Microsoft introducerer Phi-3-familien af modeller, der overgår andre modeller i sin klasse
![]() 2 min. Læs
2 min. Læs
![]() Udgivet den
Udgivet den
Del denne artikel

Forbedre denne vejledning
Læs vores oplysningsside for at finde ud af, hvordan du kan hjælpe MSPoweruser med at opretholde redaktionen Læs mere
Tilbage i december 2023 udgav Microsoft Phi-2 model med 2.7 milliarder parametre, der leverede state-of-the-art ydeevne blandt basissprogmodeller med mindre end 13 milliarder parametre. I de sidste fire måneder har adskillige andre modeller, der blev udgivet, klaret sig bedre end Phi-2. For nylig udgav Meta Llama-3-familien af modeller, der overgik alle de tidligere udgivne open source-modeller.
I aftes annoncerede Microsoft Research Phi-3-familien af modeller via en teknisk rapport. Der er tre modeller i Phi-3-familien:
- phi-3-mini (3.8B)
- phi-3-small (7B)
- phi-3-medium (14B)
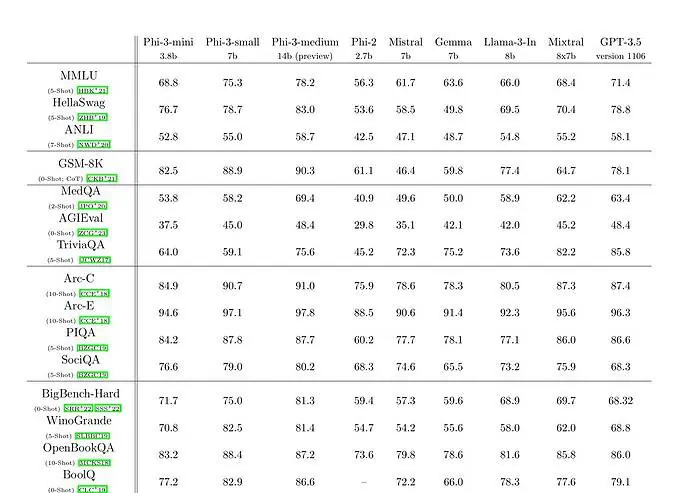
phi-3-mini med en sprogmodel på 3.8 milliarder parametre er trænet på 3.3 billioner tokens. Ifølge benchmarks slår phi-3-mini Mixtral 8x7B og GPT-3.5. Microsoft hævder, at denne model er lille nok til at blive installeret på en telefon. Microsoft brugte en opskaleret version af datasættet, som blev brugt til phi-2, sammensat af stærkt filtrerede webdata og syntetiske data. Ifølge Microsofts benchmark-resultater på Technical Paper opnår phi-3-small og phi-3-medium en imponerende MMLU-score på henholdsvis 75.3 og 78.2.
Med hensyn til LLM-kapaciteter, mens Phi-3-mini-modellen opnår et lignende niveau af sprogforståelse og ræsonnement, som meget større modeller, er den stadig fundamentalt begrænset af sin størrelse til visse opgaver. Modellen har ganske enkelt ikke kapacitet til at lagre omfattende faktuel viden, hvilket eksempelvis kan ses med lav ydeevne på TriviaQA. Vi mener dog, at denne svaghed kan løses ved at udvide med en søgemaskine.