Generátor převodu textu na obrázek společnosti Google Imagen vytváří obrázky s „bezprecedentním stupněm fotorealismu“
![]() 3 min. číst
3 min. číst
![]() Publikované dne
Publikované dne
Sdílejte tento článek

Vylepšete tuto příručku
Přečtěte si naši informační stránku a zjistěte, jak můžete pomoci MSPoweruser udržet redakční tým Dozvědět se více
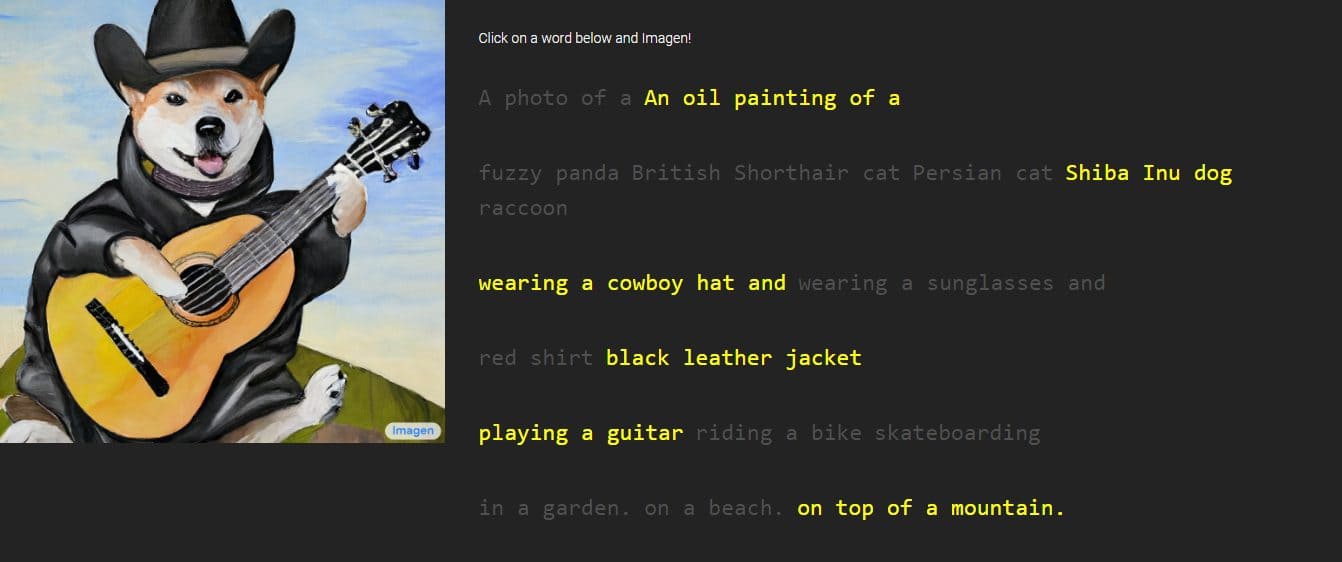
Google odhalil nový výtvor s názvem „Obraz,“ generátor textu na obrázek prostřednictvím popisů, které osoba poskytne. Společnost tvrdí, že překonává výkon DALL-E 2, dalšího generátoru obrazu AI. Představil několik vzorků, které nepopiratelně vykazují nádherné detaily, ale Imagen je v současné době pro veřejnost nedostupný.
Popisuje se, že nový model difúze textu do obrázku má „bezprecedentní stupeň fotorealismu a hlubokou úroveň porozumění jazyku“. Rozumí textu prostřednictvím velkých modelů jazyka transformátoru a říká se, že při generování vysoce věrného obrazu spoléhá na difúzní modely.

Google poskytl obrázky a ukázky Imagenových prací se styly od kreseb po olejomalby a CGI. Jsou doprovázeny slovy a frázemi použitými k jejich vytvoření. Například jeden vzorek zní „dračí ovoce s pásem karate ve sněhu“, zatímco druhý má popis „malý kaktus se slaměným kloboukem a neonovými slunečními brýlemi v saharské poušti“.
Vygenerované obrázky vypadají neuvěřitelně reálně, jako by je vytvořila skutečná osoba. Google však říká, že se to děje prostřednictvím difúzních technologií s využitím čistého šumového obrazu a jeho vylepšením tím nejlepším možným způsobem. Po pochopení poskytnutého textového popisu Imagen vygeneruje obrázek o velikosti 64 x 64 pixelů, provede dvě vylepšení a převede obrázek na větší kus s rozlišením 1024 x 1024 pixelů.
Google Research, Brain Team říká, že Imagen exceloval Kokos (rozsáhlá datová sada pro detekci, segmentaci a titulkování objektů), přestože na ní nejste školeni. Tým oznámil, že obdržel nové nejmodernější skóre FID 7.27.
Google také porovnal výkon Imagen s jinými modely převodu textu na obrázek jejich posouzením pomocí nástroje „DrawBench“. Slouží jako benchmark pro modely text-to-image, kde Google testoval Imagen s dalšími metodami, jako je VQ-GAN+CLIP, Latent Diffusion Models a DALL-E 2. text, vzácná slova a náročné výzvy, tým uvedl, že „lidští hodnotitelé silně preferují Imagen před jinými metodami, a to jak v zarovnání obrázku-textu, tak ve věrnosti obrázku“.
Navzdory těmto působivým zprávám od výzkumného týmu nebude testování Imagen sami možné, protože není přístupné veřejnosti. Google pro to má důvody, jako jsou etické výzvy, potenciální rizika zneužití, sociální předsudky, omezení velkých jazykových modelů a riziko zakódovaných škodlivých stereotypů a reprezentací. Tým shrnuje, že se všemi těmito výzvami není Imagen stále dokonalý, pokud jde o generování obrázků souvisejících s lidmi.
„Imagen vykazuje vážná omezení při generování obrázků zobrazujících lidi,“ vysvětluje tým v příspěvku na blogu. „Naše lidské hodnocení zjistilo, že Imagen získává výrazně vyšší preferenční míry, když je hodnocen na snímcích, které nezobrazují lidi, což ukazuje na zhoršení věrnosti obrazu. Předběžné hodnocení také naznačuje, že Imagen kóduje několik společenských předsudků a stereotypů, včetně celkové předpojatosti k vytváření obrazů lidí se světlejším odstínem pleti a tendence, aby obrazy zobrazující různé profese odpovídaly západním genderovým stereotypům. A konečně, i když se zaměříme na generace od lidí, naše předběžná analýza naznačuje, že Imagen kóduje řadu sociálních a kulturních předsudků při generování obrazů aktivit, událostí a objektů. Naším cílem je pokročit v několika z těchto otevřených výzev a omezení v budoucí práci.“