Poznaj Microsoft DeepSpeed, nową bibliotekę głębokiego uczenia, która może trenować ogromne modele o wartości 100 miliardów parametrów
![]() 2 minuta. czytać
2 minuta. czytać
![]() Zaktualizowano na
Zaktualizowano na
Udostępnij ten artykuł

Ulepsz ten przewodnik
Przeczytaj naszą stronę z informacjami, aby dowiedzieć się, jak możesz pomóc MSPoweruser w utrzymaniu zespołu redakcyjnego Czytaj więcej
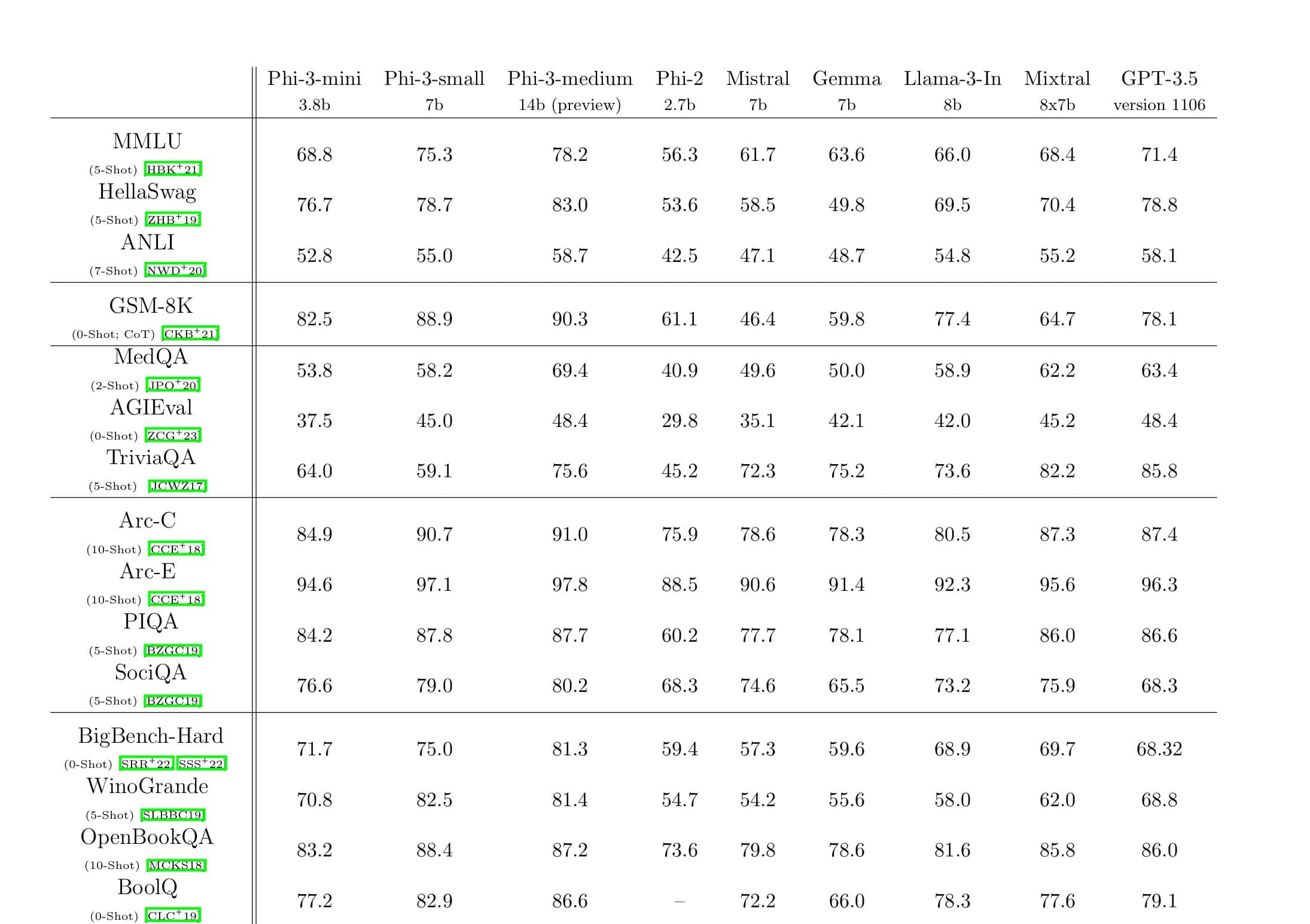
Firma Microsoft Research ogłosiła dziś DeepSpeed, nową bibliotekę do optymalizacji uczenia głębokiego, która może trenować ogromne modele o wartości 100 miliardów parametrów. W AI musisz mieć większe modele języka naturalnego, aby uzyskać większą dokładność. Jednak uczenie większych modeli języka naturalnego jest czasochłonne, a koszty z tym związane są bardzo wysokie. Microsoft twierdzi, że nowa biblioteka głębokiego uczenia DeepSpeed poprawia szybkość, koszt, skalę i użyteczność.
