Microsoft publica un análisis de la causa raíz de los grandes problemas de inicio de sesión de Microsoft 365 de esta semana
![]() 6 minuto. leer
6 minuto. leer
![]() Actualizado en
Actualizado en
Compartir este artículo

Mejorar esta guía
Lea nuestra página de divulgación para descubrir cómo puede ayudar a MSPoweruser a sostener el equipo editorial. Leer más
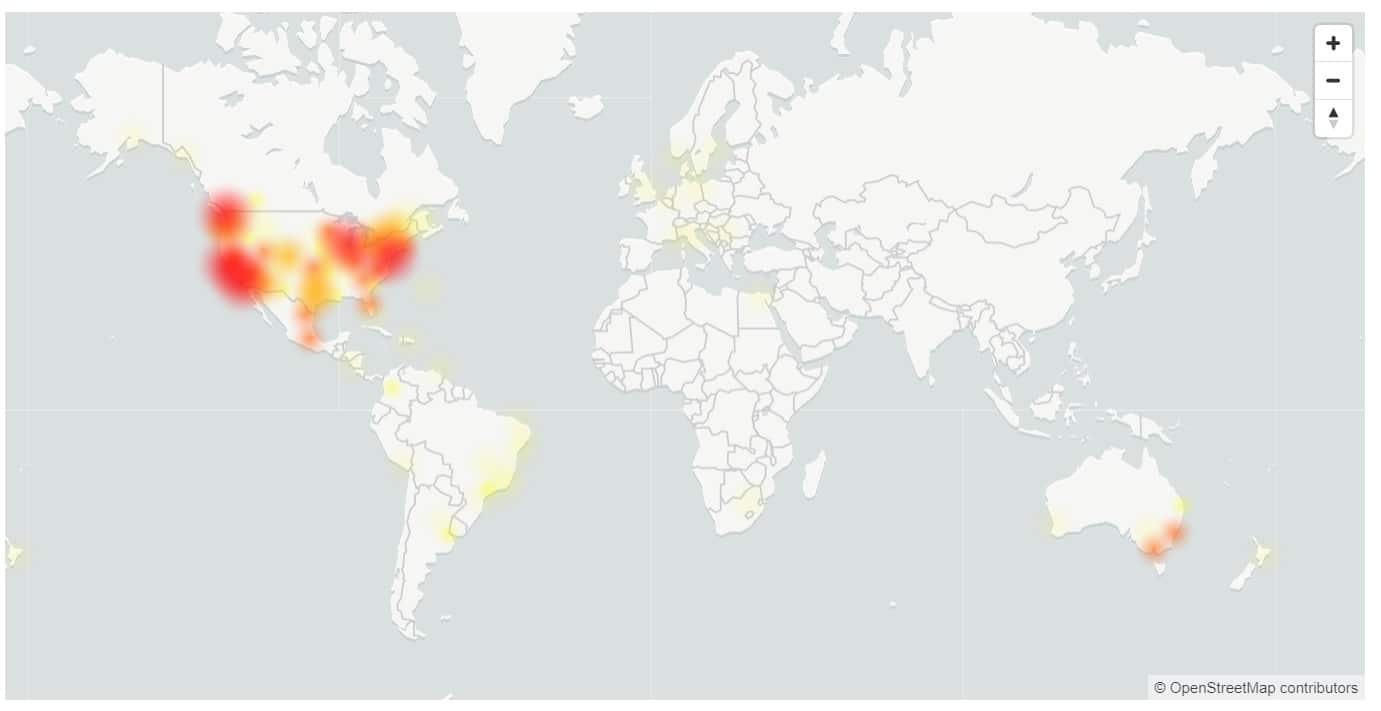
Esta semana tuvimos un tiempo de inactividad de casi 5 horas para Microsoft 365, con usuarios que no pueden iniciar sesión en múltiples servicios, incluidos OneDrive y Microsoft Teams.
