大量の100億パラメータモデルをトレーニングできる新しいディープラーニングライブラリであるMicrosoftDeepSpeedをご覧ください
![]() 2分。 読んだ
2分。 読んだ
![]() 更新日
更新日
この記事を共有する

このガイドを改善する
読者は MSpoweruser のサポートを支援します。私たちのリンクを通じて購入すると、手数料が発生する場合があります。

MSPoweruser の編集チームの維持にどのように貢献できるかについては、開示ページをお読みください。 続きを読む
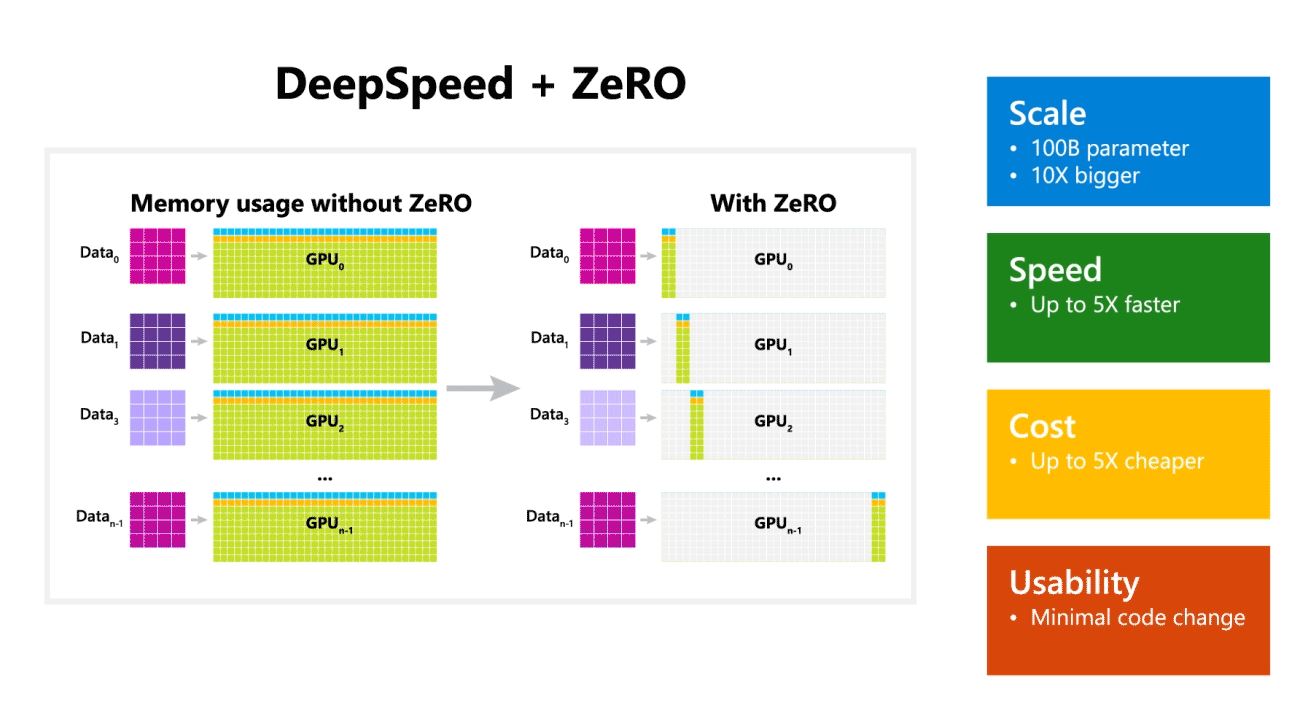
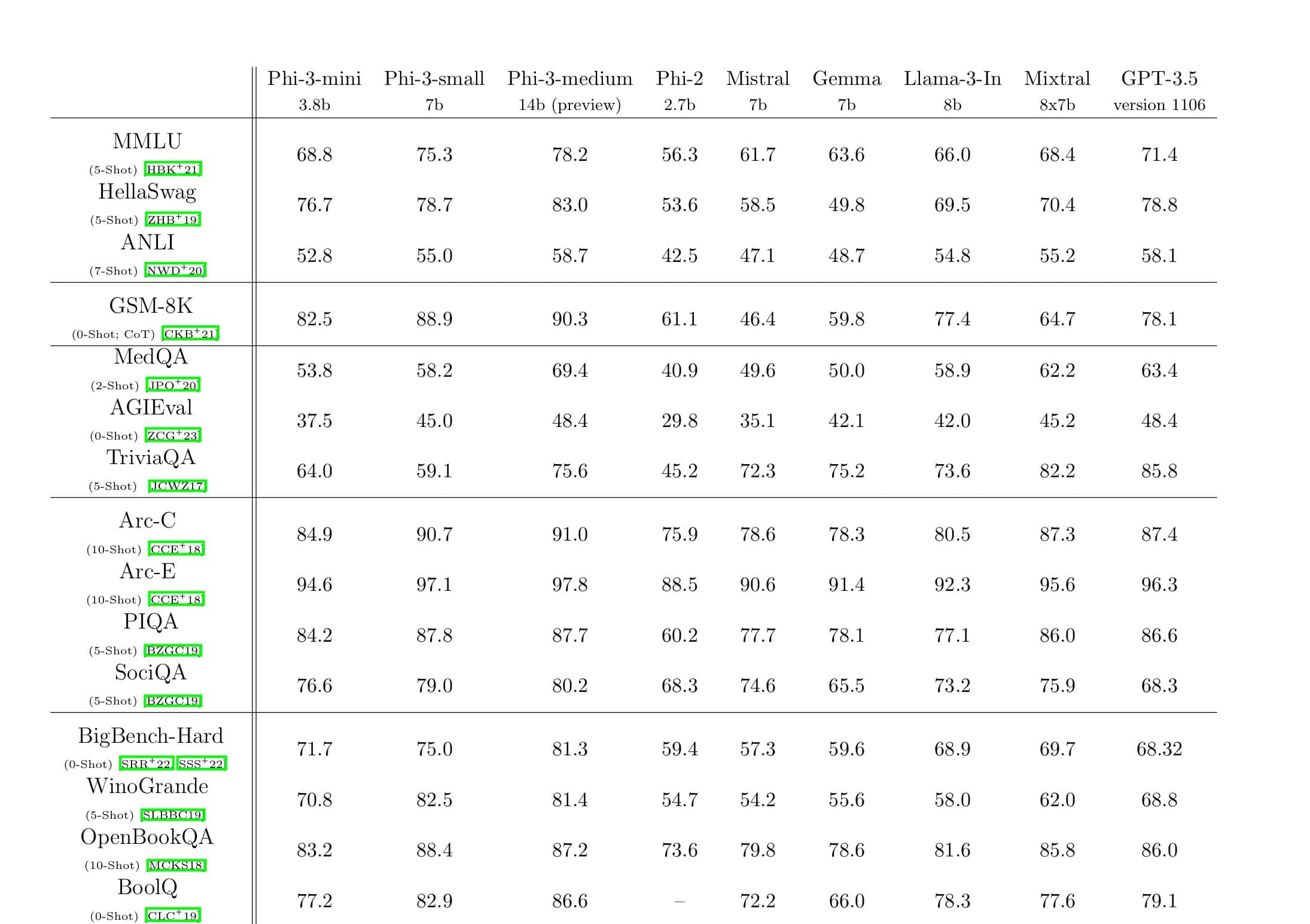
Microsoft Researchは本日、100億パラメータの大規模なモデルをトレーニングできる新しいディープラーニング最適化ライブラリであるDeepSpeedを発表しました。 AIでは、精度を高めるために、より大きな自然言語モデルが必要です。 しかし、より大きな自然言語モデルのトレーニングには時間がかかり、それに関連するコストは非常に高くなります。 Microsoftは、新しいDeepSpeedディープラーニングライブラリにより、速度、コスト、規模、および使いやすさが向上すると主張しています。
Microsoftはまた、DeepSpeedが最大100億のパラメーターモデルを備えた言語モデルを可能にし、ZeRO(Zero Redundancy Optimizer)を含むことにも言及しました。これは、トレーニング可能なパラメーターの数を増やしながら、モデルとデータの並列処理に必要なリソースを削減する並列化オプティマイザーです。 。 Microsoft Researchersは、DeepSpeedとZeROを使用して、17億のパラメーターを持つ最大の言語モデルである新しいチューリング自然言語生成(Turing-NLG)を開発しました。
