พบกับ Microsoft DeepSpeed ไลบรารี่การเรียนรู้เชิงลึกใหม่ที่สามารถฝึกโมเดลพารามิเตอร์ขนาดใหญ่กว่า 100 พันล้านตัว
![]() 2 นาที. อ่าน
2 นาที. อ่าน
![]() อัปเดตเมื่อวันที่
อัปเดตเมื่อวันที่
แชร์บทความนี้

ปรับปรุงคู่มือนี้
อ่านหน้าการเปิดเผยข้อมูลของเราเพื่อดูว่าคุณจะช่วย MSPoweruser รักษาทีมบรรณาธิการได้อย่างไร อ่านเพิ่มเติม
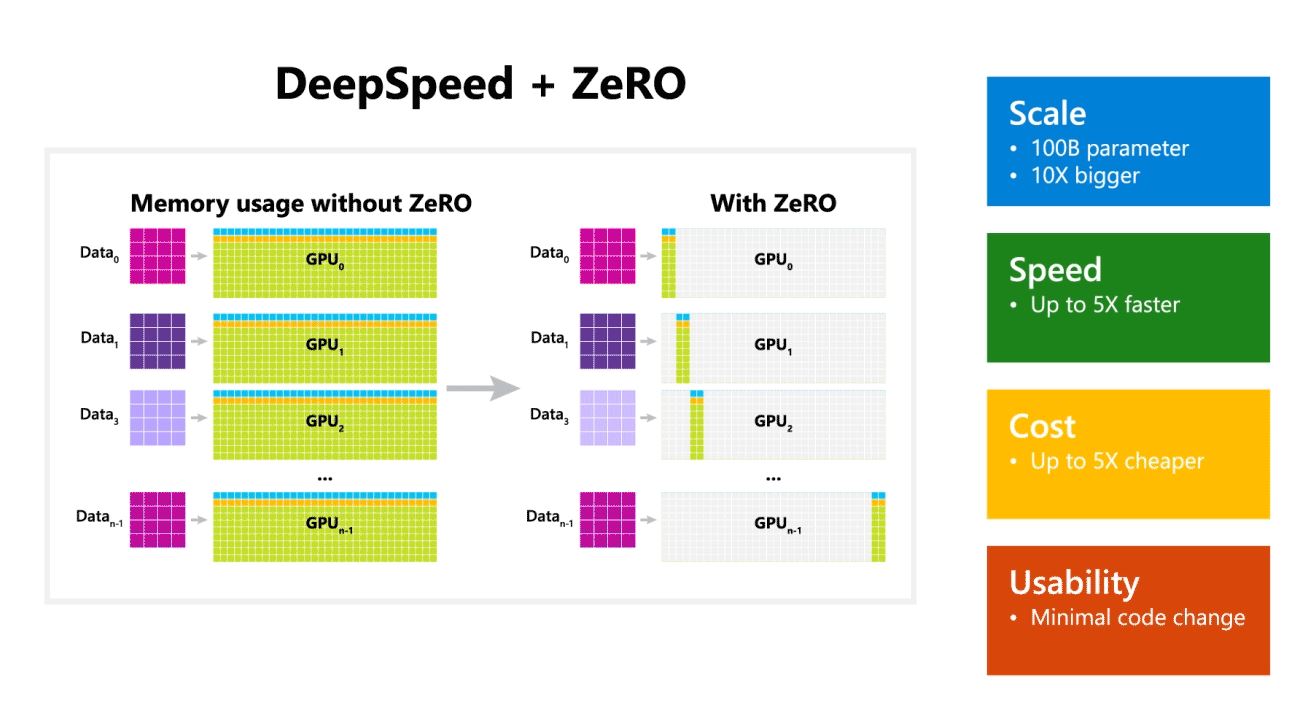
Microsoft Research ประกาศเปิดตัว DeepSpeed ซึ่งเป็นไลบรารีการเพิ่มประสิทธิภาพการเรียนรู้เชิงลึกแบบใหม่ที่สามารถฝึกโมเดลขนาดใหญ่ที่มีพารามิเตอร์หลายแสนล้านพารามิเตอร์ ใน AI คุณต้องมีโมเดลภาษาธรรมชาติที่ใหญ่ขึ้นเพื่อความแม่นยำที่ดีขึ้น แต่การฝึกโมเดลภาษาธรรมชาติที่ใหญ่ขึ้นนั้นใช้เวลานานและค่าใช้จ่ายที่เกี่ยวข้องนั้นสูงมาก Microsoft อ้างว่าไลบรารี DeepSpeed deep-learning ใหม่ช่วยเพิ่มความเร็ว ต้นทุน ขนาดและความสามารถในการใช้งาน
Microsoft ยังกล่าวอีกว่า DeepSpeed เปิดใช้งานโมเดลภาษาที่มีโมเดลพารามิเตอร์มากถึง 100 พันล้านตัว และรวมถึง ZeRO (Zero Redundancy Optimizer) ซึ่งเป็นเครื่องมือเพิ่มประสิทธิภาพแบบขนานที่ลดทรัพยากรที่จำเป็นสำหรับแบบจำลองและข้อมูลคู่ขนานในขณะที่เพิ่มจำนวนพารามิเตอร์ที่สามารถฝึกได้ . นักวิจัยของ Microsoft ได้ใช้ DeepSpeed และ ZeRO พัฒนา Turing Natural Language Generation (Turing-NLG) ซึ่งเป็นโมเดลภาษาที่ใหญ่ที่สุดที่มีพารามิเตอร์ 17 พันล้านตัว