Hoy Microsoft publicó un análisis de la causa raíz del problema, que, según Microsoft, se debió a una actualización del servicio que estaba destinada a un anillo de prueba de validación interna, pero que, en cambio, se implementó directamente en el entorno de producción de Microsoft debido a un defecto de código latente en el sistema de proceso de implementación segura (SDP) del servicio backend de Azure AD.
Microsoft dice que entre aproximadamente las 21:25 UTC del 28 de septiembre de 2020 y las 00:23 UTC del 29 de septiembre de 2020, los clientes encontraron errores al realizar operaciones de autenticación para todas las aplicaciones y servicios de Microsoft y de terceros que dependen de Azure Active Directory (Azure AD ) para la autenticación. El problema solo se mitigó por completo para todos a las 2:25 del día siguiente.
EE. UU. y Australia fueron los más afectados, ya que solo el 17 % de los usuarios de EE. UU. pudieron iniciar sesión correctamente.
El problema se agravó porque Microsoft no pudo revertir la actualización debido al defecto latente en su sistema SDP que corrompió los metadatos de implementación, lo que significa que la actualización tuvo que revertirse manualmente.
Microsoft se disculpó con los clientes afectados y dijo que continúan tomando medidas para mejorar la plataforma Microsoft Azure y sus procesos para ayudar a garantizar que tales incidentes no ocurran en el futuro. Uno de los pasos planificados incluye la aplicación de protecciones adicionales al sistema SDP de back-end del servicio Azure AD para evitar la clase de problemas identificados.
Lea el análisis completo a continuación:
RCA: errores de autenticación en varios servicios de Microsoft y aplicaciones integradas de Azure Active Directory (ID de seguimiento SM79-F88)
Resumen del impacto: Aproximadamente entre las 21:25 UTC del 28 de septiembre de 2020 y las 00:23 UTC del 29 de septiembre de 2020, es posible que los clientes hayan encontrado errores al realizar operaciones de autenticación para todas las aplicaciones y servicios de Microsoft y de terceros que dependen de Azure Active Directory (Azure AD) para la autenticación. Las aplicaciones que usan Azure AD B2C para la autenticación también se vieron afectadas.
Los usuarios que aún no estaban autenticados en los servicios en la nube mediante Azure AD tenían más probabilidades de experimentar problemas y es posible que hayan visto múltiples fallas en las solicitudes de autenticación correspondientes a los números de disponibilidad promedio que se muestran a continuación. Estos se han agregado a través de diferentes clientes y cargas de trabajo.
- Europa: 81 % de tasa de éxito durante la duración del incidente.
- América: tasa de éxito del 17 % durante la duración del incidente, mejorando al 37 % justo antes de la mitigación.
- Asia: 72% de tasa de éxito en los primeros 120 minutos del incidente. Cuando comenzó el tráfico pico en horario comercial, la disponibilidad se redujo a un 32 % en su nivel más bajo.
- Australia: tasa de éxito del 37% durante la duración del incidente.
El servicio se restableció a la disponibilidad operativa normal para la mayoría de los clientes a las 00:23 UTC del 29 de septiembre de 2020; sin embargo, observamos fallas poco frecuentes en las solicitudes de autenticación que pueden haber afectado a los clientes hasta las 02:25 UTC.
Los usuarios que se habían autenticado antes de la hora de inicio del impacto tenían menos probabilidades de experimentar problemas según las aplicaciones o los servicios a los que accedían.
Las medidas de resiliencia implementan servicios de identidades administradas protegidas para máquinas virtuales, conjuntos de escalado de máquinas virtuales y Azure Kubernetes Services con una disponibilidad promedio del 99.8 % durante la duración del incidente.
Causa principal: El 28 de septiembre a las 21:25 UTC, se implementó una actualización de servicio dirigida a un anillo de prueba de validación interno, lo que provocó un bloqueo al iniciarse en los servicios de back-end de Azure AD. Un defecto de código latente en el sistema de proceso de implementación segura (SDP) del servicio back-end de Azure AD hizo que esto se implementara directamente en nuestro entorno de producción, sin pasar por nuestro proceso de validación normal.
