Benchmark suggests Phi-3-vision is on-par with Claude 3-haiku & Gemini 1.0 Pro, if not better
Microsoft launched Phi-3-vision a little while ago.
Key notes
- Microsoft launched Phi-3-vision a little while ago.
- Now, recent benchmark suggests it’s on par with other smaller models, if not better.
- The small model itself is now available for preview.

Microsoft launched Phi-3-vision, the latest addition to the Phi-3 family, a little while ago during the Build 2024 conference. The new multimodal SLM for on-device AI scenarios has a vast parameter count of 4.2 billion, capable of giving support for general visual reasoning tasks and others.
How good is Phi-3-vision, you may ask? A recently published paper suggests that it’s on par with other small models like Claude 3-haiku & Gemini 1.0 Pro. It puts Phi-3-vision against some of the popular AI benchmarks, like MMMU (college-level knowledge).
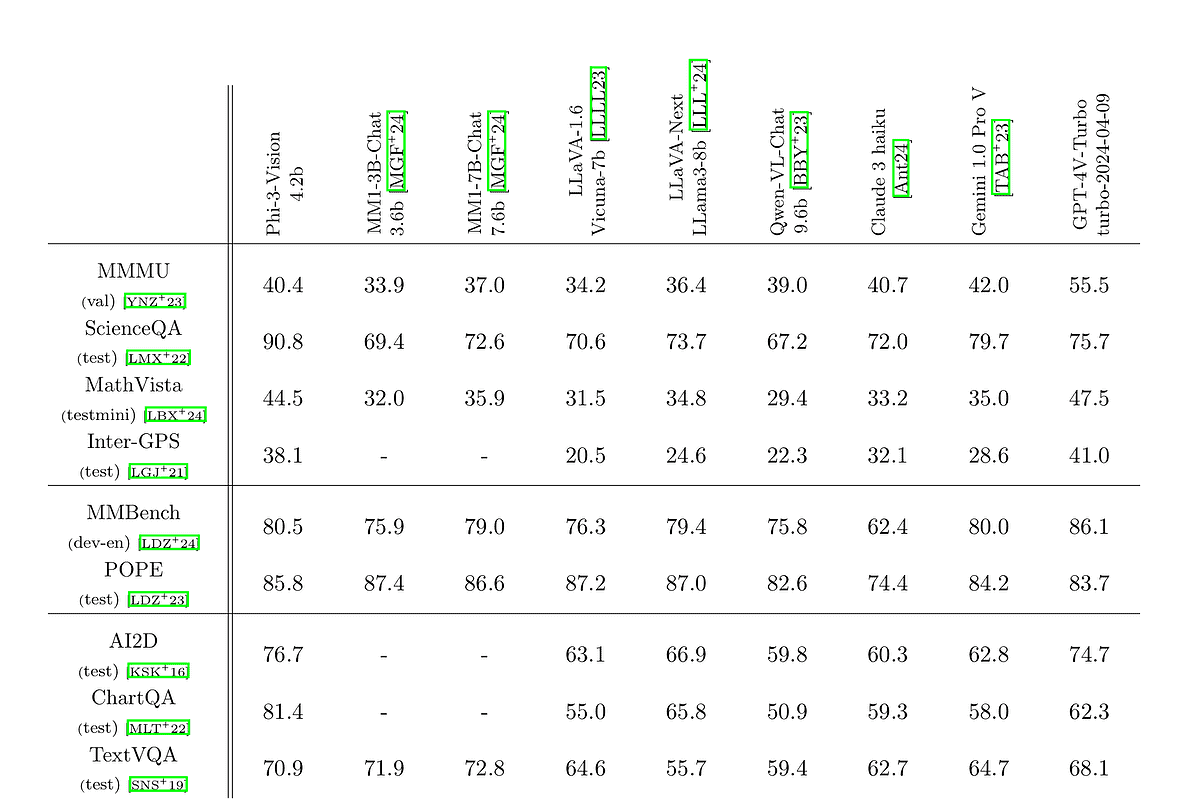
As you can see, in some cases, like ScienceQA, MathVista, and ChartQA for example, Phi-3-vision still remains superior to its competitors in smaller models.
Phi-3-vision, with 4.2 billion parameters, handles visual reasoning and chart/graph/table analysis. It can process images and text to provide text responses, such as answering questions about charts or images. Unlike larger models like DALL-E or Stable Diffusion, Phi-3-vision doesn’t generate images but understands and analyzes them.
Phi-3-vision itself is now available for preview. Additionally, Phi-3-mini and Phi-3-medium models are now available through Azure AI’s MaaS offering.
Besides Phi-3-vision, Microsoft also launched the Phi Silica model. It will be shipped as a part of Windows to power generative AI apps, which are cost & energy-friendly, and “custom-built for the NPUs in Copilot+ PCs.”
“With full NPU offload of prompt processing, the first token latency is at 650 tokens/second – and only costs about 1.5 Watts of power while leaving your CPU and GPU free for other computations,” Microsoft adds.
Read our disclosure page to find out how can you help MSPoweruser sustain the editorial team Read more
Improve this guide


User forum
0 messages