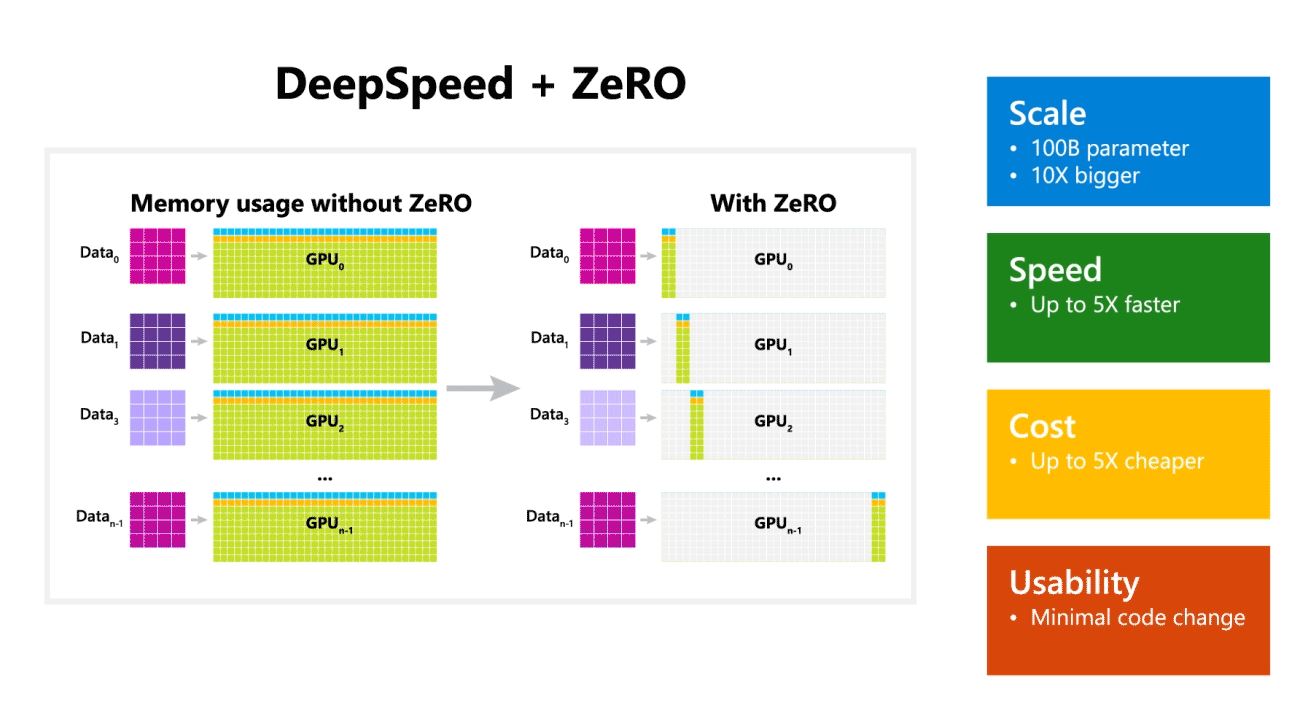
Microsoft wspomniał również, że DeepSpeed umożliwia modele językowe z modelami do 100 miliardów parametrów i obejmuje ZeRO (Zero Redundancy Optimizer), zrównoleglony optymalizator, który zmniejsza zasoby potrzebne do równoległości modeli i danych, jednocześnie zwiększając liczbę parametrów, które można trenować . Korzystając z technologii DeepSpeed i ZeRO, badacze firmy Microsoft opracowali nową generację języka naturalnego Turing (Turing-NLG), największy model języka z 17 miliardami parametrów.
Najważniejsze cechy DeepSpeed:
- Skala: Najnowocześniejsze duże modele, takie jak OpenAI GPT-2, NVIDIA Megatron-LM i Google T5, mają rozmiary odpowiednio 1.5 miliarda, 8.3 miliarda i 11 miliardów parametrów. Pierwszy etap Zero w DeepSpeed zapewnia wsparcie systemowe do uruchamiania modeli do 100 miliardów parametrów, 10 razy większych.
- Prędkość: Obserwujemy do pięciu razy wyższą przepustowość w porównaniu ze stanem techniki na różnych urządzeniach. W klastrach procesorów graficznych NVIDIA z połączeniem o niskiej przepustowości (bez NVIDIA NVLink lub Infiniband) osiągamy wzrost przepustowości o 3.75x w porównaniu z używaniem samego Megatron-LM dla standardowego modelu GPT-2 z 1.5 miliarda parametrów. W klastrach NVIDIA DGX-2 z interkonektem o dużej przepustowości, w przypadku modeli o parametrach od 20 do 80 miliardów, jesteśmy od trzech do pięciu razy szybsi.
- Koszty:: Większą przepustowość można przełożyć na znaczne zmniejszenie kosztów szkolenia. Na przykład, aby trenować model z 20 miliardami parametrów, DeepSpeed wymaga trzykrotnie mniej zasobów.
- Użyteczność: Wystarczy kilka linijek zmian w kodzie, aby umożliwić modelowi PyTorch korzystanie z DeepSpeed i ZERO. W porównaniu z obecnymi bibliotekami równoległości modeli, DeepSpeed nie wymaga przeprojektowania kodu ani refaktoryzacji modelu.
Microsoft jest otwarty na sourcing zarówno DeepSpeed, jak i ZeRO, możesz to sprawdzić tutaj na GitHub.
Źródło: Microsoft