DeepSpeedのハイライト:
- 規模:OpenAI GPT-2、NVIDIA Megatron-LM、Google T5などの最先端の大型モデルのサイズは、それぞれ1.5億、8.3億、11億のパラメーターです。 DeepSpeedのZeROステージ100は、最大10億個のパラメーター(XNUMX倍)のモデルを実行するためのシステムサポートを提供します。
- 速度:さまざまなハードウェアで、最先端のスループットの最大3.75倍のスループットが見られます。 低帯域幅の相互接続を備えたNVIDIAGPUクラスター(NVIDIA NVLinkまたはInfinibandなし)では、2億個のパラメーターを持つ標準GPT-1.5モデルでMegatron-LMを単独で使用した場合に比べて2倍のスループットの向上を実現します。 高帯域幅の相互接続を備えたNVIDIADGX-20クラスターでは、80〜XNUMX億のパラメーターのモデルの場合、XNUMX〜XNUMX倍高速です。
- 費用:スループットの向上は、トレーニングコストの大幅な削減につながります。 たとえば、20億個のパラメーターを使用してモデルをトレーニングするには、DeepSpeedに必要なリソースはXNUMX分のXNUMXです。
- 使いやすさ:PyTorchモデルでDeepSpeedとZeROを使用できるようにするには、数行のコード変更のみが必要です。 現在のモデル並列処理ライブラリと比較すると、DeepSpeedではコードの再設計やモデルのリファクタリングは必要ありません。
MicrosoftはDeepSpeedとZeROの両方をオープンソーシングしています。チェックしてください。 ここGitHub上。
情報源: Microsoft