Microsoft demuestra que GPT-4 puede vencer a Google Gemini Ultra utilizando nuevas técnicas de indicación
![]() 2 minuto. leer
2 minuto. leer
![]() Publicado el
Publicado el
Compartir este artículo

Mejorar esta guía
Lea nuestra página de divulgación para descubrir cómo puede ayudar a MSPoweruser a sostener el equipo editorial. Leer más
La semana pasada, Google anunció Gemini, su modelo más capaz y general hasta el momento. El modelo Google Gemini ofrece un rendimiento de última generación en muchos puntos de referencia líderes. Google destacó que el rendimiento del modelo Gemini Ultra más capaz supera los resultados de OpenAI GPT-4 en 30 de los 32 puntos de referencia académicos ampliamente utilizados en la investigación y el desarrollo de modelos de lenguajes grandes (LLM).
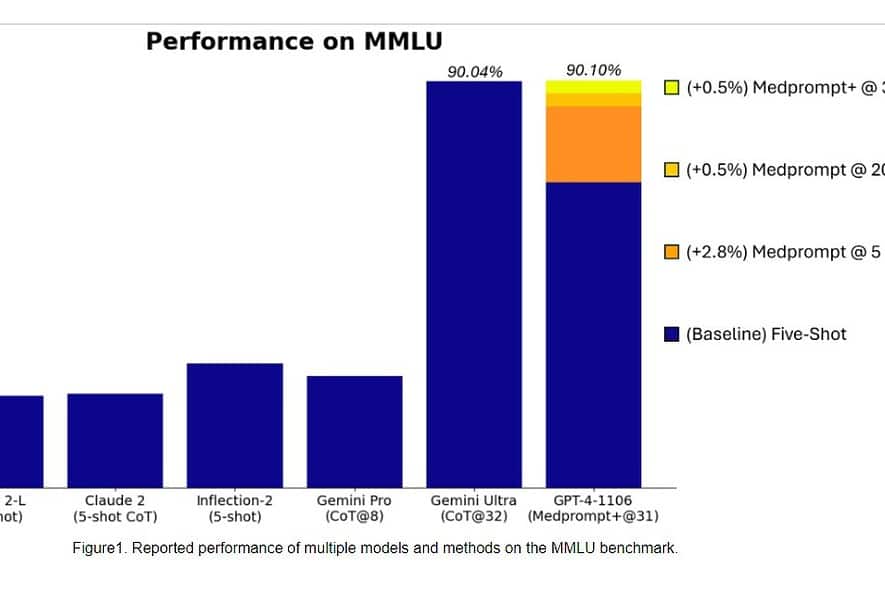
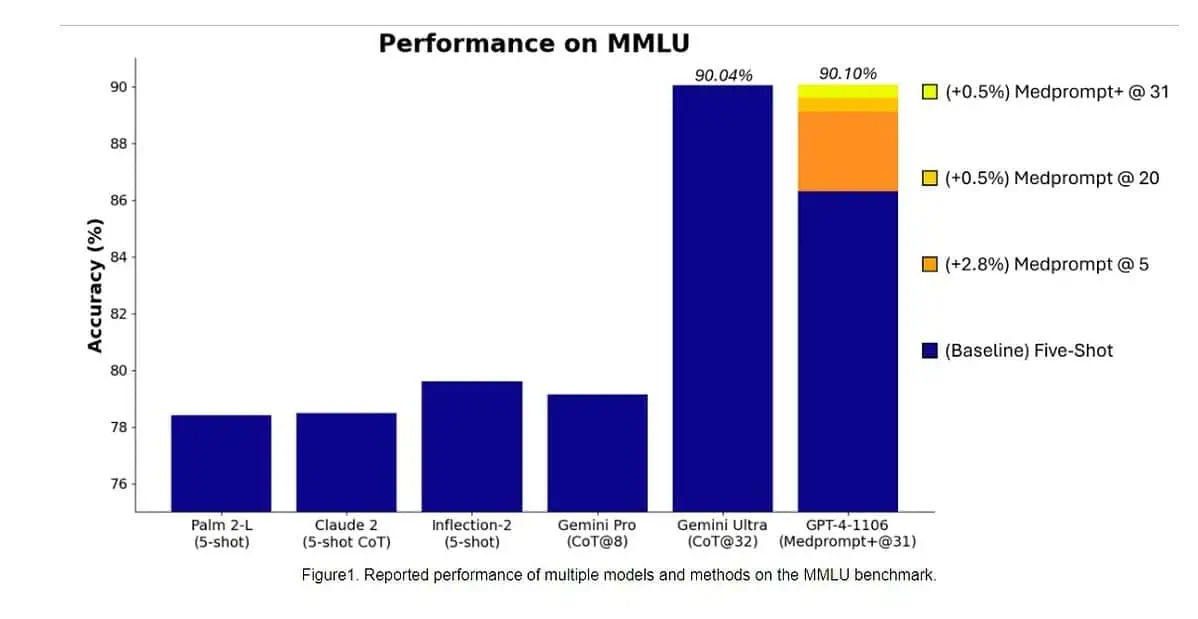
Específicamente, Gemini Ultra se convirtió en el primer modelo en superar a los expertos humanos en MMLU (comprensión masiva de lenguajes multitarea) con una puntuación del 90%, que utiliza una combinación de 57 materias como matemáticas, física, historia, derecho, medicina y ética para evaluar el conocimiento mundial. y habilidades para resolver problemas.
Ayer, el equipo de investigación de Microsoft revelado que el modelo GPT-4 de OpenAI puede vencer a Google Gemini Ultra cuando se utilizan nuevas técnicas de indicación. El mes pasado, Microsoft Research reveló Medprompt, una composición de varias estrategias de estimulación que mejora en gran medida el rendimiento de GPT-4 y logra resultados de última generación en la suite MultiMedQA. Microsoft ahora también ha aplicado las técnicas de solicitud utilizadas en Medprompt para dominios generales. Según Microsoft, el modelo GPT-4 de