Microsoft、今週発生したMicrosoft 365のログインに関する大規模な問題の根本原因分析を投稿
![]() 6分。 読んだ
6分。 読んだ
![]() 更新日
更新日
この記事を共有する

このガイドを改善する
MSPoweruser の編集チームの維持にどのように貢献できるかについては、開示ページをお読みください。 続きを読む
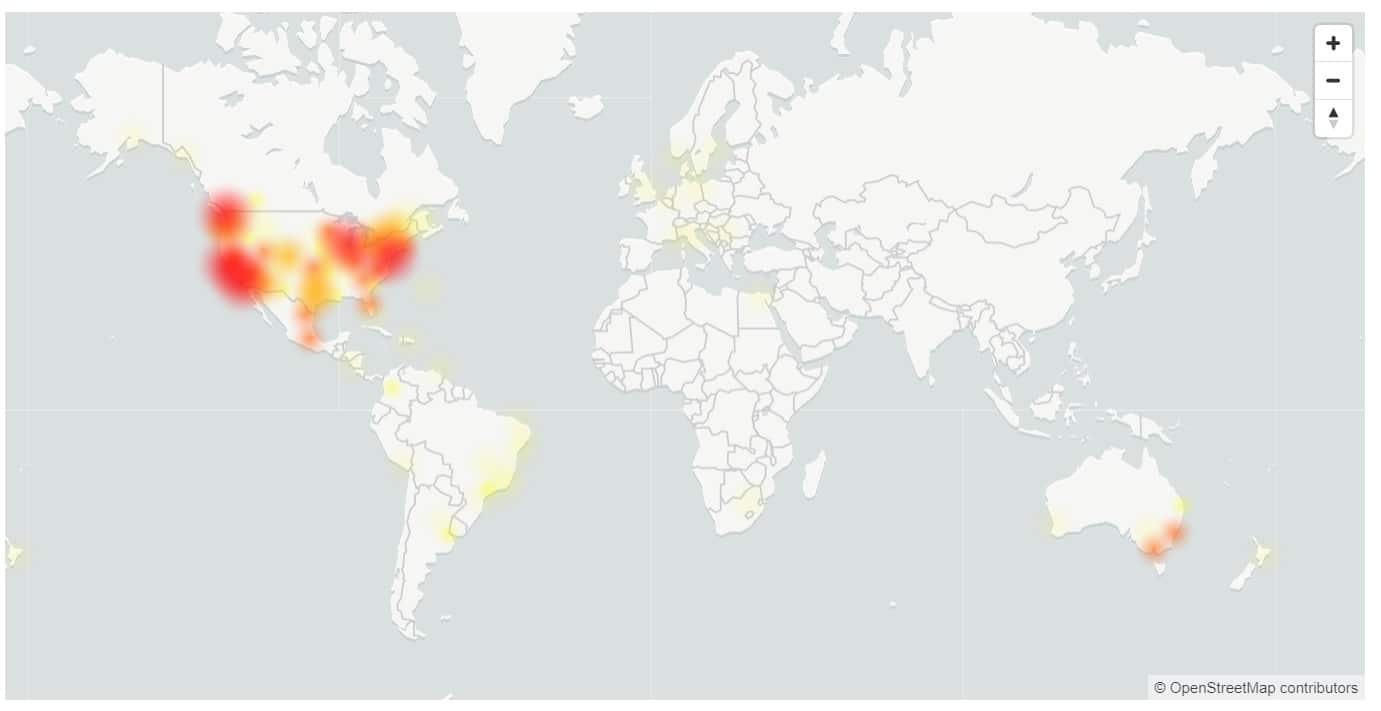
今週、Microsoft5のダウンタイムは365時間近くになりました。 ユーザーがOneDriveやMicrosoftTeamsなどの複数のサービスにログインできない場合。
今日 マイクロソフトは、問題の根本原因分析を公開しました、Microsoftによると、内部検証テストリングを対象としたサービスの更新が原因でしたが、AzureADバックエンドサービスのSafeDeployment Process(SDP)システムの潜在的なコードの欠陥により、Microsoftの本番環境に直接展開されました。
Microsoftによると、21年25月28日の2020:00UTCから23年29月2020日の2:25UTCの間に、Azure Active Directory(Azure AD)に依存するすべてのMicrosoftおよびサードパーティのアプリケーションとサービスの認証操作の実行中にエラーが発生しました。 )認証用。 この問題は、翌日のXNUMX:XNUMXまでに完全に軽減されました。
米国とオーストラリアが最も大きな打撃を受け、米国のユーザーの17%だけが正常にサインインできました。
この問題は、MicrosoftがSDPシステムの潜在的な欠陥により展開メタデータが破損しているために更新をロールバックできないため、さらに悪化しました。つまり、更新を手動でロールバックする必要がありました。
Microsoftは、影響を受けたお客様に謝罪し、Microsoft Azureプラットフォームとそのプロセスを改善して、今後このようなインシデントが発生しないようにするための措置を引き続き講じていると述べています。 計画されている手順のXNUMXつには、特定された問題のクラスを防ぐために、AzureADサービスバックエンドSDPシステムに追加の保護を適用することが含まれます。
以下の完全な分析をお読みください。
RCA –複数のMicrosoftサービスとAzure Active Directory統合アプリケーションでの認証エラー(追跡ID SM79-F88)
影響の概要: 21年25月28日の2020:00UTCから23年29月2020日の2:XNUMXUTCの間に、Azure Active Directory(Azure AD)に依存するすべてのMicrosoftおよびサードパーティのアプリケーションとサービスの認証操作の実行中にエラーが発生する場合があります。認証用。 認証にAzureADBXNUMXCを使用するアプリケーションも影響を受けました。
Azure ADを使用してクラウドサービスに対してまだ認証されていないユーザーは、問題が発生する可能性が高く、以下に示す平均可用性数に対応する複数の認証要求の失敗が発生した可能性があります。 これらは、さまざまな顧客およびワークロードにわたって集約されています。
- ヨーロッパ:インシデント期間中の成功率は81%です。
- 南北アメリカ:インシデント期間中の成功率は17%で、軽減直前は37%に向上しました。
- アジア:インシデントの最初の72分間で120%の成功率。 営業時間のピークトラフィックが始まると、可用性は最低で32%に低下しました。
- オーストラリア:事件期間中の成功率は37%。
00年23月29日の2020:02UTCまでに、サービスは大多数のお客様の通常の運用可能性に復元されましたが、25:XNUMX UTCまでお客様に影響を与える可能性のある、まれな認証要求の失敗が観察されました。
影響の開始時刻より前に認証を行ったユーザーは、アクセスしているアプリケーションやサービスによっては問題が発生する可能性が低くなりました。
レジリエンス対策は、仮想マシン、仮想マシンスケールセット、およびAzure Kubernetesサービスの保護されたマネージドIDサービスであり、インシデントの期間中の平均可用性は99.8%です。
