect the true capabilities of the base model.
Ouch.



User forum
0 messages