Möt Microsoft DeepSpeed, ett nytt djupinlärningsbibliotek som kan träna enorma modeller med 100 miljarder parametrar
![]() 2 min. läsa
2 min. läsa
![]() Uppdaterad den
Uppdaterad den
Dela den här artikeln

Förbättra den här guiden
Läs vår informationssida för att ta reda på hur du kan hjälpa MSPoweruser upprätthålla redaktionen Läs mer
Microsoft Research tillkännagav idag DeepSpeed, ett nytt optimeringsbibliotek för djupinlärning som kan träna enorma modeller med 100 miljarder parametrar. I AI måste du ha större naturliga språkmodeller för bättre noggrannhet. Men att träna större naturliga språkmodeller är tidskrävande och kostnaderna förknippade med det är mycket höga. Microsoft hävdar att det nya DeepSpeed djupinlärningsbiblioteket förbättrar hastighet, kostnad, skalning och användbarhet.
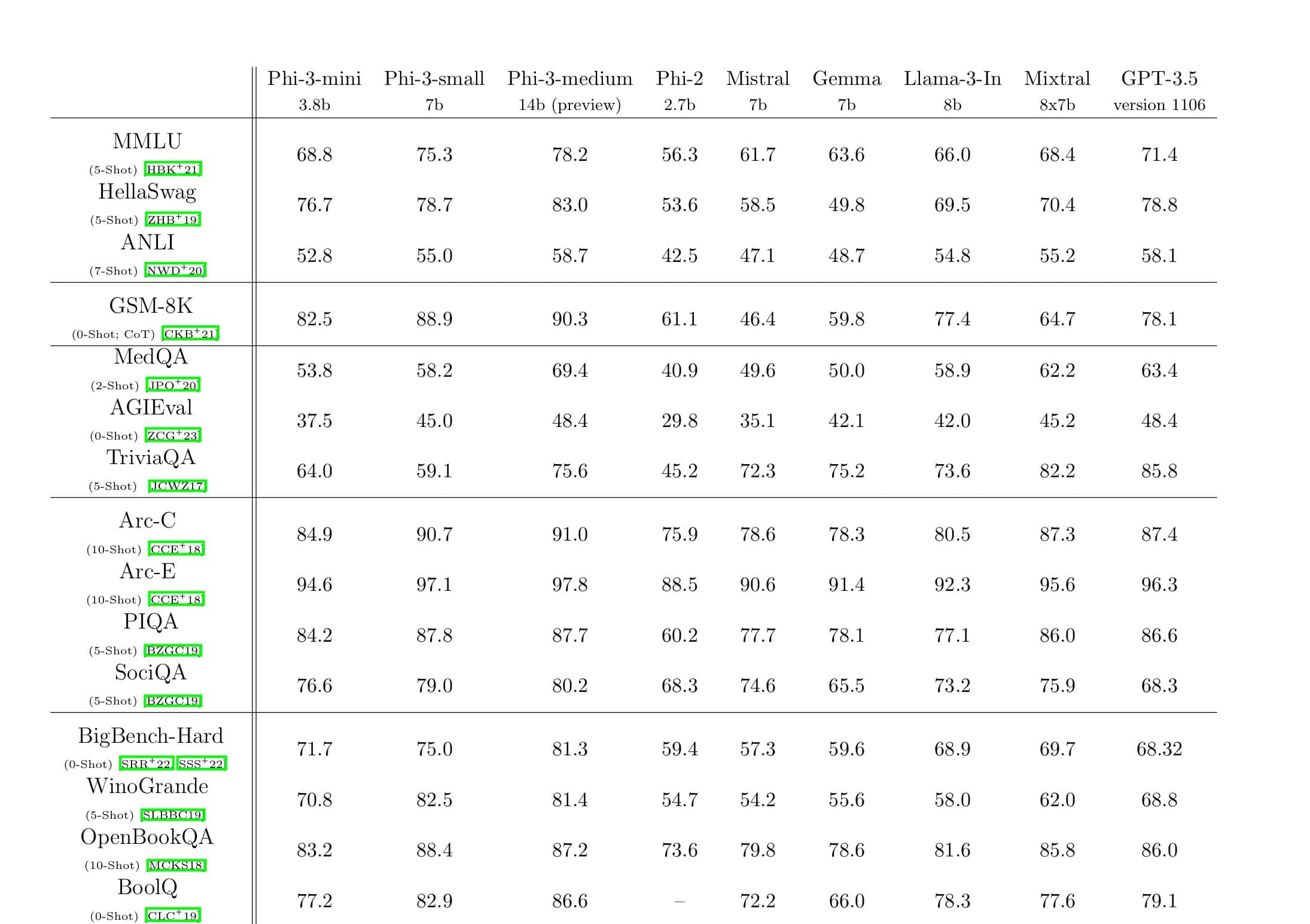
Microsoft nämnde också att DeepSpeed möjliggör språkmodeller med modeller med upp till 100 miljarder parametrar och den inkluderar ZeRO (Zero Redundancy Optimizer), en parallelliserad optimerare som minskar de resurser som behövs för modell- och dataparallellism samtidigt som man ökar antalet parametrar som kan tränas . Med hjälp av DeepSpeed och ZeRO har Microsoft Researchers utvecklat den nya Turing Natural Language Generation (Turing-NLG), den största språkmodellen med 17 miljarder parametrar.
Höjdpunkter i DeepSpeed:
- Skala: Toppmoderna stora modeller som OpenAI GPT-2, NVIDIA Megatron-LM och Google T5 har storlekar på 1.5 miljarder, 8.3 miljarder respektive 11 miljarder parametrar. ZeRO steg ett i DeepSpeed ger systemstöd för att köra modeller upp till 100 miljarder parametrar, 10 gånger större.
- Fart: Vi observerar upp till fem gånger högre genomströmning jämfört med den senaste tekniken för olika hårdvara. På NVIDIA GPU-kluster med sammankoppling med låg bandbredd (utan NVIDIA NVLink eller Infiniband) uppnår vi en 3.75x genomströmningsförbättring jämfört med att använda Megatron-LM enbart för en standard GPT-2-modell med 1.5 miljarder parametrar. På NVIDIA DGX-2-kluster med sammankoppling med hög bandbredd, för modeller med 20 till 80 miljarder parametrar, är vi tre till fem gånger snabbare.
- Pris: Förbättrad genomströmning kan översättas till avsevärt minskade utbildningskostnader. Till exempel, för att träna en modell med 20 miljarder parametrar, kräver DeepSpeed tre gånger färre resurser.
- användbarhet: Endast några rader med kodändringar behövs för att en PyTorch-modell ska kunna använda DeepSpeed och ZeRO. Jämfört med nuvarande modellparallellismbibliotek kräver DeepSpeed ingen kodomdesign eller modellrefaktorering.
Microsoft använder öppen källa för både DeepSpeed och ZeRO, du kan kolla in det här på GitHub.
Källa: Microsoft