Microsoft proves that GPT-4 can beat Google Gemini Ultra using new prompting techniques
Last week, Google announced Gemini, its most capable and general model yet. Google Gemini model delivers state-of-the-art performance across many leading benchmarks. Google highlighted that the most capable Gemini Ultra model’s performance exceeds OpenAI GPT-4’s results on 30 of the 32 widely-used academic benchmarks used in large language model (LLM) research and development.
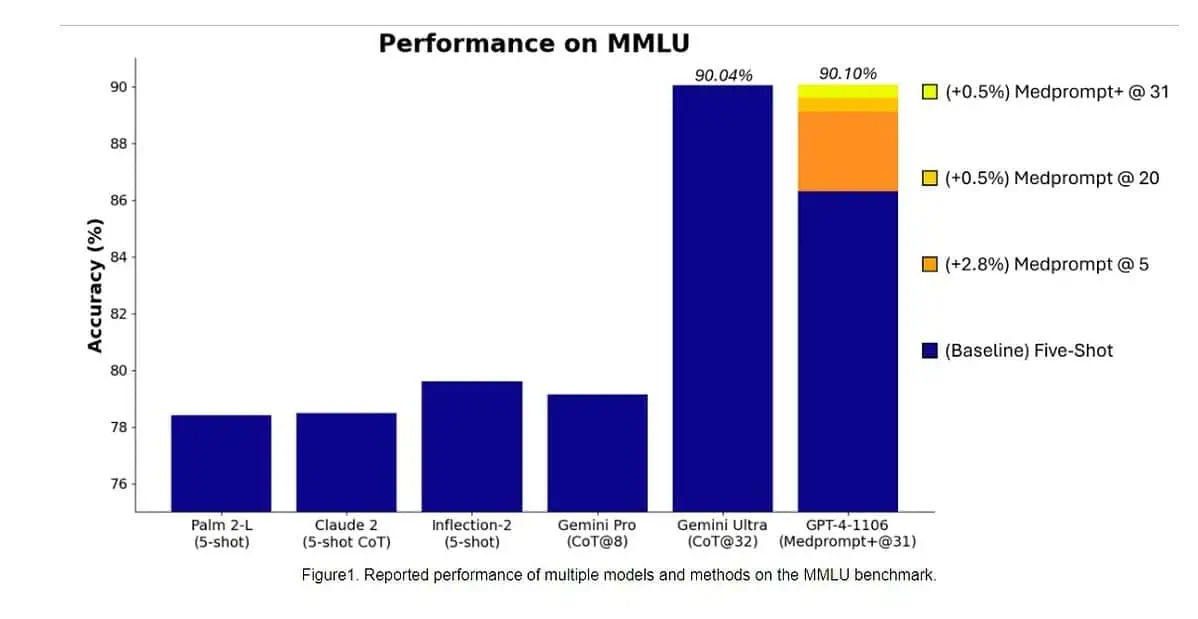
Specifically, Gemini Ultra became the first model to outperform human experts on MMLU (massive multitask language understanding) with 90% score, which uses a combination of 57 subjects such as math, physics, history, law, medicine and ethics for testing both world knowledge and problem-solving abilities.
Yesterday, Microsoft Research team revealed that OpenAI’s GPT-4 model can beat Google Gemini Ultra when new prompting techniques are used. Last month, Microsoft Research revealed Medprompt, a composition of several prompting strategies that greatly improves GPT-4’s performance and achieves state of the art results in the MultiMedQA suite. Microsoft has now applied the prompting techniques used in Medprompt for general domains as well. According to Microsoft, OpenAI’s GPT-4 model when used with a modified version of Medprompt achieves the highest score ever achieved on the complete MMLU. Yes, OpenAI GPT-4 can beat the upcoming Gemini Ultra model by just by using the prompting techniques. This shows that we have not yet reached the full potential of already released models like GPT-4.
Take a look at the benchmark comparison between GPT-4 (improved prompts) and Gemini Ultra models below.
| Benchmark | GPT-4 Prompt | GPT-4 Results | Gemini Ultra Results |
|---|---|---|---|
| MMLU | Medprompt+ | 90.10% | 90.04% |
| GSM8K | Zero-shot | 95.27% | 94.4% |
| MATH | Zero-shot | 68.42% | 53.2% |
| HumanEval | Zero-shot | 87.8% | 74.4% |
| BIG-Bench-Hard | Few-shot + CoT* | 89.0% | 83.6% |
| DROP | Zero-shot + CoT | 83.7% | 82.4% |
| HellaSwag | 10-shot** | 95.3% | 87.8% |
First, Microsoft applied the original Medprompt to GPT-4 to achieve the score of 89.1% in MMLU. Later, Microsoft increased the number of ensembled calls in Medprompt from five to 20, which lead to the increased score of 89.56%. Microsoft later extended Medprompt to Medprompt+ by adding a simpler prompting method and formulating a policy for deriving a final answer by integrating outputs from both the base Medprompt strategy and the simple prompts. This led GPT-4 reaching a record score of 90.10%. Microsoft Research team mentioned that Google Gemini team was also using similar prompting technique to achieve the record scores on MMLU.
You can learn more about prompting techniques Microsoft used to beat Gemini Ultra here.
Read our disclosure page to find out how can you help MSPoweruser sustain the editorial team Read more


Improve this guide



User forum
3 messages