Microsoft publicerar orsaksanalys för veckans stora Microsoft 365-inloggningsproblem
![]() 6 min. läsa
6 min. läsa
![]() Uppdaterad den
Uppdaterad den
Dela den här artikeln

Förbättra den här guiden
Läs vår informationssida för att ta reda på hur du kan hjälpa MSPoweruser upprätthålla redaktionen Läs mer
Den här veckan hade vi en nästan 5 timmar lång stilleståndstid för Microsoft 365, med användare som inte kan logga in på flera tjänster, inklusive OneDrive och Microsoft Teams.
I dag Microsoft publicerade en rotorsaksanalys av problemet, som Microsoft säger berodde på tjänstuppdatering som var tänkt att rikta in sig på en intern valideringstestring men som istället distribuerades direkt i Microsofts produktionsmiljö på grund av en latent koddefekt i Azure AD backend-tjänsten Safe Deployment Process (SDP)-systemet.
Microsoft säger att mellan cirka 21:25 UTC den 28 september 2020 och 00:23 UTC den 29 september 2020, stötte kunder på fel när de utförde autentiseringsåtgärder för alla Microsoft och tredjepartsapplikationer och tjänster som är beroende av Azure Active Directory (Azure AD ) för autentisering. Problemet var helt åtgärdat för alla först 2:25 nästa dag.
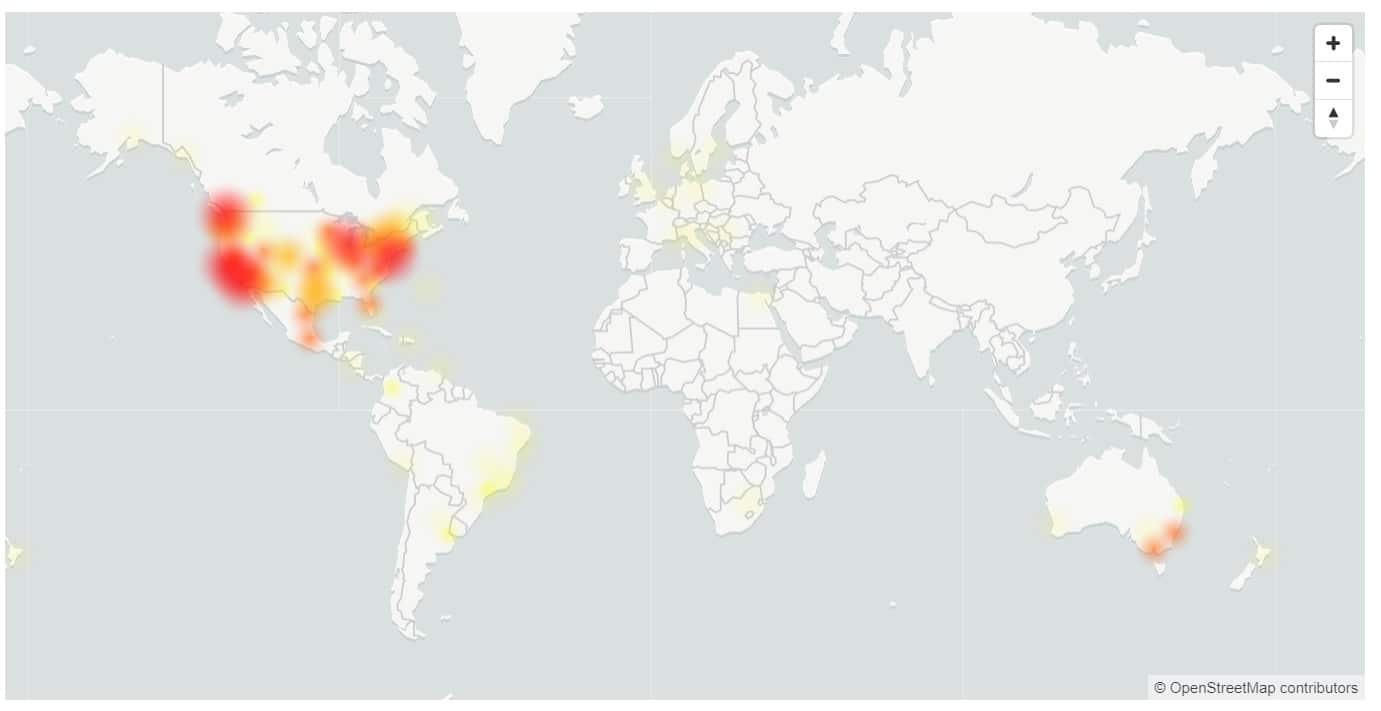
USA och Australien drabbades hårdast, med endast 17 % av användarna i USA som kunde logga in.
