Microsoft zveřejňuje analýzu hlavních příčin velkých problémů s přihlášením k Microsoft 365 z tohoto týdne
![]() 6 min. číst
6 min. číst
![]() Aktualizováno dne
Aktualizováno dne
Sdílejte tento článek

Vylepšete tuto příručku
Přečtěte si naši informační stránku a zjistěte, jak můžete pomoci MSPoweruser udržet redakční tým Dozvědět se více
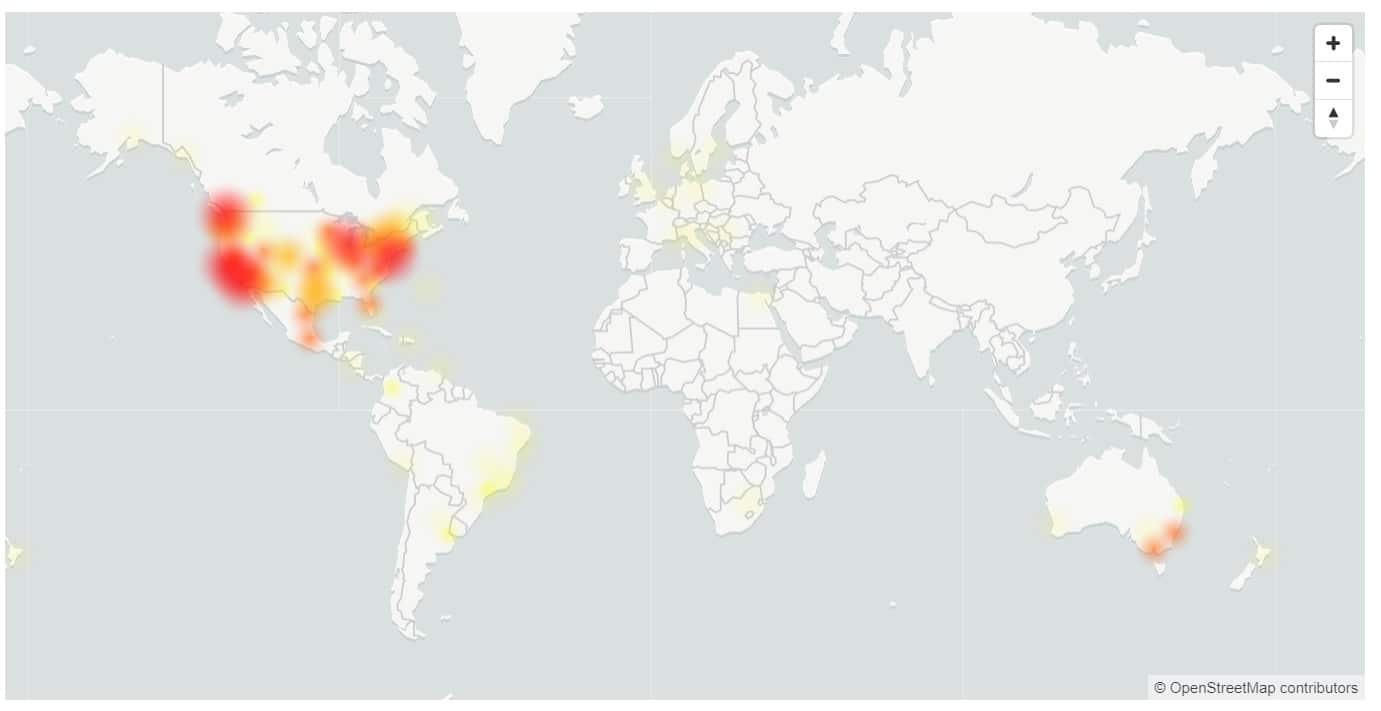
Tento týden jsme měli téměř 5 hodin dlouhý výpadek pro Microsoft 365, s uživateli, kteří se nemohou přihlásit k více službám, včetně OneDrive a Microsoft Teams.