OpenAI, cuando se utiliza con una versión modificada de Medprompt, logra la puntuación más alta jamás alcanzada en la MMLU completa. Sí, OpenAI GPT-4 puede vencer al próximo modelo Gemini Ultra simplemente usando las técnicas de indicación. Esto demuestra que aún no hemos alcanzado todo el potencial de los modelos ya lanzados como el GPT-4.
Eche un vistazo a la comparación comparativa entre los modelos GPT-4 (indicaciones mejoradas) y Gemini Ultra a continuación.
| Aviso GPT-4 | Resultados de GPT-4 | Resultados de Géminis Ultra | |
|---|---|---|---|
| MMLU | Aviso médico+ | 90.10% | 90.04% |
| GSM8K | Disparo cero | 95.27% | 94.4% |
| MATEMÁTICAS | Disparo cero | 68.42% | 53.2% |
| evaluación humana | Disparo cero | 87.8% | 74.4% |
| GRANDE-banco-duro | Pocos disparos + CoT* | 89.0% | 83.6% |
| DROP | Tiro cero + CoT | 83.7% | 82.4% |
| hellaswag | 10 disparos** | 95.3% | 87.8% |
Primero, Microsoft aplicó el Medprompt original a GPT-4 para lograr una puntuación del 89.1% en MMLU. Posteriormente, Microsoft aumentó el número de llamadas agrupadas en Medprompt de cinco a 20, lo que llevó a un aumento de puntuación del 89.56%. Posteriormente, Microsoft extendió Medprompt a Medprompt+ agregando un método de solicitud más simple y formulando una política para derivar una respuesta final integrando resultados tanto de la estrategia base de Medprompt como de las indicaciones simples. Esto llevó a GPT-4 a alcanzar una puntuación récord del 90.10%. El equipo de investigación de Microsoft mencionó que el equipo de Google Gemini también estaba utilizando una técnica de indicaciones similar para lograr puntuaciones récord en MMLU.
Puede obtener más información sobre las técnicas de indicación que utilizó Microsoft para vencer a Gemini Ultra. esta página.