Google’s text-to-image generator Imagen produces pictures with ‘unprecedented degree of photorealism’
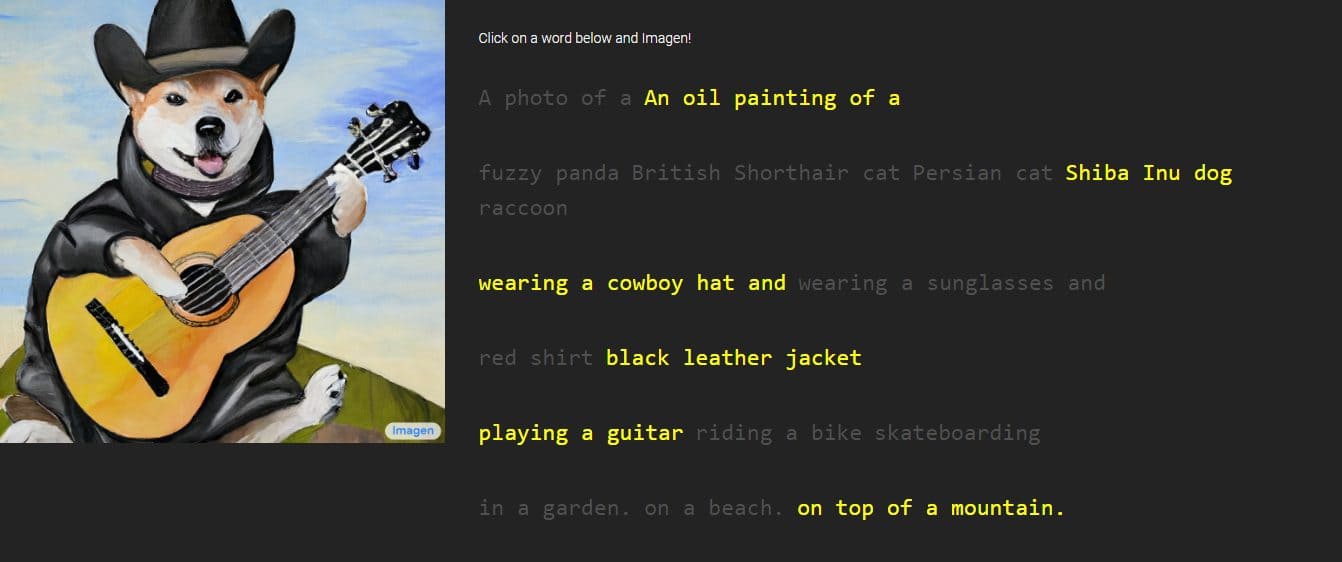
Google unveiled a new creation called “Imagen,” a text-to-image generator through descriptions a person will provide. The company claims that it surpasses the performance of DALL-E 2, another AI image generator. It presented some samples, which undeniably show exquisite details, but Imagen is currently unavailable to the public.
The new text-to-image diffusion model is described to have “an unprecedented degree of photorealism and a deep level of language understanding.” It understands text through large transformer language models and is said to rely on diffusion models to perform high-fidelity image generation.

Google provided images and samples of Imagen’s work, with styles varying from drawings to oil paintings and CGIs. They are accompanied by the words and phrases used to generate them. For instance, one sample reads, “a dragon fruit wearing karate belt in the snow,” while the other has the description “a small cactus wearing a straw hat and neon sunglasses in the Sahara desert.”
The generated images look incredibly real as if they were created by an actual person. However, Google says that it is done through diffusion technologies by utilizing a pure noise image and refining it in the best way possible. By understanding the text description provided, Imagen will generate a 64 x 64-pixel image, perform two enhancements, and convert the image into a larger 1024 x 1024-pixel piece.
Google Research, Brain Team says that Imagen excelled on COCO (a large-scale object detection, segmentation, and captioning dataset) despite not being trained on it. The team reported that it received a new state-of-the-art FID score of 7.27.
Google also compared Imagen’s performance to other text-to-image models by assessing them using “DrawBench.” It serves as a benchmark for text-to-image models where Google tested Imagen with other methods like VQ-GAN+CLIP, Latent Diffusion Models, and DALL-E 2. After testing for their compositionality, cardinality, spatial relations, long-form text, rare words, and challenging prompts, the team said that “human raters strongly prefer Imagen over other methods, in both image-text alignment and image fidelity.”
Despite these impressive reports from the research team, testing Imagen yourself won’t be possible as it is not accessible to the public. Google has reasons for that, such as ethical challenges, potential risks of misuse, social biases, limitations of large language models, and risk of encoded harmful stereotypes and representations. The team summarizes that with all these challenges, Imagen is still not perfect when it comes to generating images related to people.
“Imagen exhibits serious limitations when generating images depicting people,” the team explains in a blog post. “Our human evaluations found Imagen obtains significantly higher preference rates when evaluated on images that do not portray people, indicating a degradation in image fidelity. Preliminary assessment also suggests Imagen encodes several social biases and stereotypes, including an overall bias towards generating images of people with lighter skin tones and a tendency for images portraying different professions to align with Western gender stereotypes. Finally, even when we focus generations away from people, our preliminary analysis indicates Imagen encodes a range of social and cultural biases when generating images of activities, events, and objects. We aim to make progress on several of these open challenges and limitations in future work.”
Read our disclosure page to find out how can you help MSPoweruser sustain the editorial team Read more


Improve this guide
User forum
0 messages