Microsoft beweist, dass GPT-4 mithilfe neuer Eingabeaufforderungstechniken Google Gemini Ultra schlagen kann
![]() 2 Minute. lesen
2 Minute. lesen
![]() Veröffentlicht am
Veröffentlicht am
Teile diesen Artikel

Verbessern Sie diesen Leitfaden
Lesen Sie unsere Offenlegungsseite, um herauszufinden, wie Sie MSPoweruser dabei helfen können, das Redaktionsteam zu unterstützen Lesen Sie weiter
Letzte Woche hat Google angekündigt Gemini, sein bisher leistungsfähigstes und allgemeinstes Modell. Das Google Gemini-Modell bietet hochmoderne Leistung in vielen führenden Benchmarks. Google betonte, dass die Leistung des leistungsfähigsten Gemini Ultra-Modells die Ergebnisse von OpenAI GPT-4 bei 30 der 32 weit verbreiteten akademischen Benchmarks übertrifft, die in der Forschung und Entwicklung von Large Language Models (LLM) verwendet werden.
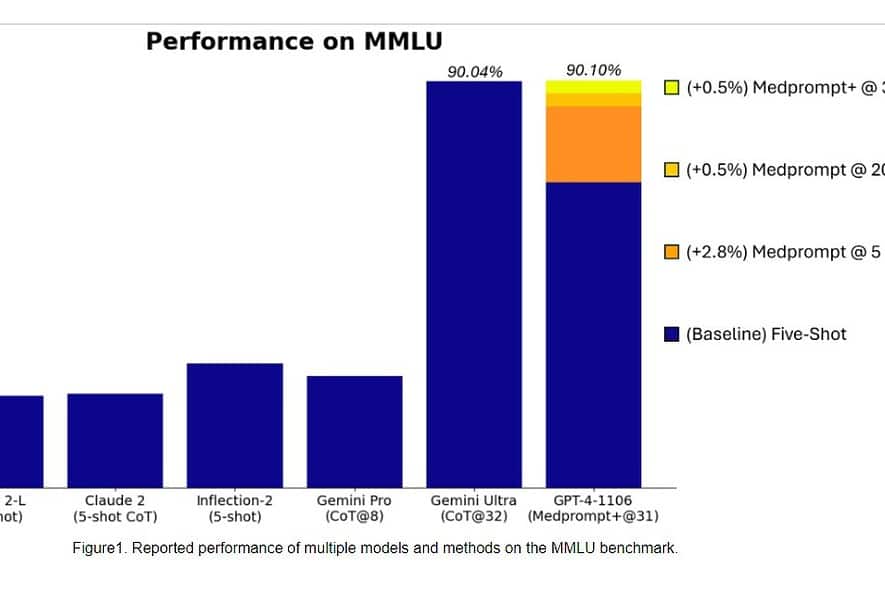
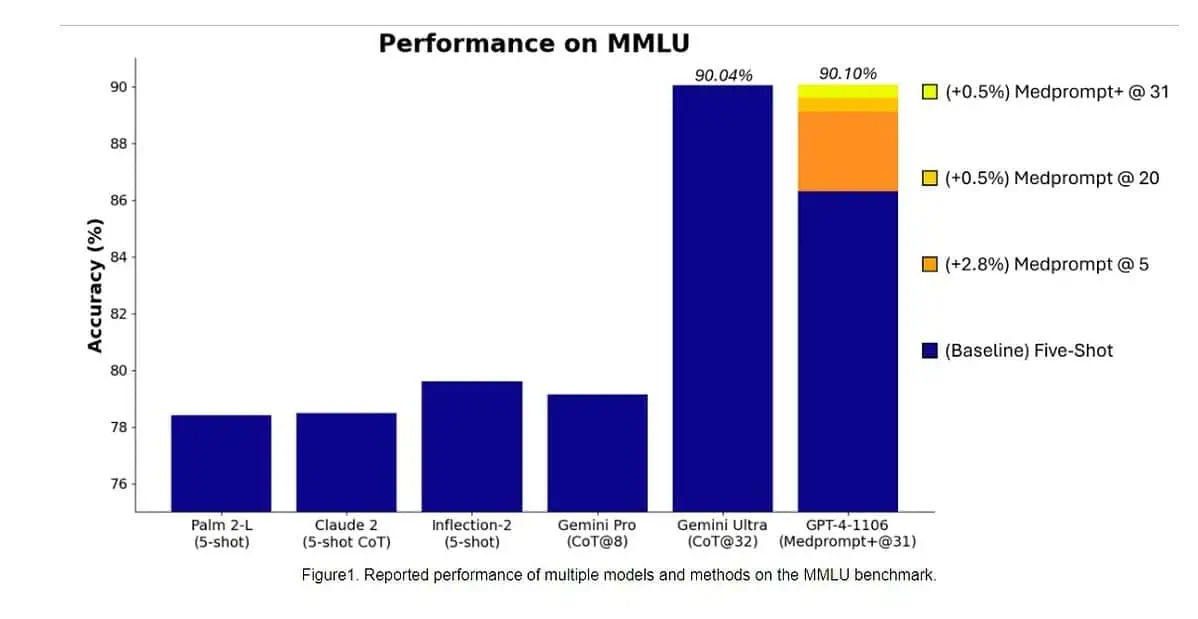
Konkret war Gemini Ultra das erste Modell, das menschliche Experten im MMLU (Massive Multitask Language Understanding) mit einer Punktzahl von 90 % übertraf, wobei eine Kombination aus 57 Fächern wie Mathematik, Physik, Geschichte, Recht, Medizin und Ethik zum Testen beider Weltkenntnisse verwendet wird und Problemlösungsfähigkeiten.
