Microsoft legger ut rotårsaksanalyse for denne ukens store Microsoft 365-påloggingsproblemer
![]() 6 min. lese
6 min. lese
![]() Oppdatert på
Oppdatert på
Del denne artikkelen

Forbedre denne veiledningen
Les vår avsløringsside for å finne ut hvordan du kan hjelpe MSPoweruser opprettholde redaksjonen Les mer
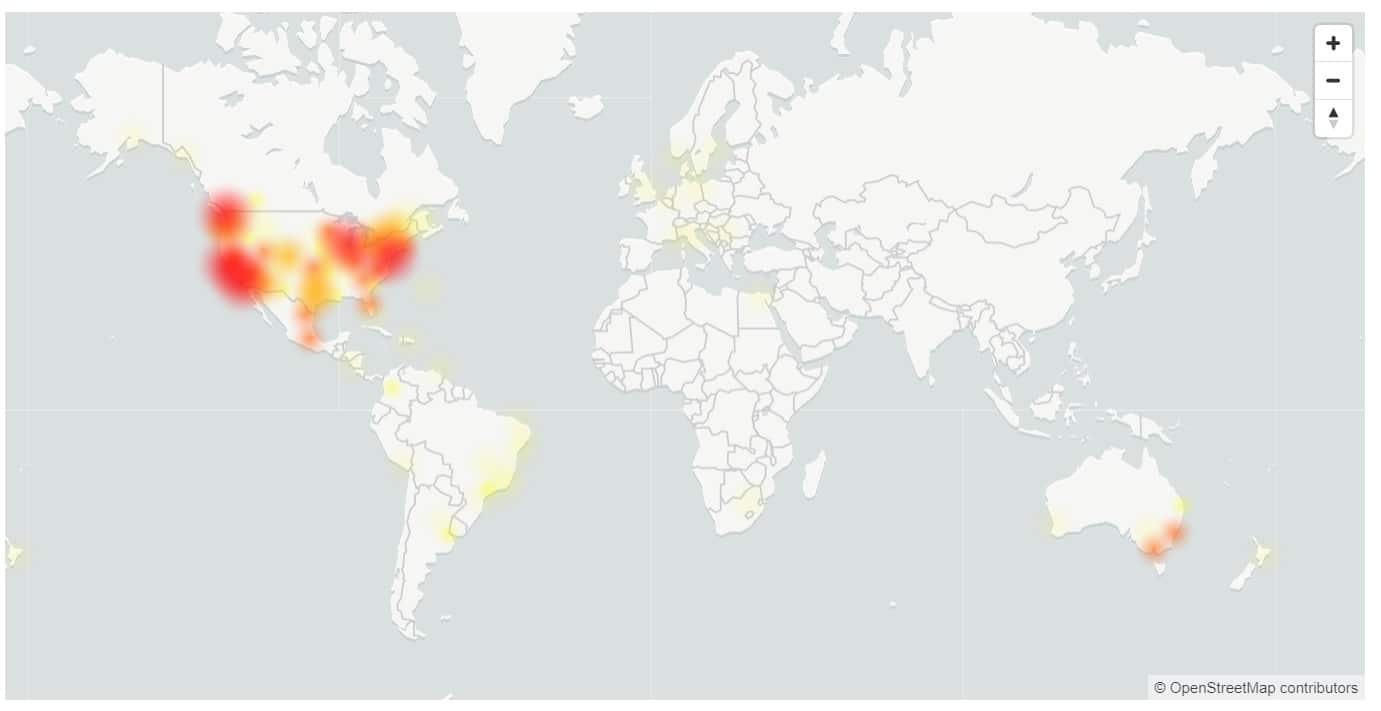
Denne uken hadde vi en nesten 5 timer lang nedetid for Microsoft 365, med brukere som ikke kan logge på flere tjenester, inkludert OneDrive og Microsoft Teams.
I dag Microsoft publiserte en rotårsaksanalyse av problemet, som Microsoft sier skyldtes tjenesteoppdatering som var ment å være rettet mot en intern valideringstestring, men som i stedet ble distribuert direkte inn i Microsofts produksjonsmiljø på grunn av en latent kodefeil i Azure AD backend-tjenesten Safe Deployment Process (SDP)-systemet.