Problemet förvärrades av att Microsoft inte kunde återställa uppdateringen på grund av att den latenta defekten i deras SDP-system förstörde distributionens metadata, vilket innebar att uppdateringen måste återställas manuellt.
Microsoft bad om ursäkt till berörda kunder och säger att de fortsätter att vidta åtgärder för att förbättra Microsoft Azure-plattformen och deras processer för att säkerställa att sådana incidenter inte inträffar i framtiden. Ett av de planerade stegen inkluderar att tillämpa ytterligare skydd på Azure AD-tjänstens backend-SDP-system för att förhindra klassen av identifierade problem.
Läs hela analysen nedan:
RCA – Autentiseringsfel över flera Microsoft-tjänster och Azure Active Directory-integrerade applikationer (spårnings-ID SM79-F88)
Sammanfattning av påverkan: Mellan cirka 21:25 UTC den 28 september 2020 och 00:23 UTC den 29 september 2020 kan kunder ha stött på fel vid utförande av autentiseringsåtgärder för alla Microsoft och tredjepartsapplikationer och tjänster som är beroende av Azure Active Directory (Azure AD) för autentisering. Applikationer som använder Azure AD B2C för autentisering påverkades också.
Användare som inte redan var autentiserade för molntjänster med Azure AD var mer benägna att uppleva problem och kan ha sett flera autentiseringsbegäranden som motsvarar de genomsnittliga tillgänglighetssiffrorna som visas nedan. Dessa har aggregerats över olika kunder och arbetsbelastningar.
- Europa: 81 % framgång under hela incidenten.
- Amerika: 17 % framgång under hela incidenten, förbättrad till 37 % strax före åtgärden.
- Asien: 72 % framgång under de första 120 minuterna av incidenten. När topptrafiken på arbetstid började sjönk tillgängligheten till 32 % som lägst.
- Australien: 37 % framgång under hela incidenten.
Tjänsten återställdes till normal operativ tillgänglighet för majoriteten av kunderna kl. 00:23 UTC den 29 september 2020, men vi observerade sällsynta misslyckanden i autentiseringsbegäran som kan ha påverkat kunderna fram till 02:25 UTC.
Användare som hade autentiserats före effektstarttiden var mindre benägna att uppleva problem beroende på vilka applikationer eller tjänster de använde.
Resiliensåtgärder på plats skyddade Managed Identities-tjänster för virtuella maskiner, Virtual Machine Scale Sets och Azure Kubernetes Services med en genomsnittlig tillgänglighet på 99.8 % under hela incidenten.
Grundorsak: Den 28 september kl. 21:25 UTC distribuerades en tjänstuppdatering riktad mot en intern valideringstestring, vilket orsakade en krasch vid uppstart i Azure AD-backend-tjänsterna. En latent koddefekt i Azure AD backend-tjänsten Safe Deployment Process (SDP)-systemet gjorde att detta distribuerades direkt i vår produktionsmiljö, vilket kringgår vår normala valideringsprocess.