Dnes Společnost Microsoft zveřejnila analýzu kořenové příčiny problému, která byla podle Microsoftu způsobena aktualizací služby, která měla cílit na interní ověřovací testovací kruh, ale místo toho byla nasazena přímo do produkčního prostředí Microsoftu kvůli latentní chybě kódu v systému bezpečného nasazení služby Azure AD (SDP).
Microsoft uvádí, že mezi přibližně 21:25 UTC 28. září 2020 a 00:23 UTC 29. září 2020 zákazníci zaznamenali chyby při provádění operací ověřování pro všechny aplikace a služby Microsoftu a třetích stran, které jsou závislé na Azure Active Directory (Azure AD ) pro ověření. Problém byl úplně zmírněn pro všechny do 2:25 následujícího dne.
Nejvíce zasaženy byly USA a Austrálie, přičemž pouze 17 % uživatelů v USA se dokázalo úspěšně přihlásit.
Problém byl umocněn tím, že Microsoft nemohl vrátit aktualizaci kvůli latentní chybě v jejich systému SDP, která poškozovala metadata nasazení, což znamená, že aktualizace musela být ručně vrácena zpět.
Společnost Microsoft se omluvila dotčeným zákazníkům a uvedla, že nadále podniká kroky ke zlepšení platformy Microsoft Azure a jejich procesů, aby zajistila, že k takovým incidentům v budoucnu nedochází. Jeden z plánovaných kroků zahrnuje použití další ochrany na back-endový SDP systém služby Azure AD, aby se zabránilo třídě identifikovaných problémů.
Přečtěte si celou analýzu níže:
RCA – Chyby ověřování napříč více službami Microsoft a integrovanými aplikacemi Azure Active Directory (ID sledování SM79-F88)
Shrnutí dopadu: Mezi přibližně 21:25 UTC 28. září 2020 a 00:23 UTC 29. září 2020 se zákazníci mohli setkat s chybami při provádění operací ověřování pro všechny aplikace a služby Microsoftu a třetích stran, které jsou závislé na Azure Active Directory (Azure AD). pro ověření. Ovlivněny byly také aplikace využívající Azure AD B2C k ověřování.
Uživatelé, kteří ještě nebyli ověřeni pro cloudové služby pomocí Azure AD, měli větší pravděpodobnost problémů a mohli zaznamenat více selhání požadavků na ověření odpovídající průměrným číslům dostupnosti uvedeným níže. Ty byly agregovány pro různé zákazníky a pracovní zátěže.
- Evropa: 81% úspěšnost po dobu trvání incidentu.
- Amerika: 17% úspěšnost po dobu trvání incidentu, zlepšení na 37% těsně před zmírněním.
- Asie: 72% úspěšnost v prvních 120 minutách incidentu. S nástupem špičkového provozu v pracovní době klesla dostupnost na nejnižší hodnotu na 32 %.
- Austrálie: 37% úspěšnost po dobu trvání incidentu.
Služba byla obnovena do normální provozní dostupnosti pro většinu zákazníků do 00:23 UTC dne 29. září 2020, zaznamenali jsme však zřídka selhávání požadavků na ověření, které mohlo mít dopad na zákazníky až do 02:25 UTC.
Uživatelé, kteří se ověřili před začátkem dopadu, měli menší pravděpodobnost problémů v závislosti na aplikacích nebo službách, ke kterým přistupovali.
Zavedená opatření odolnosti chrání služby Managed Identities pro virtuální počítače, sady škálování virtuálních strojů a služby Azure Kubernetes s průměrnou dostupností 99.8 % po celou dobu trvání incidentu.
Příčina: 28. září ve 21:25 UTC byla nasazena aktualizace služby zaměřená na interní ověřovací testovací kruh, což způsobilo selhání při spuštění v backendových službách Azure AD. Latentní defekt kódu v systému procesu bezpečného nasazení (SDP) backendové služby Azure AD způsobil, že se to nasadilo přímo do našeho produkčního prostředí, čímž se obešel náš normální proces ověřování.
