Microsoft publiceert een analyse van de hoofdoorzaken voor de grote Microsoft 365-inlogproblemen van deze week
![]() 6 minuut. lezen
6 minuut. lezen
![]() Bijgewerkt op
Bijgewerkt op
deel dit artikel

Verbeter deze handleiding
Lees onze openbaarmakingspagina om erachter te komen hoe u MSPoweruser kunt helpen het redactieteam te ondersteunen Lees meer
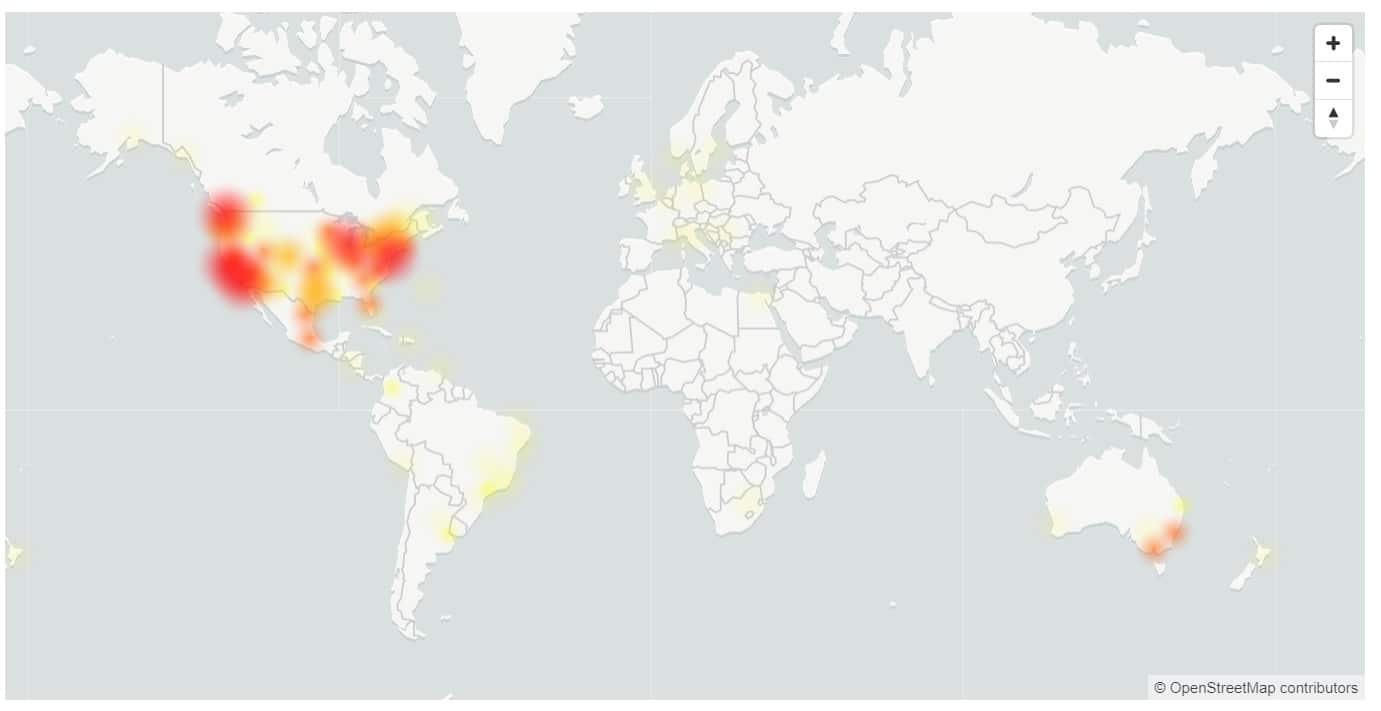
Deze week hadden we een uitvaltijd van bijna 5 uur voor Microsoft 365, met gebruikers die zich niet kunnen aanmelden bij meerdere services, waaronder OneDrive en Microsoft Teams.
Heden Microsoft heeft een analyse van de oorzaak van het probleem gepubliceerd, waarvan Microsoft zegt dat het te wijten was aan een service-update die bedoeld was om een interne validatietestring te targeten, maar die in plaats daarvan rechtstreeks in de productieomgeving van Microsoft werd geïmplementeerd vanwege een latent codedefect in het Azure AD-backendservice Safe Deployment Process (SDP) -systeem.
