Tutustu Microsoft DeepSpeediin, uuteen syväoppimiskirjastoon, joka voi kouluttaa massiivisia 100 miljardin parametrin malleja
![]() 2 min. lukea
2 min. lukea
![]() Päivitetty
Päivitetty
Jaa tämä artikkeli

Paranna tätä ohjetta
Lue ilmoitussivumme saadaksesi selville, kuinka voit auttaa MSPoweruseria ylläpitämään toimitustiimiä Lue lisää
Microsoft Research julkisti tänään DeepSpeedin, uuden syvän oppimisen optimointikirjaston, joka voi kouluttaa massiivisia 100 miljardin parametrin malleja. Tekoälyssä tarvitaan suurempia luonnollisen kielen malleja parempaan tarkkuuteen. Mutta suurempien luonnollisen kielen mallien kouluttaminen on aikaa vievää ja siihen liittyvät kustannukset ovat erittäin korkeat. Microsoft väittää, että uusi DeepSpeed-syväoppimiskirjasto parantaa nopeutta, kustannuksia, mittakaavaa ja käytettävyyttä.
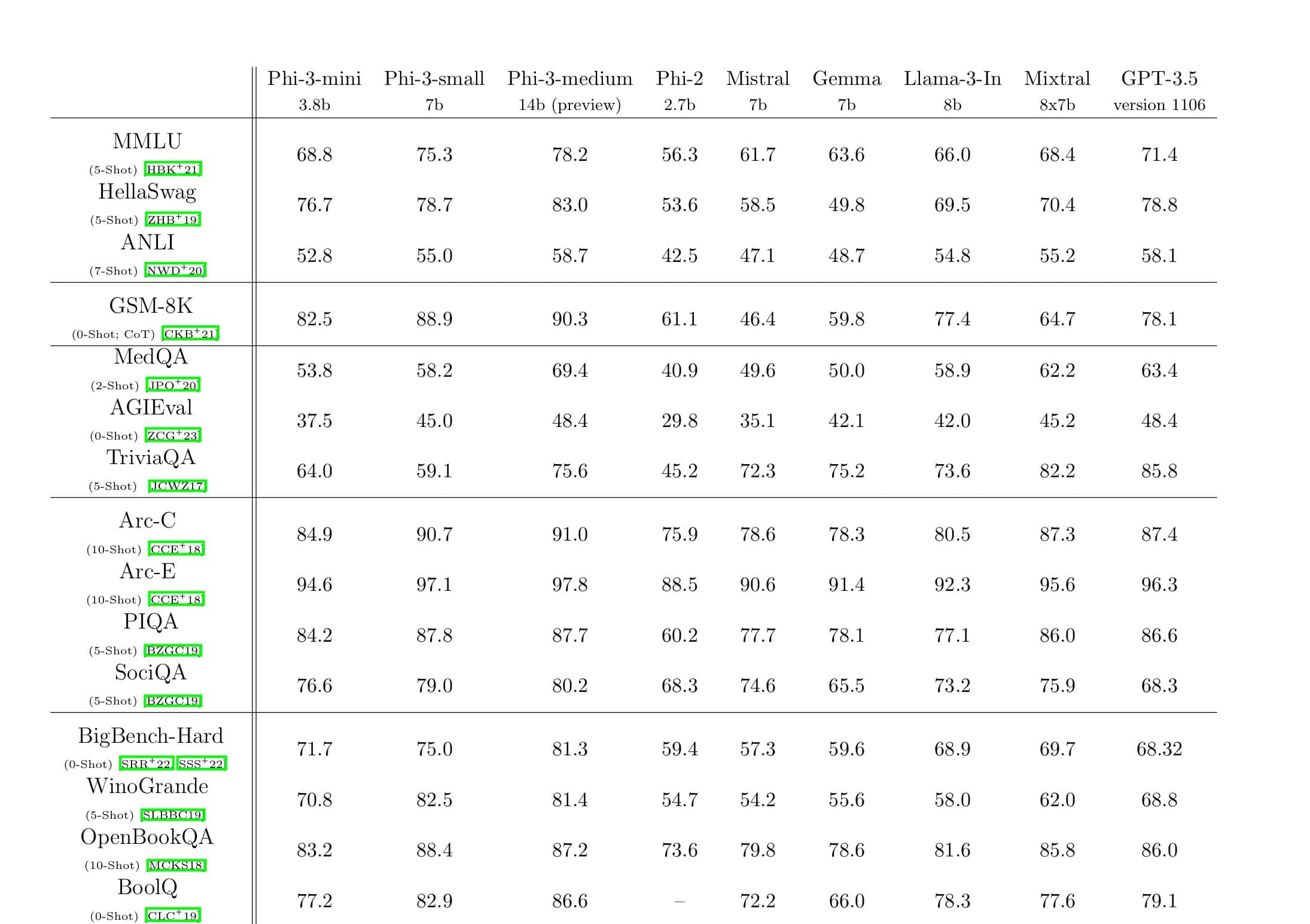
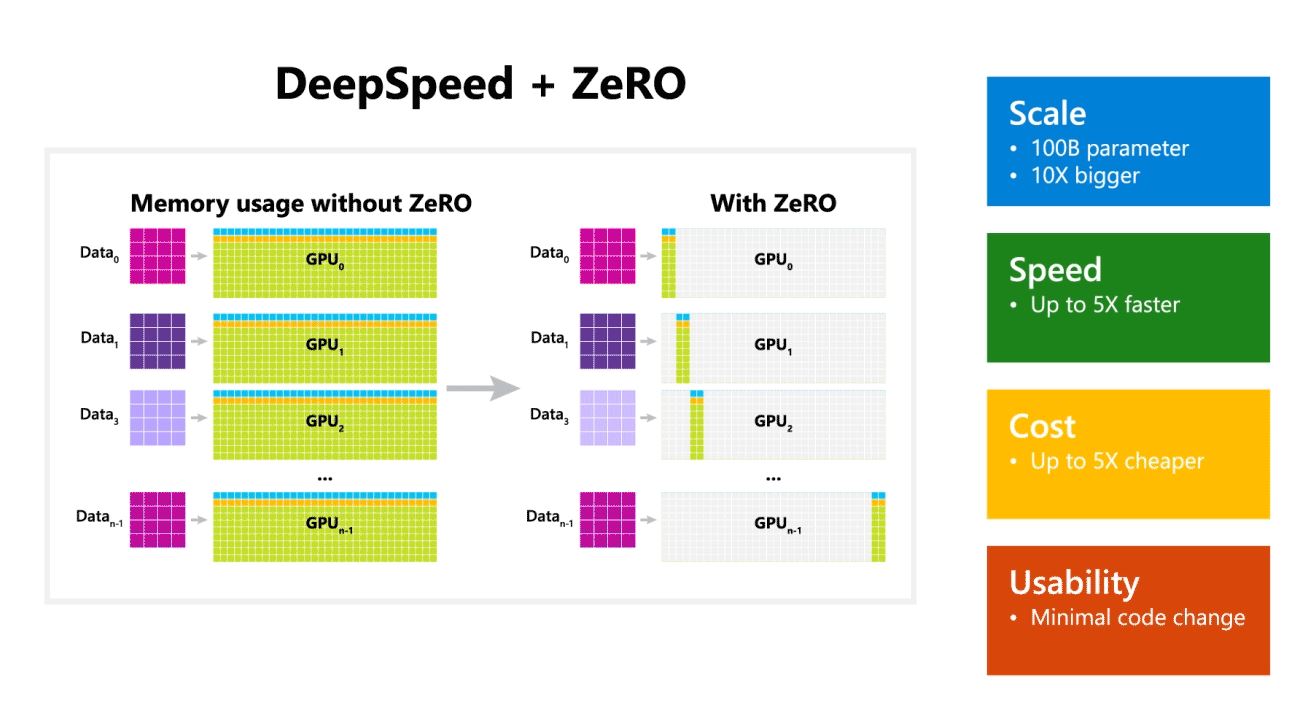
Microsoft mainitsi myös, että DeepSpeed mahdollistaa kielimallit, joissa on jopa 100 miljardin parametrin malleja, ja se sisältää ZeRO (Zero Redundancy Optimizer), rinnakkaisoptimoijan, joka vähentää mallin ja datan rinnakkaisuuteen tarvittavia resursseja ja lisää samalla opetettavien parametrien määrää. . Microsoftin tutkijat ovat kehittäneet DeepSpeediä ja ZeROa käyttämällä uuden Turing Natural Language Generationin (Turing-NLG), joka on suurin kielimalli 17 miljardilla parametrilla.
