Microsoft pubblica un'analisi delle cause principali dei grandi problemi di accesso a Microsoft 365 di questa settimana
![]() 6 minuto. leggere
6 minuto. leggere
![]() Aggiornato su
Aggiornato su
Condividi questo articolo

Migliora questa guida
Leggi la nostra pagina informativa per scoprire come puoi aiutare MSPoweruser a sostenere il team editoriale Per saperne di più
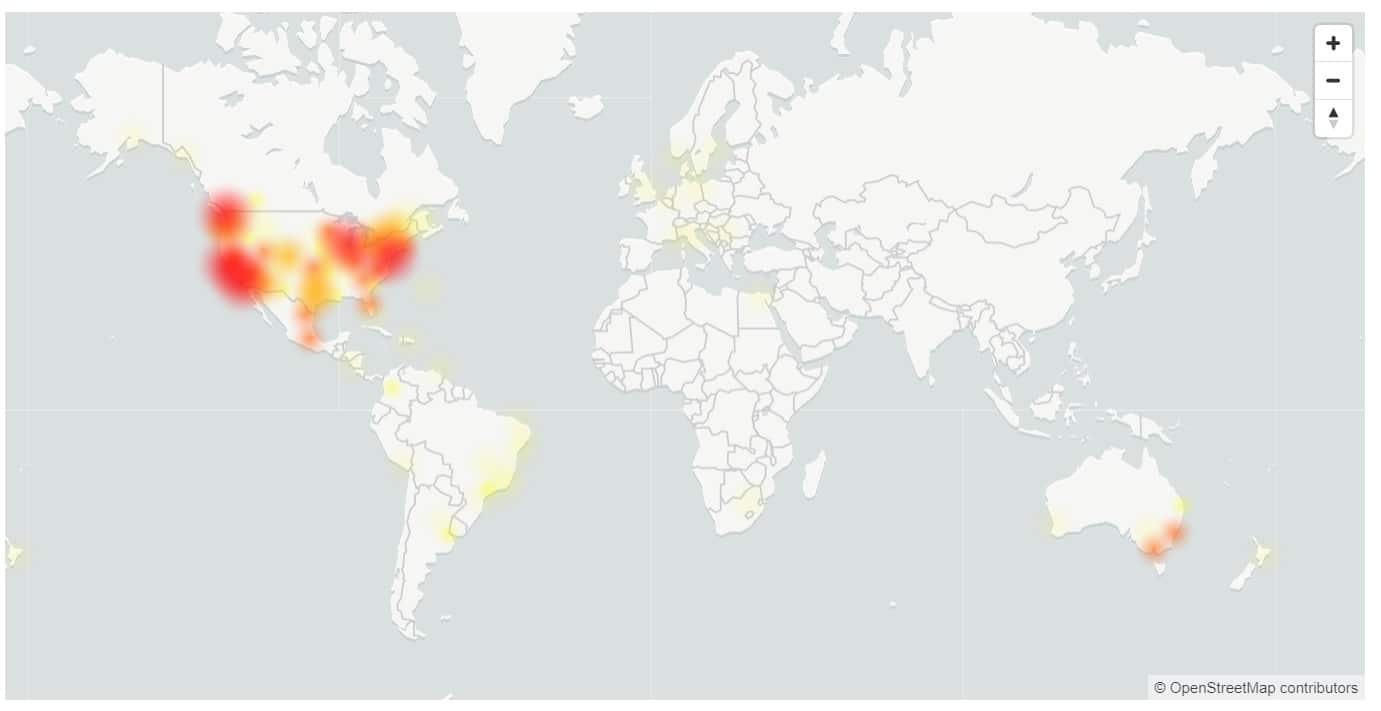
Questa settimana abbiamo avuto un tempo di inattività di quasi 5 ore per Microsoft 365, con gli utenti che non sono in grado di accedere a più servizi, inclusi OneDrive e Microsoft Teams.
Oggi Microsoft ha pubblicato un'analisi della causa principale del problema, che secondo Microsoft era dovuto all'aggiornamento del servizio destinato a un anello di test di convalida interno ma che è stato invece distribuito direttamente nell'ambiente di produzione di Microsoft a causa di un difetto di codice latente nel sistema SDP (Safe Deployment Process) del servizio back-end di Azure AD.