Azure AD está diseñado para ser un servicio distribuido geográficamente implementado en una configuración activo-activo con varias particiones en varios centros de datos de todo el mundo, creado con límites de aislamiento. Normalmente, los cambios se dirigen inicialmente a un anillo de validación que no contiene datos de clientes, seguido de un anillo interno que contiene solo usuarios de Microsoft y, por último, nuestro entorno de producción. Estos cambios se implementan en fases en cinco anillos durante varios días.
En este caso, el sistema SDP no pudo apuntar correctamente al anillo de prueba de validación debido a un defecto latente que afectó la capacidad del sistema para interpretar los metadatos de implementación. En consecuencia, todos los anillos fueron atacados al mismo tiempo. La implementación incorrecta hizo que la disponibilidad del servicio se degradara.
A los pocos minutos del impacto, tomamos medidas para revertir el cambio utilizando sistemas de reversión automatizados que normalmente habrían limitado la duración y la gravedad del impacto. Sin embargo, el defecto latente en nuestro sistema SDP había corrompido los metadatos de implementación y tuvimos que recurrir a procesos de reversión manual. Esto extendió significativamente el tiempo para mitigar el problema.
Mitigación: Nuestro monitoreo detectó la degradación del servicio a los pocos minutos del impacto inicial y nos comprometimos de inmediato a iniciar la resolución de problemas. Se llevaron a cabo las siguientes actividades de mitigación:
- El impacto comenzó a las 21:25 UTC, y en 5 minutos nuestro monitoreo detectó una condición insalubre y la ingeniería se comprometió de inmediato.
- Durante los siguientes 30 minutos, junto con la resolución del problema, se llevaron a cabo una serie de pasos para intentar minimizar el impacto en el cliente y acelerar la mitigación. Esto incluyó el escalado proactivo de algunos de los servicios de Azure AD para manejar la carga anticipada una vez que se hubiera aplicado una mitigación y la conmutación por error de ciertas cargas de trabajo a un sistema de autenticación de Azure AD de respaldo.
- A las 22:02 UTC, establecimos la causa raíz, comenzamos la remediación e iniciamos nuestros mecanismos de reversión automatizados.
- La reversión automática falló debido a la corrupción de los metadatos de SDP. A las 22:47 UTC iniciamos el proceso para actualizar manualmente la configuración del servicio que omite el sistema SDP, y toda la operación se completó a las 23:59 UTC.
- A las 00:23 UTC, suficientes instancias de servicio de backend regresaron a un estado saludable para alcanzar los parámetros operativos normales del servicio.
- Todas las instancias de servicio con impacto residual se recuperaron a las 02:25 UTC.
Proximos Pasos Nos disculpamos sinceramente por el impacto en los clientes afectados. Tomamos medidas continuamente para mejorar la plataforma Microsoft Azure y nuestros procesos para ayudar a garantizar que tales incidentes no ocurran en el futuro. En este caso, esto incluye (pero no se limita a) lo siguiente:
ya hemos completado
- Se corrigió el defecto de código latente en el sistema SDP de back-end de Azure AD.
- Se corrigió el sistema de reversión existente para permitir la restauración de los últimos metadatos buenos conocidos para proteger contra la corrupción.
- Ampliar el alcance y la frecuencia de los simulacros de operaciones de reversión.
Los pasos restantes incluyen
- Aplique protecciones adicionales al sistema SDP de back-end del servicio Azure AD para evitar la clase de problemas identificados aquí.
- Acelerar la implementación del sistema de autenticación de copia de seguridad de Azure AD en todos los servicios clave como máxima prioridad para reducir significativamente el impacto de un tipo de problema similar en el futuro.
- Incorpore escenarios de Azure AD a la canalización de comunicaciones automatizadas que publica la comunicación inicial a los clientes afectados dentro de los 15 minutos posteriores al impacto.
Suministre realimentación: Ayúdenos a mejorar la experiencia de comunicación con los clientes de Azure completando nuestra encuesta: https://aka.ms/AzurePIRSurvey
vía ZDNet