Opera staje się pierwszą przeglądarką integrującą lokalne LLM
![]() 1 minuta. czytać
1 minuta. czytać
![]() Zaktualizowano na
Zaktualizowano na
Udostępnij ten artykuł

Ulepsz ten przewodnik
Przeczytaj naszą stronę z informacjami, aby dowiedzieć się, jak możesz pomóc MSPoweruser w utrzymaniu zespołu redakcyjnego Czytaj więcej
Kluczowe uwagi
- Użytkownicy mogą teraz bezpośrednio zarządzać zaawansowanymi modelami sztucznej inteligencji i uzyskiwać do nich dostęp na swoich urządzeniach, oferując większą prywatność i szybkość w porównaniu ze sztuczną inteligencją opartą na chmurze.
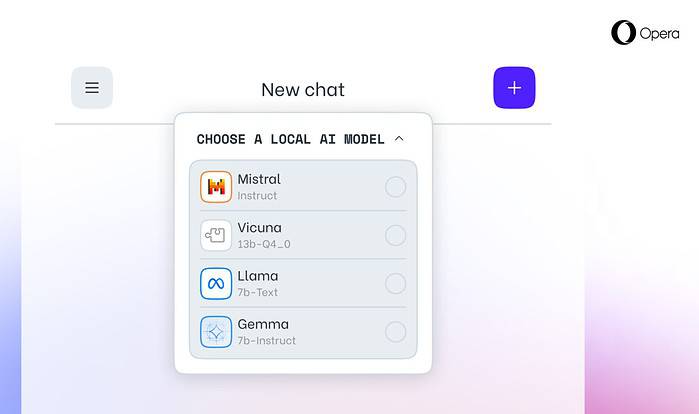
Opera dzisiaj ogłosił eksperymentalna obsługa 150 lokalnych modeli dużych języków (LLM) w przeglądarce programistycznej Opera One. Dzięki tej obsłudze użytkownicy mogą teraz bezpośrednio zarządzać zaawansowanymi modelami sztucznej inteligencji i uzyskiwać do nich dostęp na swoich urządzeniach, oferując większą prywatność i szybkość w porównaniu ze sztuczną inteligencją opartą na chmurze.
Większy wybór i prywatność dzięki lokalnym LLM
Integracja Opery obejmuje popularne LLM, takie jak Meta's Llama, Vicuna, Google Gemma, Mistral AI's Mixtral i wiele innych. Lokalne LLM eliminują potrzebę udostępniania danych serwerom, chroniąc prywatność użytkowników. Program zrzutów funkcji AI Opery umożliwia programistom wcześniejszy dostęp do tych nowatorskich funkcji.
Jak uzyskać dostęp do lokalnych LLM w Operze
Użytkownicy mogą odwiedzać Strona programisty Opery uaktualnić do wersji Opera One Developer, umożliwiając wybór i pobranie preferowanego lokalnego programu LLM. Choć wymagają miejsca na dysku (2–10 GB na model), lokalne rozwiązania LLM mogą zaoferować znaczny wzrost prędkości w porównaniu z alternatywami opartymi na chmurze, w zależności od sprzętu.
Zaangażowanie Opery w innowacje w zakresie sztucznej inteligencji
„Wprowadzenie w ten sposób lokalnych menedżerów LLM pozwala Operze rozpocząć odkrywanie sposobów budowania doświadczeń i know-how w szybko rozwijającej się lokalnej przestrzeni AI” – powiedział Krystian Kolondra, wiceprezes ds. przeglądarek i gier w Operze.