Microsoft sier at mellom ca. 21:25 UTC den 28. september 2020 og 00:23 UTC den 29. september 2020, oppdaget kunder feil under utførelse av autentiseringsoperasjoner for alle Microsoft- og tredjepartsapplikasjoner og -tjenester som er avhengige av Azure Active Directory (Azure AD). ) for autentisering. Problemet var bare fullstendig løst for alle innen 2:25 neste dag.
USA og Australia ble hardest rammet, med bare 17 % av brukerne i USA som kunne logge på.
Problemet ble forsterket av at Microsoft ikke var i stand til å rulle tilbake oppdateringen på grunn av den latente defekten i deres SDP-system som korrupte distribusjonsmetadataene, noe som betyr at oppdateringen måtte rulles tilbake manuelt.
Microsoft ba om unnskyldning til berørte kunder og sier at de fortsetter å ta skritt for å forbedre Microsoft Azure-plattformen og deres prosesser for å sikre at slike hendelser ikke oppstår i fremtiden. Ett av de planlagte trinnene inkluderer å bruke ekstra beskyttelse på Azure AD-tjenestens backend SDP-system for å forhindre klassen med identifiserte problemer.
Les hele analysen nedenfor:
RCA – Autentiseringsfeil på tvers av flere Microsoft-tjenester og integrerte Azure Active Directory-applikasjoner (sporings-ID SM79-F88)
Sammendrag av innvirkning: Mellom ca. 21:25 UTC 28. september 2020 og 00:23 UTC 29. september 2020, kan kunder ha støtt på feil under utførelse av autentiseringsoperasjoner for alle Microsoft- og tredjepartsapplikasjoner og -tjenester som er avhengige av Azure Active Directory (Azure AD) for autentisering. Applikasjoner som bruker Azure AD B2C for autentisering ble også påvirket.
Brukere som ikke allerede var autentisert til skytjenester ved hjelp av Azure AD, var mer sannsynlig å oppleve problemer og kan ha sett flere autentiseringsforespørsler som tilsvarer de gjennomsnittlige tilgjengelighetstallene vist nedenfor. Disse er samlet på tvers av ulike kunder og arbeidsmengder.
- Europa: 81 % suksessrate for varigheten av hendelsen.
- Amerika: 17 % suksessrate for varigheten av hendelsen, forbedret til 37 % rett før avbøt.
- Asia: 72 % suksessrate i de første 120 minuttene av hendelsen. Etter hvert som høytrafikk i arbeidstiden startet, falt tilgjengeligheten til 32 % på det laveste.
- Australia: 37 % suksessrate for varigheten av hendelsen.
Tjenesten ble gjenopprettet til normal driftstilgjengelighet for flertallet av kundene innen kl. 00:23 UTC 29. september 2020, men vi observerte sjeldne feil med autentiseringsforespørsler som kan ha påvirket kunder frem til kl. 02:25 UTC.
Brukere som hadde autentisert seg før virkningens starttidspunkt var mindre sannsynlig å oppleve problemer avhengig av applikasjonene eller tjenestene de fikk tilgang til.
Motstandstiltak på plass beskyttede Managed Identities-tjenester for virtuelle maskiner, Virtual Machine Scale Sets og Azure Kubernetes Services med en gjennomsnittlig tilgjengelighet på 99.8 % gjennom hele varigheten av hendelsen.
Opprinnelig årsak: 28. september kl. 21:25 UTC ble en tjenesteoppdatering rettet mot en intern valideringstestring distribuert, noe som forårsaket et krasj ved oppstart i Azure AD-backend-tjenestene. En latent kodefeil i Azure AD-backend-tjenesten Safe Deployment Process (SDP)-systemet førte til at dette ble distribuert direkte inn i produksjonsmiljøet vårt, og gikk utenom vår vanlige valideringsprosess.