Azure AD je navržena jako geograficky distribuovaná služba nasazená v konfiguraci aktivní-aktivní s více oddíly napříč více datovými centry po celém světě, postavená s hranicemi izolace. Normálně se změny zpočátku zaměřují na ověřovací kruh, který neobsahuje žádná zákaznická data, následuje vnitřní kruh, který obsahuje pouze uživatele společnosti Microsoft, a nakonec na naše produkční prostředí. Tyto změny jsou nasazovány ve fázích v pěti prstencích během několika dní.
V tomto případě se systému SDP nepodařilo správně zaměřit ověřovací testovací kruh kvůli latentní chybě, která ovlivnila schopnost systému interpretovat metadata nasazení. V důsledku toho byly všechny prsteny zaměřeny současně. Nesprávné nasazení způsobilo snížení dostupnosti služby.
Během několika minut po dopadu jsme podnikli kroky k vrácení změny pomocí automatizovaných systémů vrácení zpět, které by za normálních okolností omezily trvání a závažnost dopadu. Latentní defekt v našem systému SDP však poškodil metadata nasazení a museli jsme se uchýlit k ručním procesům vrácení zpět. Tím se výrazně prodloužil čas na zmírnění problému.
Zmírnění: Naše monitorování zjistilo zhoršení služby během několika minut od počátečního dopadu a okamžitě jsme zahájili odstraňování problémů. Byly provedeny následující zmírňující činnosti:
- Náraz začal ve 21:25 UTC a během 5 minut naše monitorování zjistilo nezdravý stav a okamžitě bylo zahájeno inženýrství.
- Během následujících 30 minut byla souběžně s řešením problému provedena řada kroků s cílem minimalizovat dopad na zákazníky a urychlit zmírnění. To zahrnovalo proaktivní škálování některých služeb Azure AD, aby zvládly očekávanou zátěž, jakmile by bylo aplikováno zmírnění, a selhání určitých úloh v záložním systému Azure AD Authentication.
- Ve 22:02 UTC jsme zjistili hlavní příčinu, zahájili nápravu a spustili naše automatické mechanismy vrácení.
- Automatické vrácení se nezdařilo kvůli poškození metadat SDP. Ve 22:47 UTC jsme zahájili proces ruční aktualizace konfigurace služby, která obchází systém SDP, a celá operace byla dokončena do 23:59 UTC.
- Do 00:23 UTC se dostatek instancí backendové služby vrátilo do zdravého stavu, aby dosáhlo normálních provozních parametrů služby.
- Všechny servisní instance se zbytkovým dopadem byly obnoveny do 02:25 UTC.
Další kroky: Upřímně se omlouváme za dopad na dotčené zákazníky. Neustále podnikáme kroky ke zlepšení platformy Microsoft Azure a našich procesů, abychom zajistili, že k takovým incidentům v budoucnu nedochází. V tomto případě to zahrnuje (ale není omezeno na) následující:
Již jsme dokončili
- Opravena chyba latentního kódu v backendovém systému SDP Azure AD.
- Opraven stávající systém vrácení zpět, aby bylo možné obnovit poslední známá dobrá metadata na ochranu před poškozením.
- Rozšiřte rozsah a frekvenci cvičení pro návrat zpět.
Zbývající kroky zahrnují
- Aplikujte další ochrany na backendový systém SDP služby Azure AD, abyste zabránili třídě problémů, které jsou zde uvedeny.
- Urychlete zavádění záložního ověřovacího systému Azure AD do všech klíčových služeb jako nejvyšší prioritu, abyste v budoucnu výrazně snížili dopad podobného typu problému.
- Integrujte scénáře Azure AD do kanálu automatizované komunikace, který do 15 minut od dopadu odešle počáteční komunikaci postiženým zákazníkům.
Poskytnout zpětnou vazbu: Pomozte nám vylepšit komunikaci se zákazníky Azure tím, že se zúčastníte našeho průzkumu: https://aka.ms/AzurePIRSurvey
přes ZDNet