认识微软 DeepSpeed,一个可以训练海量 100 亿参数模型的新深度学习库
![]() 2分钟读
2分钟读
![]() 更新
更新
分享此文章

改进本指南
微软研究院今天发布了 DeepSpeed,这是一个新的深度学习优化库,可以训练海量 100 亿参数模型。 在 AI 中,您需要拥有更大的自然语言模型以获得更好的准确性。 但是训练更大的自然语言模型非常耗时,并且与之相关的成本非常高。 微软声称新的 DeepSpeed 深度学习库提高了速度、成本、规模和可用性。
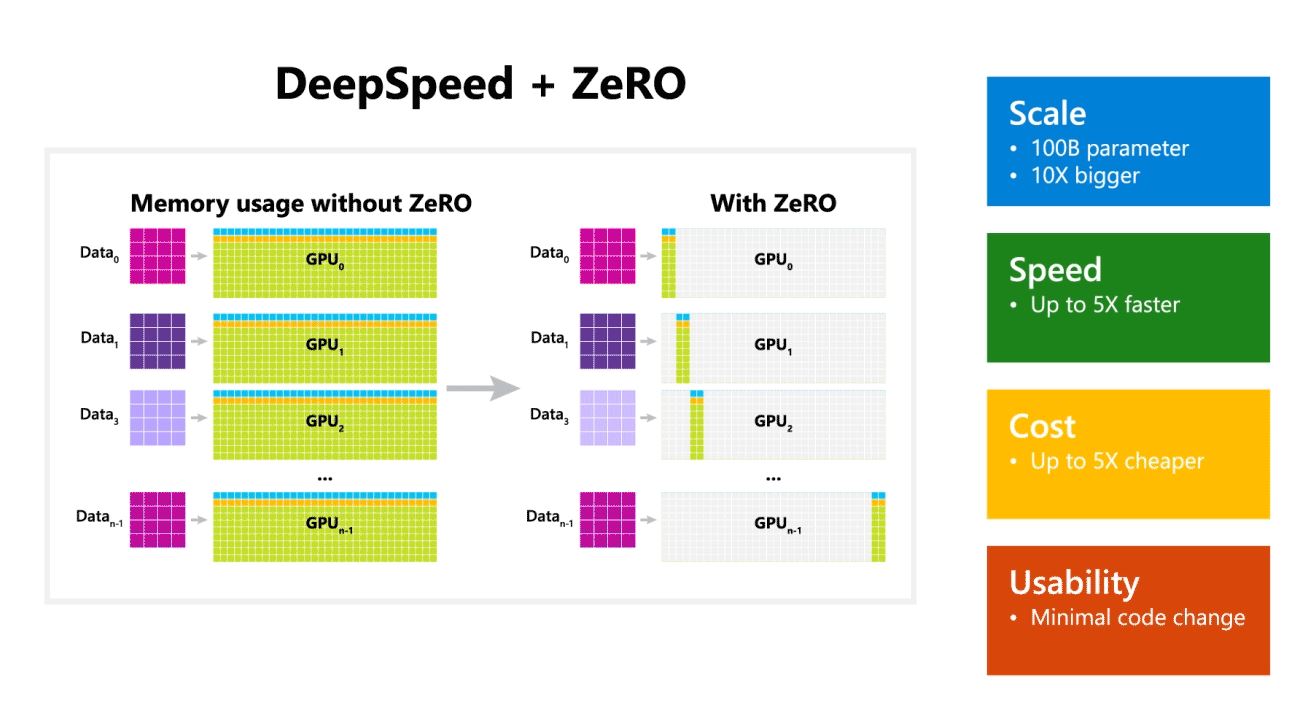
微软还提到,DeepSpeed 支持具有多达 100 亿个参数模型的语言模型,它包括 ZeRO(零冗余优化器),这是一种并行优化器,可减少模型和数据并行所需的资源,同时增加可训练的参数数量. 微软研究人员使用 DeepSpeed 和 ZeRO 开发了新的图灵自然语言生成 (Turing-NLG),这是最大的语言模型,具有 17 亿个参数。
DeepSpeed 的亮点:
- 鳞片:OpenAI GPT-2、NVIDIA Megatron-LM 和 Google T5 等最先进的大型模型的大小分别为 1.5 亿、8.3 亿和 11 亿个参数。 DeepSpeed 中的 ZeRO 第一阶段提供系统支持,可运行多达 100 亿个参数的模型,大 10 倍。
- 迅速的:我们观察到各种硬件的吞吐量比现有技术高出五倍。 在具有低带宽互连(没有 NVIDIA NVLink 或 Infiniband)的 NVIDIA GPU 集群上,对于具有 3.75 亿个参数的标准 GPT-2 模型,与单独使用 Megatron-LM 相比,我们实现了 1.5 倍的吞吐量提升。 在具有高带宽互连的 NVIDIA DGX-2 集群上,对于 20 到 80 亿个参数的模型,我们的速度提高了三到五倍。
- 价格:提高的吞吐量可以转化为显着降低的培训成本。 例如,要训练一个具有 20 亿个参数的模型,DeepSpeed 需要的资源要少三倍。
- 可用性:只需要更改几行代码即可使 PyTorch 模型使用 DeepSpeed 和 ZeRO。 与当前的模型并行库相比,DeepSpeed 不需要重新设计代码或重构模型。
微软正在开源 DeepSpeed 和 ZeRO,你可以看看 这里是GitHub。
Sumber: 微软