Azure AD är designad för att vara en geodistribuerad tjänst som distribueras i en aktiv-aktiv konfiguration med flera partitioner över flera datacenter runt om i världen, byggda med isoleringsgränser. Normalt är ändringar initialt inriktade på en valideringsring som inte innehåller några kunddata, följt av en inre ring som endast innehåller Microsoft-användare, och slutligen vår produktionsmiljö. Dessa förändringar distribueras i faser över fem ringar under flera dagar.
I det här fallet misslyckades SDP-systemet med att rikta in valideringstestringen korrekt på grund av en latent defekt som påverkade systemets förmåga att tolka distributionsmetadata. Följaktligen inriktades alla ringar samtidigt. Den felaktiga distributionen gjorde att tjänstens tillgänglighet försämrades.
Inom några minuter efter påverkan vidtog vi åtgärder för att återställa ändringen med hjälp av automatiska återställningssystem som normalt skulle ha begränsat varaktigheten och svårighetsgraden av påverkan. Den latenta defekten i vårt SDP-system hade dock förstört distributionens metadata, och vi var tvungna att tillgripa manuella återställningsprocesser. Detta förlängde avsevärt tiden för att mildra problemet.
begränsning: Vår övervakning upptäckte serviceförsämringen inom några minuter efter den första påverkan, och vi engagerade oss omedelbart för att initiera felsökning. Följande åtgärder vidtogs:
- Nedslaget började klockan 21:25 UTC, och inom 5 minuter upptäckte vår övervakning ett ohälsosamt tillstånd och ingenjören sattes omedelbart igång.
- Under de kommande 30 minuterna, samtidigt med felsökningen av problemet, vidtogs en rad steg för att försöka minimera kundens påverkan och påskynda minskningen. Detta inkluderade att proaktivt skala ut några av Azure AD-tjänsterna för att hantera förväntad belastning när en begränsning skulle ha tillämpats och att misslyckas över vissa arbetsbelastningar till ett backupsystem för Azure AD-autentisering.
- Klockan 22:02 UTC fastställde vi grundorsaken, började åtgärda och initierade våra automatiska återställningsmekanismer.
- Automatisk återställning misslyckades på grund av korruptionen av SDP-metadata. Klockan 22:47 UTC initierade vi processen för att manuellt uppdatera tjänstekonfigurationen som kringgår SDP-systemet, och hela operationen slutfördes 23:59 UTC.
- Vid 00:23 UTC återgick tillräckligt många backend-tjänsteinstanser till ett hälsosamt tillstånd för att nå normala tjänstoperativa parametrar.
- Alla serviceinstanser med kvarvarande påverkan återställdes 02:25 UTC.
Nästa steg: Vi ber uppriktigt om ursäkt för påverkan på berörda kunder. Vi vidtar kontinuerligt åtgärder för att förbättra Microsoft Azure-plattformen och våra processer för att säkerställa att sådana incidenter inte inträffar i framtiden. I det här fallet inkluderar detta (men är inte begränsat till) följande:
Vi har redan avslutat
- Fixade den latenta koddefekten i Azure AD-backend SDP-systemet.
- Fixade det befintliga återställningssystemet för att tillåta återställning av den senaste kända-bra metadata för att skydda mot korruption.
- Utöka omfattningen och frekvensen av återställningsövningar.
De återstående stegen inkluderar
- Tillämpa ytterligare skydd på Azure AD-tjänstens backend SDP-system för att förhindra den klass av problem som identifieras här.
- Påskynda lanseringen av Azure AD backup-autentiseringssystem till alla nyckeltjänster som en högsta prioritet för att avsevärt minska effekten av en liknande typ av problem i framtiden.
- Inbyggda Azure AD-scenarier till den automatiska kommunikationspipeline som publicerar initial kommunikation till berörda kunder inom 15 minuter efter påverkan.
Ge feedback: Hjälp oss att förbättra Azures kundkommunikationsupplevelse genom att svara på vår undersökning: https://aka.ms/AzurePIRSurvey
via ZDNet