Upoznajte Microsoft DeepSpeed, novu biblioteku dubokog učenja koja može trenirati goleme modele od 100 milijardi parametara
![]() 2 min. čitati
2 min. čitati
![]() Ažurirano
Ažurirano
Podijelite ovaj članak

Poboljšajte ovaj vodič
Pročitajte našu stranicu za otkrivanje kako biste saznali kako možete pomoći MSPoweruseru da održi urednički tim Čitaj više
Microsoft Research je danas najavio DeepSpeed, novu biblioteku za optimizaciju dubokog učenja koja može trenirati ogromne modele od 100 milijardi parametara. U AI-u morate imati veće modele prirodnog jezika za bolju točnost. Ali obuka većih modela prirodnog jezika oduzima mnogo vremena i troškovi povezani s tim su vrlo visoki. Microsoft tvrdi da nova biblioteka dubokog učenja DeepSpeed poboljšava brzinu, cijenu, razmjer i upotrebljivost.
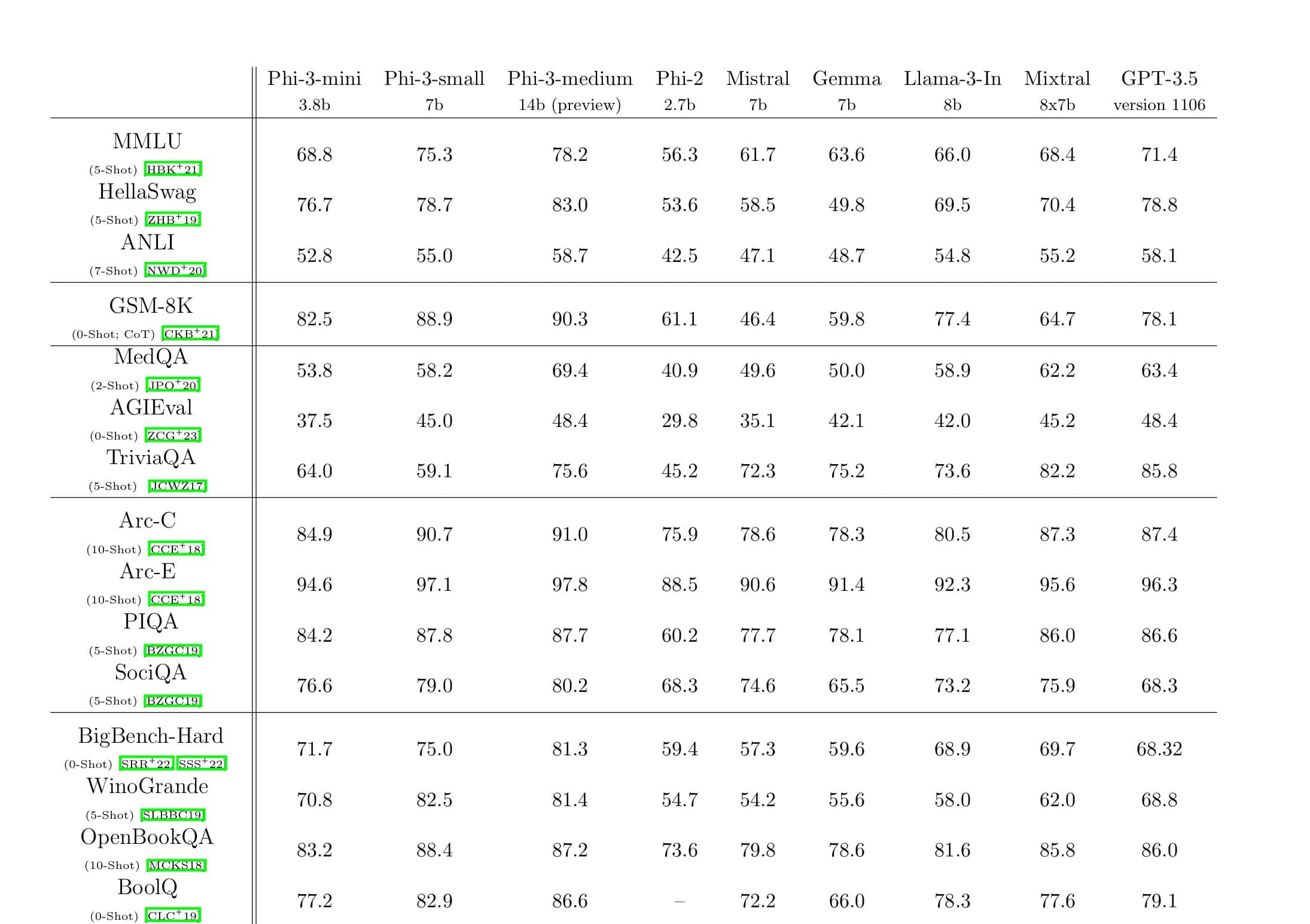
Microsoft je također spomenuo da DeepSpeed omogućuje jezične modele s modelima do 100 milijardi parametara i uključuje ZeRO (Zero Redundancy Optimizer), paralelizirani optimizator koji smanjuje resurse potrebne za paralelizam modela i podataka uz povećanje broja parametara koji se mogu trenirati . Koristeći DeepSpeed i ZeRO, Microsoftovi istraživači razvili su novu Turingovu generaciju prirodnog jezika (Turing-NLG), najveći jezični model sa 17 milijardi parametara.
Najvažnije značajke DeepSpeeda:
- Skala: Najsuvremeniji veliki modeli kao što su OpenAI GPT-2, NVIDIA Megatron-LM i Google T5 imaju veličine od 1.5 milijardi, 8.3 milijarde i 11 milijardi parametara. ZeRO stupanj jedan u DeepSpeedu pruža podršku sustava za pokretanje modela do 100 milijardi parametara, 10 puta veći.
- Ubrzati: Uočavamo i do pet puta veću propusnost u odnosu na najsuvremeniju opremu na različitim hardverima. Na NVIDIA GPU klasterima s međupovezivanjem niske propusnosti (bez NVIDIA NVLink ili Infinibanda) postižemo 3.75x poboljšanje propusnosti u odnosu na korištenje samo Megatron-LM za standardni GPT-2 model s 1.5 milijardi parametara. Na NVIDIA DGX-2 klasterima s interkonekcijom velike propusnosti, za modele od 20 do 80 milijardi parametara, tri smo do pet puta brži.
- Koštati: Poboljšana propusnost može se prevesti u značajno smanjene troškove obuke. Na primjer, za treniranje modela s 20 milijardi parametara, DeepSpeedu je potrebno tri puta manje resursa.
- Upotrebljivost: Potrebno je samo nekoliko redaka promjena koda kako bi se modelu PyTorch omogućilo korištenje DeepSpeeda i ZeRO. U usporedbi s trenutnim bibliotekama paralelizma modela, DeepSpeed ne zahtijeva redizajn koda ili refaktoriranje modela.
Microsoft je otvorenog izvora i DeepSpeed i ZeRO, možete provjeriti ovdje na GitHubu.
Izvor: microsoft