微軟 DeBERTa 在 SuperGlue 閱讀理解測試中超越弱小人類
![]() 2分鐘讀
2分鐘讀
![]() 發表於
發表於
分享此文章

改進本指南
最近在訓練具有數百萬個參數的網絡方面取得了巨大進展。 微軟最近更新了 DeBERTa(Decoding-enhanced BERT with disentangled attention)模型,通過訓練一個更大的模型,該模型由 48 個 Transformer 層和 1.5 億個參數組成。 顯著的性能提升使單個 DeBERTa 模型在宏觀平均得分(89.9 對 89.8)方面首次超過了人類在 SuperGLUE 語言處理和理解方面的表現,大大超過了人類基線(90.3 對 89.8) . SuperGLUE 基準測試包含廣泛的自然語言理解任務,包括問答、自然語言推理。 該模型還以 90.8 的宏觀平均得分位居 GLUE 基準排名榜首。
DeBERTa 使用三種新技術改進了以前最先進的 PLM(例如,BERT、RoBERTa、UniLM):一種分離的注意力機制、一種增強的掩碼解碼器和一種用於微調的虛擬對抗訓練方法。
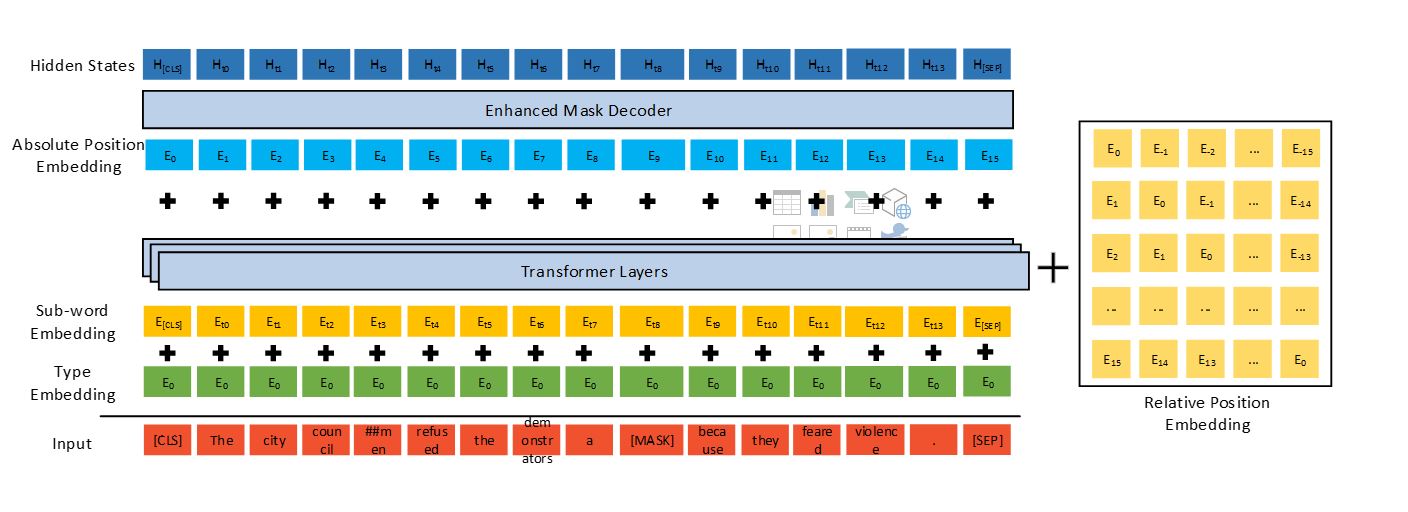
與由 5 億個參數組成的 Google 的 T11 模型相比,1.5 億個參數的 DeBERTa 的訓練和維護效率要高得多,並且更容易壓縮和部署到各種設置的應用程序中。
DeBERTa 在 SuperGLUE 上超越人類的表現標誌著邁向通用 AI 的重要里程碑。 儘管在 SuperGLUE 上取得了可喜的成果,但該模型絕不會達到 NLU 的人類智能水平。 人類非常擅長利用從不同任務中學到的知識來解決新任務,而無需或很少有特定任務的演示。
微軟將把這項技術集成到微軟圖靈自然語言表示模型的下一個版本中,用於必應、Office、Dynamics 和 Azure 認知服務等領域,通過以下方式為涉及人機和人機交互的廣泛場景提供支持自然語言(例如聊天機器人、推薦、問答、搜索、個人協助、客戶支持自動化、內容生成等)。 此外,微軟還將向公眾發布 1.5 億參數的 DeBERTa 模型和源代碼。
閱讀 Microsoft 的所有詳細信息 点击這裡.