Azure AD er designet for å være en geodistribuert tjeneste distribuert i en aktiv-aktiv konfigurasjon med flere partisjoner på tvers av flere datasentre rundt om i verden, bygget med isolasjonsgrenser. Normalt er endringer i utgangspunktet rettet mot en valideringsring som ikke inneholder kundedata, etterfulgt av en indre ring som kun inneholder Microsoft-brukere, og til slutt vårt produksjonsmiljø. Disse endringene distribueres i faser over fem ringer over flere dager.
I dette tilfellet klarte ikke SDP-systemet å målrette valideringstestringen riktig på grunn av en latent defekt som påvirket systemets evne til å tolke distribusjonsmetadata. Følgelig ble alle ringene målrettet samtidig. Den feilaktige distribusjonen førte til at tjenestetilgjengeligheten ble dårligere.
I løpet av minutter etter påvirkning tok vi skritt for å tilbakestille endringen ved å bruke automatiserte tilbakerullingssystemer som normalt ville begrenset varigheten og alvorlighetsgraden av påvirkningen. Imidlertid hadde den latente defekten i SDP-systemet vårt ødelagt distribusjonsmetadataene, og vi måtte ty til manuelle tilbakeføringsprosesser. Dette forlenget tiden for å avhjelpe problemet betydelig.
Skadebegrensning: Vår overvåking oppdaget tjenesteforringelsen i løpet av minutter etter første påvirkning, og vi engasjerte oss umiddelbart for å starte feilsøking. Følgende avbøtende tiltak ble iverksatt:
- Påvirkningen startet klokken 21:25 UTC, og i løpet av 5 minutter oppdaget vår overvåking en usunn tilstand, og ingeniørarbeid ble umiddelbart satt i gang.
- I løpet av de neste 30 minuttene, samtidig med feilsøking av problemet, ble det iverksatt en rekke skritt for å forsøke å minimere kundepåvirkning og fremskynde avbøtende tiltak. Dette inkluderte proaktiv utskalering av noen av Azure AD-tjenestene for å håndtere forventet belastning når en reduksjon ville blitt brukt og feil over visse arbeidsbelastninger til et sikkerhetskopi av Azure AD-autentiseringssystem.
- Klokken 22:02 UTC etablerte vi grunnårsaken, begynte utbedring og startet våre automatiske tilbakeføringsmekanismer.
- Automatisk tilbakerulling mislyktes på grunn av korrupsjon av SDP-metadataene. Klokken 22:47 UTC startet vi prosessen for å manuelt oppdatere tjenestekonfigurasjonen som omgår SDP-systemet, og hele operasjonen ble fullført innen 23:59 UTC.
- Ved 00:23 UTC returnerte nok backend-tjenesteforekomster til en sunn tilstand til å nå normale driftsparametere for tjenesten.
- Alle serviceforekomster med gjenværende påvirkning ble gjenopprettet innen 02:25 UTC.
Neste skritt: Vi beklager på det sterkeste innvirkningen på berørte kunder. Vi tar kontinuerlig skritt for å forbedre Microsoft Azure-plattformen og prosessene våre for å sikre at slike hendelser ikke oppstår i fremtiden. I dette tilfellet inkluderer dette (men er ikke begrenset til) følgende:
Vi har allerede fullført
- Rettet den latente kodefeilen i Azure AD-backend SDP-systemet.
- Rettet det eksisterende tilbakerullingssystemet for å tillate gjenoppretting av de siste kjente og gode metadataene for å beskytte mot korrupsjon.
- Utvid omfanget og hyppigheten av tilbakerullingsøvelser.
De resterende trinnene inkluderer
- Bruk ekstra beskyttelse på Azure AD-tjenestens backend SDP-system for å forhindre klassen med problemer som er identifisert her.
- Fremskynde utrullingen av Azure AD-sikkerhetskopieringsautentiseringssystem til alle nøkkeltjenester som en toppprioritet for å redusere virkningen av en lignende type problemer i fremtiden.
- Innebygde Azure AD-scenarier til den automatiserte kommunikasjonspipelinen som legger ut første kommunikasjon til berørte kunder innen 15 minutter etter påvirkning.
Gi tilbakemelding: Hjelp oss å forbedre Azure-kundekommunikasjonsopplevelsen ved å delta i undersøkelsen vår: https://aka.ms/AzurePIRSurvey
av ZDNet