Microsoft zegt dat klanten tussen ongeveer 21:25 UTC op 28 september 2020 en 00:23 UTC op 29 september 2020 fouten hebben aangetroffen bij het uitvoeren van verificatiebewerkingen voor alle toepassingen en services van Microsoft en derden die afhankelijk zijn van Azure Active Directory (Azure AD ) voor authenticatie. Het probleem was de volgende dag pas om 2:25 voor iedereen volledig verholpen.
De VS en Australië werden het zwaarst getroffen, met slechts 17% van de gebruikers in de VS die zich met succes konden aanmelden.
Het probleem werd verergerd doordat Microsoft de update niet kon terugdraaien vanwege het latente defect in hun SDP-systeem dat de metadata van de implementatie corrumpeerde, wat betekent dat de update handmatig moest worden teruggedraaid.
Microsoft verontschuldigde zich bij de getroffen klanten en zegt dat ze stappen blijven ondernemen om het Microsoft Azure Platform en hun processen te verbeteren om ervoor te zorgen dat dergelijke incidenten zich in de toekomst niet meer voordoen. Een van de geplande stappen omvat het toepassen van aanvullende beveiligingen op het backend-SDP-systeem van de Azure AD-service om de geïdentificeerde problemen te voorkomen.
Lees hieronder de volledige analyse:
RCA - Verificatiefouten in meerdere Microsoft-services en geïntegreerde Azure Active Directory-toepassingen (tracking-ID SM79-F88)
Samenvatting van de impact: Tussen ongeveer 21:25 UTC op 28 september 2020 en 00:23 UTC op 29 september 2020 zijn klanten mogelijk fouten tegengekomen bij het uitvoeren van verificatiebewerkingen voor alle toepassingen en services van Microsoft en derden die afhankelijk zijn van Azure Active Directory (Azure AD) voor authenticatie. Toepassingen die Azure AD B2C gebruiken voor verificatie werden ook beïnvloed.
Gebruikers die nog niet waren geverifieerd bij cloudservices met behulp van Azure AD, hadden meer kans op problemen en hebben mogelijk meerdere mislukte verificatieverzoeken gezien die overeenkomen met de gemiddelde beschikbaarheidscijfers die hieronder worden weergegeven. Deze zijn geaggregeerd over verschillende klanten en workloads.
- Europa: 81% slagingspercentage voor de duur van het incident.
- Amerika: 17% slagingspercentage voor de duur van het incident, verbeterend tot 37% net voor mitigatie.
- Azië: 72% slagingspercentage in de eerste 120 minuten van het incident. Toen de piekuren tijdens kantooruren begonnen, daalde de beschikbaarheid tot 32% op het laagste punt.
- Australië: 37% slagingspercentage voor de duur van het incident.
De service is voor de meeste klanten om 00:23 UTC op 29 september 2020 hersteld naar de normale operationele beschikbaarheid. We hebben echter onregelmatige verificatieverzoeken geconstateerd die mogelijk tot 02:25 UTC gevolgen hebben gehad voor klanten.
Gebruikers die zich vóór de starttijd van de impact hadden geverifieerd, hadden minder kans op problemen, afhankelijk van de applicaties of services waartoe ze toegang hadden.
Veerkrachtmaatregelen beschermden Managed Identities-services voor virtuele machines, virtuele-machineschaalsets en Azure Kubernetes-services met een gemiddelde beschikbaarheid van 99.8% gedurende de duur van het incident.
Oorzaak: Op 28 september om 21:25 UTC is een service-update geïmplementeerd die gericht is op een interne validatietestring, waardoor een crash ontstond bij het opstarten in de Azure AD-backendservices. Een latente codefout in het Azure AD backend-service Safe Deployment Process (SDP)-systeem zorgde ervoor dat dit rechtstreeks in onze productieomgeving werd geïmplementeerd, waarbij ons normale validatieproces werd omzeild.