Microsoft afferma che tra le 21:25 UTC circa del 28 settembre 2020 e le 00:23 UTC del 29 settembre 2020, i clienti hanno riscontrato errori durante l'esecuzione delle operazioni di autenticazione per tutte le applicazioni e i servizi Microsoft e di terze parti che dipendono da Azure Active Directory (Azure AD ) per l'autenticazione. Il problema è stato completamente attenuato per tutti solo entro le 2:25 del giorno successivo.
Stati Uniti e Australia sono stati i più colpiti, con solo il 17% degli utenti negli Stati Uniti in grado di accedere con successo.
Il problema è stato aggravato dal fatto che Microsoft non è stata in grado di ripristinare l'aggiornamento a causa del difetto latente nel sistema SDP che danneggia i metadati di distribuzione, il che significa che l'aggiornamento doveva essere ripristinato manualmente.
Microsoft si è scusata con i clienti interessati e ha affermato che stanno continuando ad adottare misure per migliorare la piattaforma Microsoft Azure e i loro processi per garantire che tali incidenti non si verifichino in futuro. Uno dei passaggi pianificati include l'applicazione di protezioni aggiuntive al sistema SDP back-end del servizio Azure AD per prevenire la classe di problemi identificati.
Leggi l'analisi completa di seguito:
RCA: errori di autenticazione su più servizi Microsoft e applicazioni integrate in Azure Active Directory (ID di traccia SM79-F88)
Riepilogo dell'impatto: Tra le 21:25 UTC circa del 28 settembre 2020 e le 00:23 UTC del 29 settembre 2020, i clienti potrebbero aver riscontrato errori durante l'esecuzione delle operazioni di autenticazione per tutte le applicazioni e i servizi Microsoft e di terze parti che dipendono da Azure Active Directory (Azure AD) per l'autenticazione. Anche le applicazioni che usano Azure AD B2C per l'autenticazione sono state interessate.
Gli utenti che non erano già stati autenticati ai servizi cloud tramite Azure AD avevano maggiori probabilità di riscontrare problemi e potrebbero aver riscontrato più errori di richiesta di autenticazione corrispondenti ai numeri di disponibilità medi mostrati di seguito. Questi sono stati aggregati tra diversi clienti e carichi di lavoro.
- Europa: tasso di successo dell'81% per la durata dell'incidente.
- Americhe: tasso di successo del 17% per la durata dell'incidente, in aumento al 37% appena prima della mitigazione.
- Asia: percentuale di successo del 72% nei primi 120 minuti dell'incidente. Con l'inizio del picco di traffico durante l'orario di lavoro, la disponibilità è scesa al 32% al livello più basso.
- Australia: tasso di successo del 37% per la durata dell'incidente.
Il servizio è stato ripristinato alla normale disponibilità operativa per la maggior parte dei clienti entro le 00:23 UTC del 29 settembre 2020, tuttavia, abbiamo osservato rari errori di richiesta di autenticazione che potrebbero aver avuto un impatto sui clienti fino alle 02:25 UTC.
Gli utenti che si erano autenticati prima dell'ora di inizio dell'impatto avevano meno probabilità di riscontrare problemi a seconda delle applicazioni o dei servizi a cui stavano accedendo.
La resilienza mette in atto servizi di identità gestite protetti per macchine virtuali, set di scalabilità di macchine virtuali e servizi Azure Kubernetes con una disponibilità media del 99.8% per tutta la durata dell'incidente.
Causa ultima: Il 28 settembre alle 21:25 UTC è stato distribuito un aggiornamento del servizio destinato a un anello di test di convalida interno, causando un arresto anomalo all'avvio nei servizi back-end di Azure AD. Un difetto di codice latente nel sistema SDP (Safe Deployment Process) del servizio back-end di Azure AD ne ha causato la distribuzione direttamente nel nostro ambiente di produzione, ignorando il nostro normale processo di convalida.
