Conozca Microsoft DeepSpeed, una nueva biblioteca de aprendizaje profundo que puede entrenar modelos masivos de 100 mil millones de parámetros
![]() 2 minuto. leer
2 minuto. leer
![]() Actualizado en
Actualizado en
Compartir este artículo

Mejorar esta guía
Lea nuestra página de divulgación para descubrir cómo puede ayudar a MSPoweruser a sostener el equipo editorial. Leer más
Microsoft Research anunció hoy DeepSpeed, una nueva biblioteca de optimización de aprendizaje profundo que puede entrenar modelos masivos de 100 mil millones de parámetros. En IA, debe tener modelos de lenguaje natural más grandes para una mayor precisión. Pero entrenar modelos de lenguaje natural más grandes requiere mucho tiempo y los costos asociados son muy altos. Microsoft afirma que la nueva biblioteca de aprendizaje profundo DeepSpeed mejora la velocidad, el costo, la escala y la usabilidad.
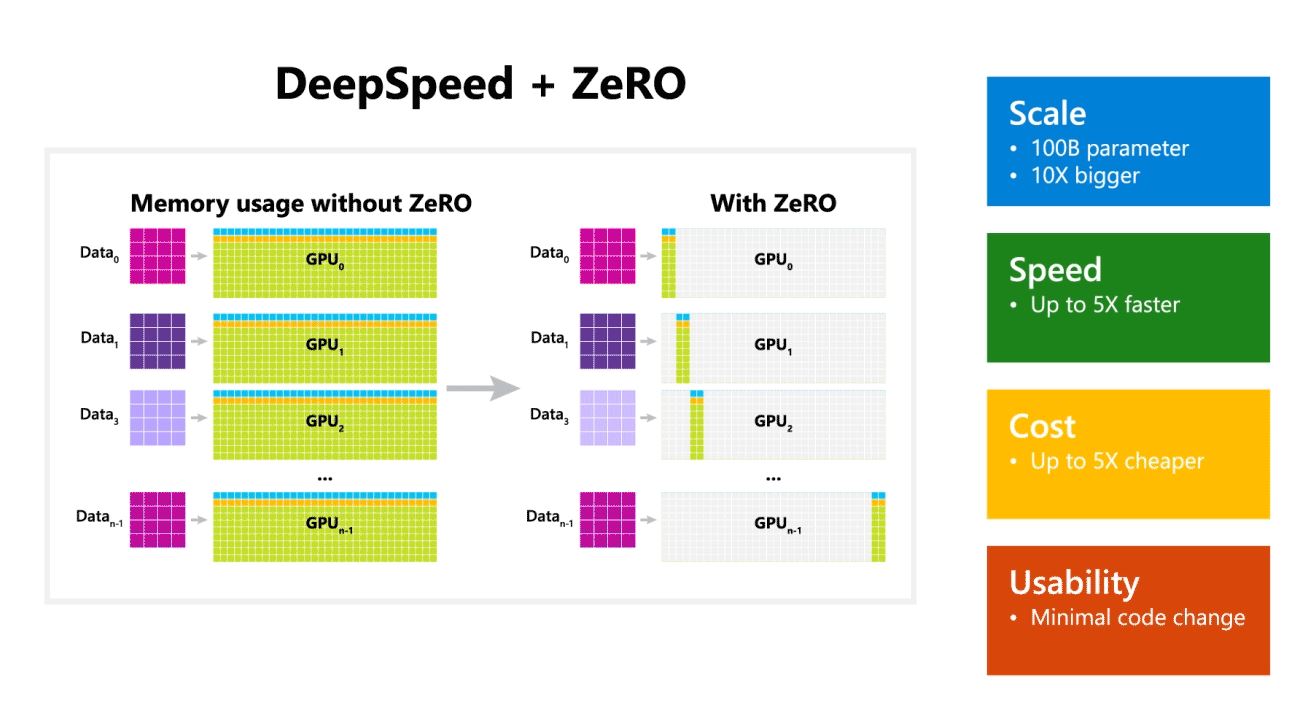
Microsoft también mencionó que DeepSpeed habilita modelos de lenguaje con modelos de hasta 100 mil millones de parámetros e incluye ZeRO (Zero Redundancy Optimizer), un optimizador paralelizado que reduce los recursos necesarios para el modelo y el paralelismo de datos al tiempo que aumenta la cantidad de parámetros que se pueden entrenar. . Usando DeepSpeed y ZeRO, los investigadores de Microsoft han desarrollado la nueva generación de lenguaje natural de Turing (Turing-NLG), el modelo de lenguaje más grande con 17 mil millones de parámetros.
Aspectos destacados de DeepSpeed:
- Escala: Los modelos grandes de última generación como OpenAI GPT-2, NVIDIA Megatron-LM y Google T5 tienen tamaños de 1.5 millones, 8.3 millones y 11 millones de parámetros respectivamente. La etapa uno de ZeRO en DeepSpeed brinda soporte del sistema para ejecutar modelos de hasta 100 mil millones de parámetros, 10 veces más grandes.
- Velocidad: Observamos un rendimiento hasta cinco veces mayor que el de última generación en varios hardware. En los clústeres de GPU de NVIDIA con interconexión de bajo ancho de banda (sin NVIDIA NVLink o Infiniband), logramos una mejora del rendimiento de 3.75 veces con respecto al uso de Megatron-LM solo para un modelo GPT-2 estándar con 1.5 millones de parámetros. En los clústeres NVIDIA DGX-2 con interconexión de alto ancho de banda, para modelos de 20 a 80 mil millones de parámetros, somos de tres a cinco veces más rápidos.
- Cost: El rendimiento mejorado se puede traducir en costos de capacitación significativamente reducidos. Por ejemplo, para entrenar un modelo con 20 mil millones de parámetros, DeepSpeed requiere tres veces menos recursos.
- usabilidad: solo se necesitan unas pocas líneas de cambios de código para permitir que un modelo de PyTorch use DeepSpeed y ZeRO. En comparación con las bibliotecas de paralelismo de modelos actuales, DeepSpeed no requiere un rediseño de código ni una refactorización de modelos.
Microsoft es de código abierto tanto para DeepSpeed como para ZeRO, puede comprobarlo aquí en GitHub.
Fuente: Microsoft