認識微軟 DeepSpeed,一個可以訓練海量 100 億參數模型的新深度學習庫
![]() 2分鐘讀
2分鐘讀
![]() 更新了
更新了
分享此文章

改進本指南
微軟研究院今天發布了 DeepSpeed,這是一個新的深度學習優化庫,可以訓練海量 100 億參數模型。 在 AI 中,您需要擁有更大的自然語言模型以獲得更好的準確性。 但是訓練更大的自然語言模型非常耗時,並且與之相關的成本非常高。 微軟聲稱新的 DeepSpeed 深度學習庫提高了速度、成本、規模和可用性。
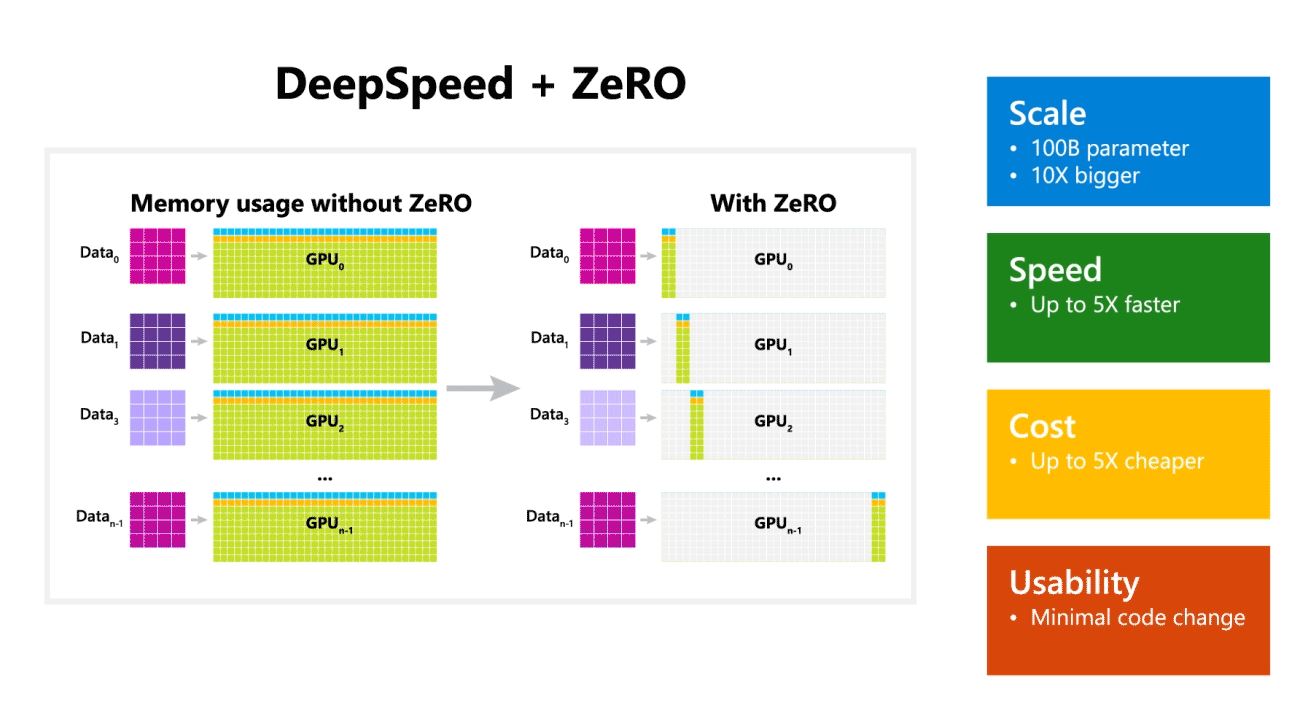
微軟還提到,DeepSpeed 支持具有多達 100 億個參數模型的語言模型,它包括 ZeRO(零冗餘優化器),這是一種並行優化器,可減少模型和數據並行所需的資源,同時增加可訓練的參數數量. 微軟研究人員使用 DeepSpeed 和 ZeRO 開發了新的圖靈自然語言生成 (Turing-NLG),這是最大的語言模型,具有 17 億個參數。
DeepSpeed 的亮點:
- 規模:OpenAI GPT-2、NVIDIA Megatron-LM 和 Google T5 等最先進的大型模型的大小分別為 1.5 億、8.3 億和 11 億個參數。 DeepSpeed 中的 ZeRO 第一階段提供系統支持,可運行多達 100 億個參數的模型,大 10 倍。
- 速度:我們觀察到各種硬件的吞吐量比現有技術高出五倍。 在具有低帶寬互連(沒有 NVIDIA NVLink 或 Infiniband)的 NVIDIA GPU 集群上,對於具有 3.75 億個參數的標準 GPT-2 模型,與單獨使用 Megatron-LM 相比,我們實現了 1.5 倍的吞吐量提升。 在具有高帶寬互連的 NVIDIA DGX-2 集群上,對於 20 到 80 億個參數的模型,我們的速度提高了三到五倍。
- 價格:提高的吞吐量可以轉化為顯著降低的培訓成本。 例如,要訓練一個具有 20 億個參數的模型,DeepSpeed 需要的資源要少三倍。
- 可用性:只需要更改幾行代碼即可使 PyTorch 模型使用 DeepSpeed 和 ZeRO。 與當前的模型並行庫相比,DeepSpeed 不需要重新設計代碼或重構模型。
微軟正在開源 DeepSpeed 和 ZeRO,你可以看看 這裡是GitHub。
資源: Microsoft微軟