Azure AD è progettato per essere un servizio geodistribuito distribuito in una configurazione attivo-attivo con più partizioni in più data center in tutto il mondo, costruito con limiti di isolamento. Normalmente, le modifiche inizialmente riguardano un anello di convalida che non contiene dati sui clienti, seguito da un anello interno che contiene solo utenti Microsoft e, infine, il nostro ambiente di produzione. Queste modifiche vengono implementate in fasi su cinque anelli nell'arco di diversi giorni.
In questo caso, il sistema SDP non è riuscito a indirizzare correttamente l'anello di test di convalida a causa di un difetto latente che ha influito sulla capacità del sistema di interpretare i metadati di distribuzione. Di conseguenza, tutti gli anelli sono stati presi di mira contemporaneamente. La distribuzione errata ha causato il peggioramento della disponibilità del servizio.
Dopo pochi minuti dall'impatto, abbiamo adottato misure per annullare la modifica utilizzando sistemi di rollback automatizzati che normalmente avrebbero limitato la durata e la gravità dell'impatto. Tuttavia, il difetto latente nel nostro sistema SDP aveva danneggiato i metadati di distribuzione e abbiamo dovuto ricorrere a processi di rollback manuale. Ciò ha notevolmente prolungato il tempo per mitigare il problema.
mitigazione: Il nostro monitoraggio ha rilevato il degrado del servizio in pochi minuti dall'impatto iniziale e ci siamo impegnati immediatamente per avviare la risoluzione dei problemi. Sono state intraprese le seguenti attività di mitigazione:
- L'impatto è iniziato alle 21:25 UTC e in 5 minuti il nostro monitoraggio ha rilevato una condizione malsana e l'ingegneria è stata immediatamente impegnata.
- Nei successivi 30 minuti, in concomitanza con la risoluzione del problema, sono state intraprese una serie di passaggi per tentare di ridurre al minimo l'impatto sui clienti e accelerare la mitigazione. Ciò includeva la scalabilità orizzontale proattiva di alcuni servizi di Azure AD per gestire il carico previsto una volta applicata una mitigazione e il failover di determinati carichi di lavoro in un sistema di autenticazione di Azure AD di backup.
- Alle 22:02 UTC, abbiamo stabilito la causa principale, iniziato la riparazione e avviato i nostri meccanismi di ripristino automatico.
- Il rollback automatico non è riuscito a causa del danneggiamento dei metadati SDP. Alle 22:47 UTC abbiamo avviato il processo per aggiornare manualmente la configurazione del servizio che bypassa il sistema SDP e l'intera operazione è stata completata entro le 23:59 UTC.
- Entro le 00:23 UTC un numero sufficiente di istanze del servizio di back-end è tornato a uno stato integro per raggiungere i normali parametri operativi del servizio.
- Tutte le istanze del servizio con impatto residuo sono state recuperate entro le 02:25 UTC.
Passi successivi: Ci scusiamo sinceramente per l'impatto sui clienti interessati. Adottiamo continuamente misure per migliorare la piattaforma Microsoft Azure e i nostri processi per garantire che tali incidenti non si verifichino in futuro. In questo caso, ciò include (ma non è limitato a) quanto segue:
Abbiamo già completato
- Risolto il problema del codice latente nel sistema SDP back-end di Azure AD.
- Risolto il problema con il sistema di rollback esistente per consentire il ripristino degli ultimi metadati noti per proteggerli dalla corruzione.
- Espandere l'ambito e la frequenza delle esercitazioni delle operazioni di rollback.
I passaggi rimanenti includono
- Applicare protezioni aggiuntive al sistema SDP back-end del servizio Azure AD per prevenire la classe di problemi qui identificati.
- Accelerare l'implementazione del sistema di autenticazione di backup di Azure AD in tutti i servizi chiave come priorità assoluta per ridurre significativamente l'impatto di un tipo simile di problema in futuro.
- Integra gli scenari di Azure AD nella pipeline di comunicazioni automatizzate che pubblica la comunicazione iniziale ai clienti interessati entro 15 minuti dall'impatto.
Fornire un feedback: Aiutaci a migliorare l'esperienza di comunicazione con i clienti di Azure partecipando al nostro sondaggio: https://aka.ms/AzurePIRSurvey
via ZDNet