微軟和英偉達宣布迄今為止訓練過的最大和最強大的語言模型
![]() 1分鐘讀
1分鐘讀
![]() 發表於
發表於
分享此文章

改進本指南
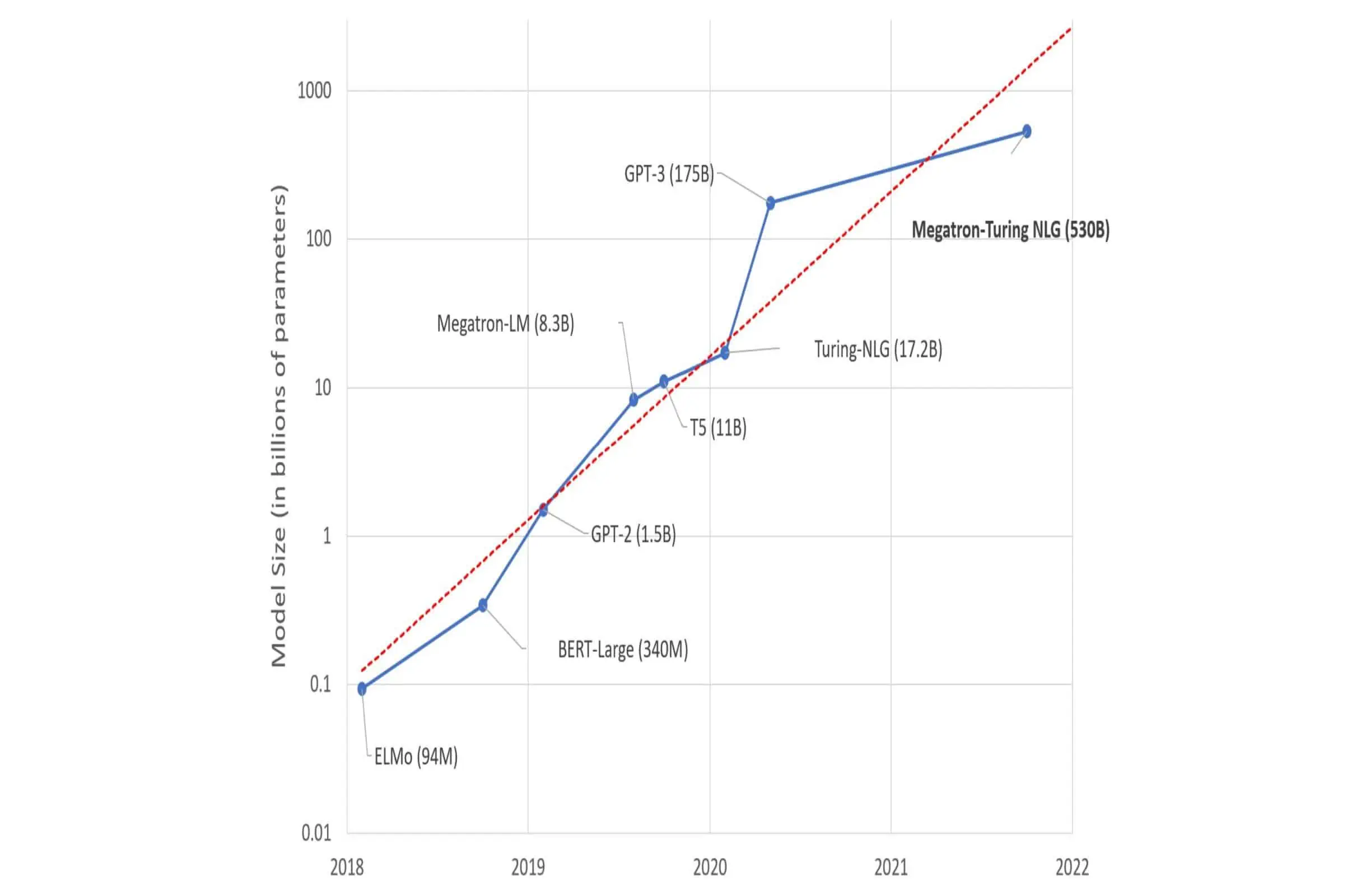
微軟和英偉達今天宣布了由 DeepSpeed 和 Megatron 提供支持的 Megatron-Turing 自然語言生成模型 (MT-NLG),這是迄今為止訓練過的最大和最強大的單片 Transformer 語言模型。 該模型包含 530 億個參數,參數數量是現有最大模型 GPT-3 的 3 倍。 訓練如此大的模型涉及各種挑戰。 NVIDIA 和 Microsoft 在所有 AI 軸上進行了許多創新和突破。
例如,通過緊密合作,NVIDIA 和 Microsoft 通過將最先進的 GPU 加速訓練基礎設施與尖端分佈式學習軟件堆棧相結合,實現了前所未有的訓練效率。 我們構建了具有數千億令牌的高質量自然語言訓練語料庫,並共同開發了訓練配方,以提高優化效率和穩定性。
您可以從下面的鏈接中了解有關此項目的更多信息。
資源: Microsoft微軟, Nvidia公司