根本的な原因: 28月21日25:XNUMXUTCに、内部検証テストリングを対象とするサービス更新プログラムが展開され、AzureADバックエンドサービスの起動時にクラッシュが発生しました。 AzureADバックエンドサービスのSafeDeploymentProcess(SDP)システムに潜在的なコードの欠陥があるため、通常の検証プロセスをバイパスして、これが本番環境に直接デプロイされました。
Azure ADは、分離境界を使用して構築された、世界中の複数のデータセンターにまたがる複数のパーティションを備えたアクティブ-アクティブ構成で展開される地理分散サービスとして設計されています。 通常、変更は最初に顧客データを含まない検証リングを対象とし、次にMicrosoftのみのユーザーを含む内部リング、最後に本番環境を対象とします。 これらの変更は、数日間にわたってXNUMXつのリングに段階的に展開されます。
この場合、展開メタデータを解釈するシステムの機能に影響を与える潜在的な欠陥が原因で、SDPシステムは検証テストリングを正しくターゲットにできませんでした。 その結果、すべてのリングが同時にターゲットにされました。 誤った展開により、サービスの可用性が低下しました。
影響から数分以内に、通常は影響の期間と重大度が制限される自動ロールバックシステムを使用して、変更を元に戻すための措置を講じました。 ただし、SDPシステムの潜在的な欠陥により、展開メタデータが破損していたため、手動のロールバックプロセスに頼らざるを得ませんでした。 これにより、問題を軽減するための時間が大幅に延長されました。
緩和: 監視により、最初の影響から数分以内にサービスの低下が検出され、すぐにトラブルシューティングを開始しました。 以下の緩和活動が実施されました。
- 影響は21:25UTCに始まり、5分以内に監視によって不健康な状態が検出され、エンジニアリングがすぐに開始されました。
- 次の30分間で、問題のトラブルシューティングと並行して、顧客への影響を最小限に抑え、軽減を促進するための一連の手順が実行されました。 これには、緩和策が適用された後に予想される負荷を処理するために一部のAzure ADサービスをプロアクティブにスケールアウトし、特定のワークロードをバックアップAzureAD認証システムにフェイルオーバーすることが含まれます。
- UTC 22:02に、根本原因を特定し、修復を開始し、自動ロールバックメカニズムを開始しました。
- SDPメタデータが破損しているため、自動ロールバックが失敗しました。 22:47 UTCに、SDPシステムをバイパスするサービス構成を手動で更新するプロセスを開始し、操作全体が23:59UTCまでに完了しました。
- 00:23 UTCまでに、十分なバックエンドサービスインスタンスが正常な状態に戻り、通常のサービス操作パラメーターに到達しました。
- 影響が残っているすべてのサービスインスタンスは、02:25UTCまでに回復されました。
次のステップ: ご迷惑をおかけしましたことをお詫び申し上げます。 Microsoft Azureプラットフォームとプロセスを改善するための措置を継続的に講じて、このようなインシデントが将来発生しないようにします。 この場合、これには以下が含まれます(ただしこれらに限定されません)。
すでに完了しています
- AzureADバックエンドSDPシステムの潜在的なコードの欠陥を修正しました。
- 既存のロールバックシステムを修正して、破損から保護するために最後の正常なメタデータを復元できるようにしました。
- ロールバック操作ドリルの範囲と頻度を拡大します。
残りの手順は次のとおりです。
- Azure ADサービスのバックエンドSDPシステムに追加の保護を適用して、ここで特定されたクラスの問題を防止します。
- Azure ADバックアップ認証システムのすべての主要なサービスへの展開を最優先事項として迅速化し、将来同様のタイプの問題の影響を大幅に軽減します。
- 影響を受けてから15分以内に影響を受ける顧客に最初の通信を送信する自動通信パイプラインへのオンボードAzureADシナリオ。
フィードバックを提供します: アンケートに回答して、Azureのカスタマーコミュニケーションエクスペリエンスの向上にご協力ください。 https://aka.ms/AzurePIRSurvey
、 ZDNetの