ไฮไลท์ของ DeepSpeed:
- ขนาด: โมเดลขนาดใหญ่ที่ล้ำสมัย เช่น OpenAI GPT-2, NVIDIA Megatron-LM และ Google T5 มีขนาด 1.5 พันล้าน 8.3 พันล้าน และ 11 พันล้านพารามิเตอร์ตามลำดับ ZeRO สเตจที่ 100 ใน DeepSpeed ให้การสนับสนุนระบบเพื่อรันโมเดลที่มีพารามิเตอร์สูงถึง 10 พันล้านพารามิเตอร์ ใหญ่กว่า XNUMX เท่า
- ความเร็ว: เราสังเกตทรูพุตที่สูงกว่าความทันสมัยของฮาร์ดแวร์ต่างๆ ถึงห้าเท่า บนคลัสเตอร์ NVIDIA GPU ที่มีการเชื่อมต่อแบนด์วิดท์ต่ำ (ไม่มี NVIDIA NVLink หรือ Infiniband) เราได้รับการปรับปรุงปริมาณงาน 3.75 เท่า เมื่อเทียบกับการใช้ Megatron-LM เพียงอย่างเดียวสำหรับรุ่น GPT-2 มาตรฐานที่มีพารามิเตอร์ 1.5 พันล้านรายการ บนคลัสเตอร์ NVIDIA DGX-2 ที่มีการเชื่อมต่อระหว่างแบนด์วิดท์สูง สำหรับรุ่นที่มีพารามิเตอร์ 20 ถึง 80 พันล้านพารามิเตอร์ เราเร็วขึ้นสามถึงห้าเท่า
- ราคา: สามารถแปลปริมาณงานที่ได้รับการปรับปรุงเพื่อลดต้นทุนการฝึกอบรมได้อย่างมาก ตัวอย่างเช่น ในการฝึกโมเดลที่มีพารามิเตอร์ 20 พันล้านตัว DeepSpeed ต้องใช้ทรัพยากรน้อยลงสามเท่า
- การใช้งาน: จำเป็นต้องเปลี่ยนโค้ดเพียงไม่กี่บรรทัดเพื่อให้โมเดล PyTorch ใช้ DeepSpeed และ ZeRO ได้ เมื่อเทียบกับไลบรารี Parallelism รุ่นปัจจุบัน DeepSpeed ไม่ต้องการการออกแบบโค้ดใหม่หรือการปรับโครงสร้างโมเดล
Microsoft เป็นโอเพ่นซอร์สทั้ง DeepSpeed และ ZeRO คุณสามารถตรวจสอบได้ ที่นี่ใน GitHub
ที่มา: ไมโครซอฟท์