微软证明 GPT-4 可以使用新的提示技术击败 Google Gemini Ultra
![]() 2分钟读
2分钟读
![]() 发表于
发表于
分享此文章

改进本指南
上周,谷歌宣布 双子座,它迄今为止最强大和通用的模型。 Google Gemini 模型在许多领先的基准测试中提供了最先进的性能。 谷歌强调,在大型语言模型(LLM)研究和开发中使用的 4 个广泛使用的学术基准中,最强大的 Gemini Ultra 模型的性能超过了 OpenAI GPT-30 中 32 个的结果。
具体来说,Gemini Ultra 成为第一个在 MMLU(大规模多任务语言理解)上超越人类专家的模型,得分为 90%,该模型结合了数学、物理、历史、法律、医学和伦理学等 57 个科目来测试世界知识和解决问题的能力。
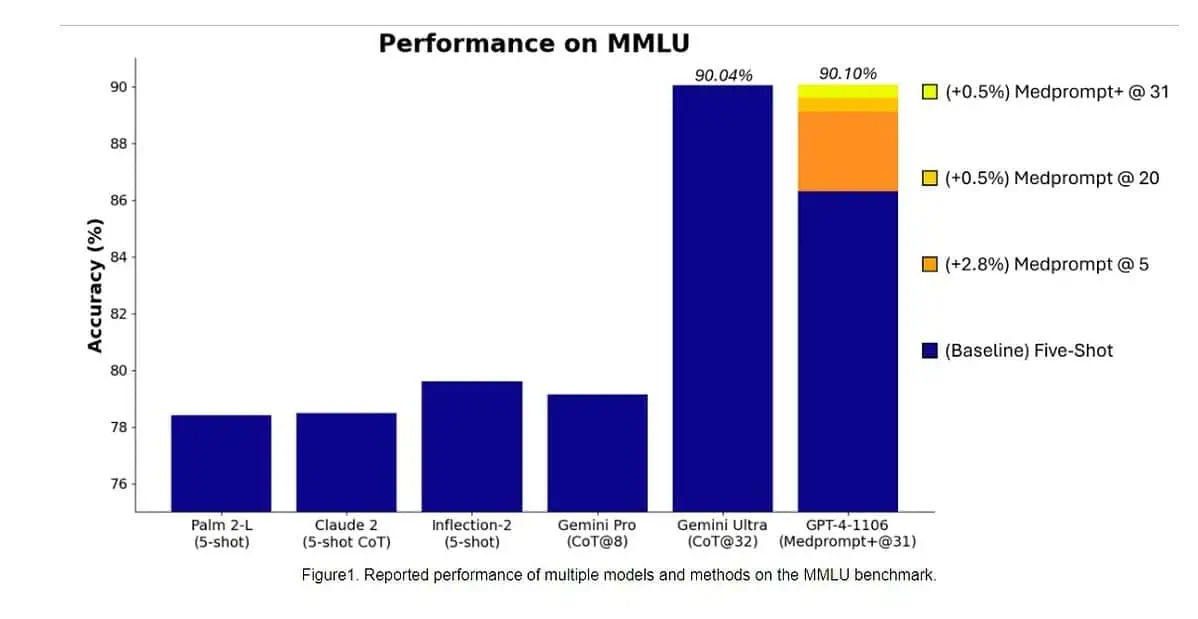
昨天,微软研究团队 发现 当使用新的提示技术时,OpenAI 的 GPT-4 模型可以击败 Google Gemini Ultra。 上个月,微软研究院透露 梅德提示,由多种提示策略组成,极大地提高了 GPT-4 的性能并在 MultiMedQA 套件中实现了最先进的结果。 Microsoft 现在也将 Medprompt 中使用的提示技术应用于一般领域。 据微软称,OpenAI 的 GPT-4 模型与 Medprompt 的修改版本一起使用时,在完整的 MMLU 上取得了有史以来的最高分。 是的,OpenAI GPT-4 只需使用提示技术就可以击败即将推出的 Gemini Ultra 模型。 这表明我们尚未充分发挥 GPT-4 等已发布模型的全部潜力。
看看下面的 GPT-4(改进的提示)和 Gemini Ultra 型号之间的基准比较。
| 基准 | GPT-4 提示 | GPT-4 结果 | 双子座超结果 |
|---|---|---|---|
| 百万美元 | 医疗提示+ | 90.10% | 90.04% |
| GSM8K | 零射击 | 95.27% | 94.4% |
| 数学 | 零射击 | 68.42% | 53.2% |
| 人类评估 | 零射击 | 87.8% | 74.4% |
| 大板凳硬 | 少量射击 + CoT* | 89.0% | 83.6% |
| 下降 | 零射击+CoT | 83.7% | 82.4% |
| 海拉斯瓦格 | 10 发** | 95.3% | 87.8% |
首先,微软将原始的Medprompt应用到GPT-4上,在MMLU中取得了89.1%的分数。 后来,微软将 Medprompt 中的集成调用数量从 20 个增加到 89.56 个,得分提高了 4%。 Microsoft 后来将 Medprompt 扩展为 Medprompt+,添加了更简单的提示方法,并制定了通过集成基本 Medprompt 策略和简单提示的输出来得出最终答案的策略。 这使得 GPT-90.10 达到了创纪录的 XNUMX% 分数。 微软研究团队提到,谷歌Gemini团队也使用类似的提示技术在MMLU上取得了记录分数。
您可以了解更多有关 Microsoft 用于击败 Gemini Ultra 的提示技术 相关信息.