با Microsoft DeepSpeed آشنا شوید، یک کتابخانه یادگیری عمیق جدید که می تواند مدل های عظیم 100 میلیارد پارامتری را آموزش دهد.
![]() 2 دقیقه خواندن
2 دقیقه خواندن
![]() به روز شده در
به روز شده در
این مقاله را به اشتراک بگذارید

این راهنما را بهبود بخشید
صفحه افشای ما را بخوانید تا بدانید چگونه می توانید به MSPoweruser کمک کنید تا تیم تحریریه را حفظ کند ادامه مطلب
مایکروسافت ریسرچ امروز DeepSpeed را معرفی کرد، یک کتابخانه جدید بهینه سازی یادگیری عمیق که می تواند مدل های عظیم 100 میلیارد پارامتری را آموزش دهد. در هوش مصنوعی، برای دقت بهتر باید مدلهای زبان طبیعی بزرگتری داشته باشید. اما آموزش مدل های بزرگتر زبان طبیعی زمان بر است و هزینه های مرتبط با آن بسیار زیاد است. مایکروسافت ادعا می کند که کتابخانه جدید یادگیری عمیق DeepSpeed سرعت، هزینه، مقیاس و قابلیت استفاده را بهبود می بخشد.
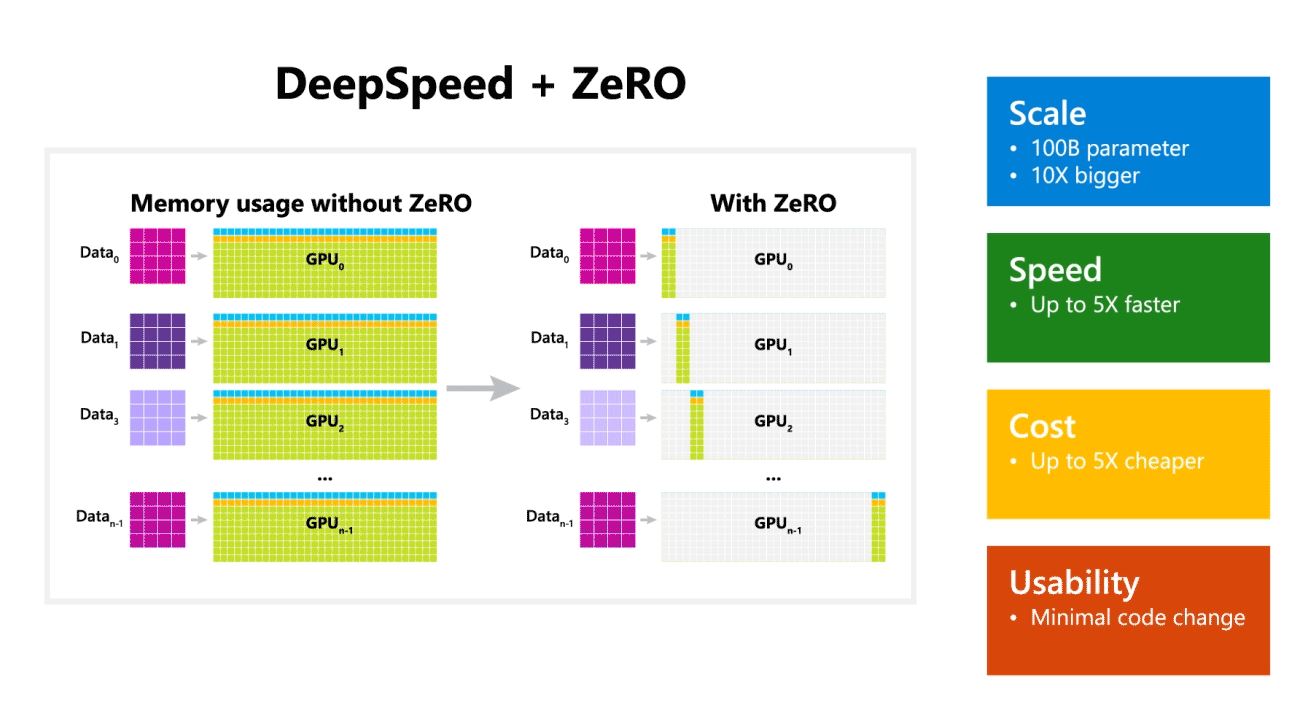
مایکروسافت همچنین اشاره کرد که DeepSpeed مدلهای زبانی را با مدلهای 100 میلیارد پارامتری فعال میکند و شامل ZeRO (Zero Redundancy Optimizer)، یک بهینهساز موازی است که منابع مورد نیاز برای موازیسازی مدل و داده را کاهش میدهد و در عین حال تعداد پارامترهای قابل آموزش را افزایش میدهد. . محققان مایکروسافت با استفاده از DeepSpeed و ZeRO نسل جدید زبان طبیعی تورینگ (Turing-NLG) را توسعه داده اند که بزرگترین مدل زبان با 17 میلیارد پارامتر است.
نکات برجسته DeepSpeed:
- مقیاس: مدل های بزرگ پیشرفته مانند OpenAI GPT-2، NVIDIA Megatron-LM و Google T5 به ترتیب دارای اندازه های 1.5 میلیارد، 8.3 میلیارد و 11 میلیارد پارامتر هستند. مرحله یک ZeRO در DeepSpeed پشتیبانی سیستم را برای اجرای مدل هایی تا 100 میلیارد پارامتر، 10 برابر بزرگتر، فراهم می کند.
- سرعت: ما در سخت افزارهای مختلف تا پنج برابر توان عملیاتی بالاتری را در حال حاضر مشاهده می کنیم. در خوشههای گرافیکی NVIDIA با اتصال پهنای باند کم (بدون NVIDIA NVLink یا Infiniband)، ما به بهبود توان عملیاتی 3.75 برابری نسبت به استفاده از Megatron-LM به تنهایی برای یک مدل استاندارد GPT-2 با 1.5 میلیارد پارامتر دست پیدا کردیم. در خوشههای NVIDIA DGX-2 با اتصال پهنای باند بالا، برای مدلهایی با 20 تا 80 میلیارد پارامتر، سه تا پنج برابر سریعتر هستیم.
- هزینه: توان عملیاتی بهبود یافته را می توان به کاهش قابل توجه هزینه آموزش ترجمه کرد. به عنوان مثال، برای آموزش مدلی با 20 میلیارد پارامتر، DeepSpeed به سه برابر منابع کمتری نیاز دارد.
- قابلیت استفاده: برای فعال کردن یک مدل PyTorch برای استفاده از DeepSpeed و ZeRO فقط به چند خط تغییر کد نیاز است. در مقایسه با کتابخانههای موازی مدل فعلی، DeepSpeed نیازی به طراحی مجدد کد یا بازسازی مدل ندارد.
مایکروسافت هم DeepSpeed و هم ZeRO را منبع باز است، می توانید آن را بررسی کنید اینجا در GitHub.
منبع: مایکروسافت