Gestern, Microsoft Research-Team enthüllt dass das GPT-4-Modell von OpenAI Google Gemini Ultra schlagen kann, wenn neue Eingabeaufforderungstechniken verwendet werden. Letzten Monat enthüllte Microsoft Research Medprompt, eine Zusammenstellung mehrerer Aufforderungsstrategien, die die Leistung von GPT-4 erheblich verbessert und modernste Ergebnisse in der MultiMedQA-Suite erzielt. Microsoft hat die in Medprompt verwendeten Eingabeaufforderungstechniken nun auch für allgemeine Domänen angewendet. Laut Microsoft erreicht das GPT-4-Modell von OpenAI bei Verwendung mit einer modifizierten Version von Medprompt die höchste Punktzahl, die jemals auf der gesamten MMLU erreicht wurde. Ja, OpenAI GPT-4 kann das kommende Gemini Ultra-Modell allein durch die Verwendung der Eingabeaufforderungstechniken schlagen. Dies zeigt, dass wir das volle Potenzial bereits veröffentlichter Modelle wie GPT-4 noch nicht ausgeschöpft haben.
Schauen Sie sich unten den Benchmark-Vergleich zwischen GPT-4 (verbesserte Eingabeaufforderungen) und den Gemini Ultra-Modellen an.
| Benchmark | GPT-4-Eingabeaufforderung | GPT-4-Ergebnisse | Gemini Ultra-Ergebnisse |
|---|---|---|---|
| MMLU | Medprompt+ | 90.10% | 90.04% |
| GSM8K | Nullschuss | 95.27% | 94.4% |
| MATHE | Nullschuss | 68.42% | 53.2% |
| HumanEval | Nullschuss | 87.8% | 74.4% |
| BIG-Bank-Hart | Wenige Schuss + CoT* | 89.0% | 83.6% |
| DROP | Nullschuss + CoT | 83.7% | 82.4% |
| HellaSwag | 10 Schuss** | 95.3% | 87.8% |
Zunächst wendete Microsoft das ursprüngliche Medprompt auf GPT-4 an, um in MMLU einen Wert von 89.1 % zu erreichen. Später erhöhte Microsoft die Anzahl der zusammengefassten Anrufe in Medprompt von fünf auf 20, was zu einer höheren Punktzahl von 89.56 % führte. Microsoft erweiterte Medprompt später zu Medprompt+, indem es eine einfachere Eingabeaufforderungsmethode hinzufügte und eine Richtlinie zum Ableiten einer endgültigen Antwort formulierte, indem es Ergebnisse sowohl der Basis-Medprompt-Strategie als auch der einfachen Eingabeaufforderungen integrierte. Dies führte dazu, dass GPT-4 einen Rekordwert von 90.10 % erreichte. Das Microsoft-Forschungsteam erwähnte, dass das Google-Gemini-Team ebenfalls eine ähnliche Aufforderungstechnik verwendete, um die Rekordergebnisse bei MMLU zu erzielen.
Erfahren Sie mehr über die Aufforderungstechniken, mit denen Microsoft Gemini Ultra besiegt hat hier.