DeepSpeedin kohokohdat:
- Asteikko: Huippuluokan suurilla malleilla, kuten OpenAI GPT-2, NVIDIA Megatron-LM ja Google T5, on 1.5 miljardin, 8.3 miljardin ja 11 miljardin parametrin koko. DeepSpeedin ZeRO vaihe yksi tarjoaa järjestelmätuen jopa 100 miljardin parametrin malleille, jotka ovat 10 kertaa suurempia.
- Nopeus: Havaitsemme jopa viisi kertaa korkeamman suorituskyvyn uusimpaan verrattuna eri laitteistoissa. NVIDIA-grafiikkasuoritinklustereilla, joissa on pieni kaistanleveys yhteenliitännällä (ilman NVIDIA NVLinkkiä tai Infinibandia), saavutamme 3.75-kertaisen suorituskyvyn parannuksen verrattuna pelkkään Megatron-LM:n käyttöön tavallisessa GPT-2-mallissa, jossa on 1.5 miljardia parametria. NVIDIA DGX-2 -klustereissa, joissa on laaja kaistanleveys, 20–80 miljardin parametrin malleissa olemme kolmesta viiteen kertaa nopeampia.
- Hinta: Parannettu suorituskyky voidaan muuttaa merkittävästi alentuneiksi koulutuskustannuksiksi. Esimerkiksi 20 miljardin parametrin mallin kouluttaminen DeepSpeed vaatii kolme kertaa vähemmän resursseja.
- Käytettävyys: Vain muutaman rivin koodimuutoksia tarvitaan, jotta PyTorch-malli voi käyttää DeepSpeediä ja ZeROa. Verrattuna nykyisiin mallien rinnakkaiskirjastoihin, DeepSpeed ei vaadi koodin uudelleensuunnittelua tai mallin uudelleenjärjestelyä.
Microsoft käyttää avoimesti sekä DeepSpeediä että ZeROa, voit tarkistaa sen täällä GitHubissa.
Lähde: Microsoft