Microsoft introducerar Phi-3-familjen av modeller som överträffar andra modeller i sin klass
![]() 2 min. läsa
2 min. läsa
![]() Publicerad den
Publicerad den
Dela den här artikeln

Förbättra den här guiden
Läs vår informationssida för att ta reda på hur du kan hjälpa MSPoweruser upprätthålla redaktionen Läs mer
Tillbaka i december 2023 släppte Microsoft Phi-2 modell med 2.7 miljarder parametrar som levererade toppmodern prestanda bland basspråksmodeller med mindre än 13 miljarder parametrar. Under de senaste fyra månaderna har flera andra modeller som släppts överträffat Phi-2. Nyligen släppte Meta Llama-3-familjen av modeller som överträffade alla tidigare släppta modeller med öppen källkod.
I går kväll tillkännagav Microsoft Research Phi-3-familjen av modeller via en teknisk rapport. Det finns tre modeller i Phi-3-familjen:
- phi-3-mini (3.8B)
- phi-3-small (7B)
- phi-3-medium (14B)
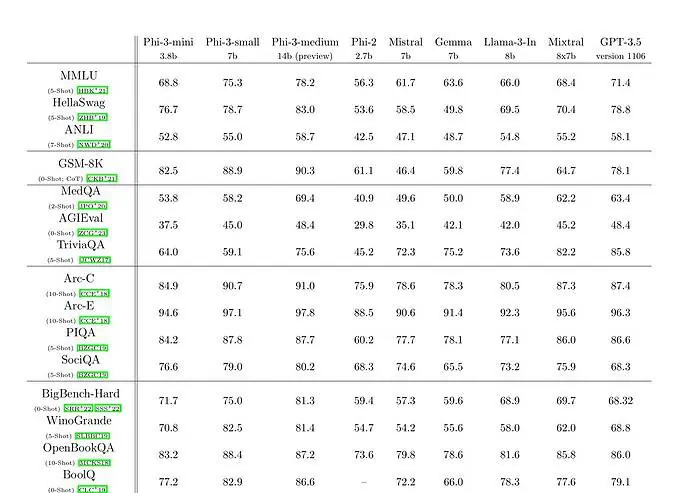
phi-3-mini med en språkmodell på 3.8 miljarder parametrar tränas på 3.3 biljoner tokens. Enligt riktmärken slår phi-3-mini Mixtral 8x7B och GPT-3.5. Microsoft hävdar att den här modellen är tillräckligt liten för att kunna användas på en telefon. Microsoft använde en uppskalad version av datamängden som användes för phi-2, sammansatt av kraftigt filtrerad webbdata och syntetisk data. Enligt Microsofts benchmarkresultat på Technical Paper, uppnår phi-3-small och phi-3-medium en imponerande MMLU-poäng på 75.3 respektive 78.2.
När det gäller LLM-kapacitet, medan Phi-3-mini-modellen uppnår en liknande nivå av språkförståelse och resonemangsförmåga som för mycket större modeller, är den fortfarande i grunden begränsad av sin storlek för vissa uppgifter. Modellen har helt enkelt inte kapacitet att lagra omfattande faktakunskap, vilket till exempel kan ses med låg prestanda på TriviaQA. Vi tror dock att denna svaghet kan lösas genom att utöka med en sökmotor.