Azure AD is ontworpen als een geo-gedistribueerde service die wordt geïmplementeerd in een actief-actieve configuratie met meerdere partities in meerdere datacenters over de hele wereld, gebouwd met isolatiegrenzen. Normaal gesproken richten wijzigingen zich in eerste instantie op een validatiering die geen klantgegevens bevat, gevolgd door een binnenring die alleen Microsoft-gebruikers bevat, en tot slot onze productieomgeving. Deze wijzigingen worden gedurende meerdere dagen gefaseerd in vijf ringen geïmplementeerd.
In dit geval slaagde het SDP-systeem er niet in om de validatietestring correct te targeten vanwege een latent defect dat van invloed was op het vermogen van het systeem om implementatiemetadata te interpreteren. Bijgevolg werden alle ringen gelijktijdig aangevallen. Door de onjuiste implementatie is de beschikbaarheid van de service afgenomen.
Binnen enkele minuten na de impact hebben we stappen ondernomen om de wijziging ongedaan te maken met behulp van geautomatiseerde rollback-systemen die normaal gesproken de duur en ernst van de impact zouden hebben beperkt. Het latente defect in ons SDP-systeem had echter de metadata van de implementatie beschadigd en we moesten onze toevlucht nemen tot handmatige rollback-processen. Dit verlengde de tijd om het probleem te verhelpen aanzienlijk.
Beperking: Onze monitoring detecteerde de verslechtering van de service binnen enkele minuten na de eerste impact en we namen onmiddellijk contact op om de probleemoplossing te starten. De volgende mitigerende activiteiten zijn ondernomen:
- De impact begon om 21:25 UTC en binnen 5 minuten detecteerde onze monitoring een ongezonde toestand en werd de engineering onmiddellijk ingeschakeld.
- In de loop van de volgende 30 minuten werden, samen met het oplossen van het probleem, een reeks stappen ondernomen om te proberen de impact op de klant te minimaliseren en de beperking te versnellen. Dit omvatte het proactief uitschalen van een aantal van de Azure AD-services om de verwachte belasting af te handelen zodra een beperking zou zijn toegepast en het falen van bepaalde workloads naar een back-up Azure AD-verificatiesysteem.
- Om 22:02 UTC hebben we de hoofdoorzaak vastgesteld, zijn we begonnen met herstel en zijn we begonnen met onze geautomatiseerde terugdraaimechanismen.
- Geautomatiseerde rollback is mislukt vanwege de corruptie van de SDP-metadata. Om 22:47 UTC hebben we het proces gestart om de serviceconfiguratie handmatig bij te werken die het SDP-systeem omzeilt, en de hele operatie voltooid om 23:59 UTC.
- Tegen 00:23 UTC keerden voldoende backend-service-instanties terug naar een gezonde staat om de normale operationele parameters van de service te bereiken.
- Alle service-instanties met resterende impact werden hersteld om 02:25 UTC.
Volgende stappen: Onze oprechte excuses voor de gevolgen voor de getroffen klanten. We nemen voortdurend stappen om het Microsoft Azure Platform en onze processen te verbeteren om ervoor te zorgen dat dergelijke incidenten zich in de toekomst niet meer voordoen. In dit geval omvat dit (maar is niet beperkt tot) het volgende:
We zijn al klaar
- Het latente codedefect in het Azure AD-backend SDP-systeem opgelost.
- Het bestaande rollback-systeem gerepareerd om de laatst bekende goede metadata te kunnen herstellen ter bescherming tegen corruptie.
- Breid de reikwijdte en frequentie uit van oefeningen voor terugdraaibewerkingen.
De resterende stappen omvatten:
- Pas aanvullende beveiligingen toe op het back-end SDP-systeem van de Azure AD-service om de hier geïdentificeerde problemen te voorkomen.
- Versnel de uitrol van Azure AD-back-upverificatiesysteem naar alle belangrijke services als een topprioriteit om de impact van een soortgelijk type probleem in de toekomst aanzienlijk te verminderen.
- Onboard Azure AD-scenario's voor de geautomatiseerde communicatiepijplijn die de eerste communicatie naar de getroffen klanten binnen 15 minuten na de impact verzendt.
Geef feedback: Help ons de Azure-ervaring met klantcommunicatie te verbeteren door onze enquête in te vullen: https://aka.ms/AzurePIRSurvey
via ZDNet