谷歌的文本到圖像生成器 Imagen 生成具有“前所未有的真實感”的圖片
![]() 3分鐘讀
3分鐘讀
![]() 發表於
發表於
分享此文章

改進本指南
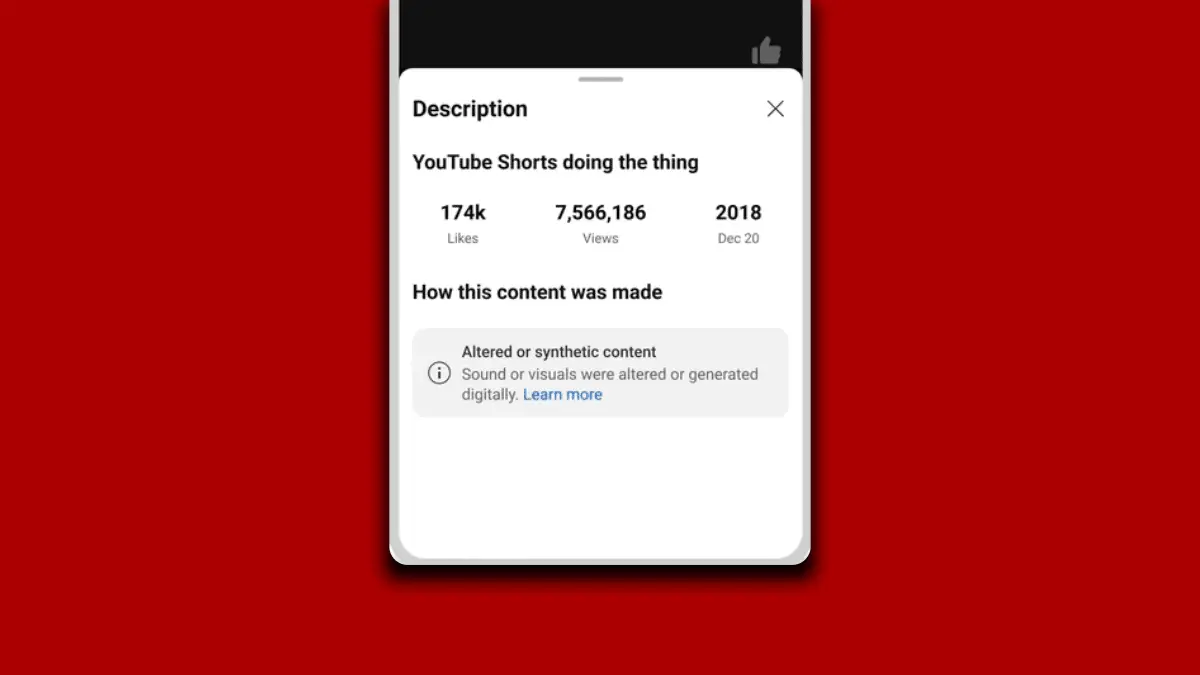
谷歌 推出了一款名為“圖像,”一個文本到圖像的生成器,通過一個人將提供的描述。 該公司聲稱它超越了另一款 AI 圖像生成器 DALL-E 2 的性能。 它展示了一些樣本,無可否認地展示了精緻的細節,但 Imagen 目前無法向公眾開放。
新的文本到圖像擴散模型被描述為“具有前所未有的真實感和深度的語言理解”。 它通過大型 Transformer 語言模型來理解文本,據說依靠擴散模型來執行高保真圖像生成。

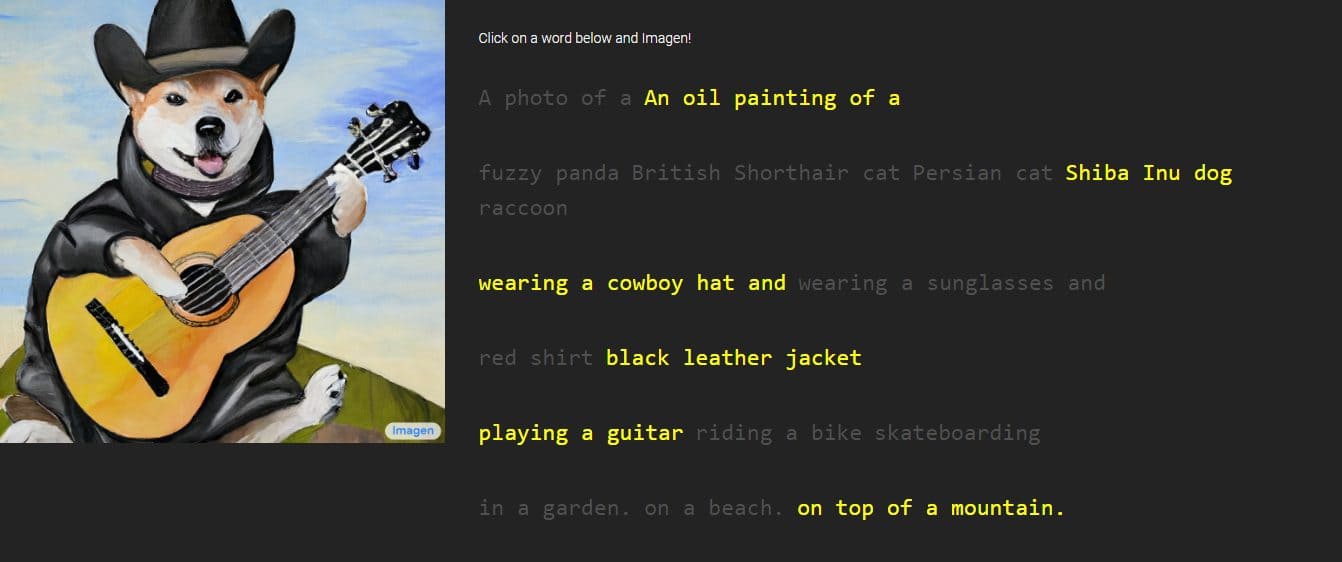
Google 提供了 Imagen 作品的圖像和样本,其風格從素描到油畫和 CGI 不等。 它們伴隨著用於生成它們的單詞和短語。 例如,一個樣本上寫著“在雪地裡戴著空手道腰帶的火龍果”,而另一個樣本上的描述是“撒哈拉沙漠中戴著草帽和霓虹太陽鏡的小仙人掌”。
生成的圖像看起來非常真實,就好像它們是由真人創建的一樣。 然而,谷歌表示,它是通過擴散技術利用純噪聲圖像並以最佳方式對其進行優化來完成的。 通過了解所提供的文本描述,Imagen 將生成一個 64 x 64 像素的圖像,執行兩個增強功能,並將圖像轉換為更大的 1024 x 1024 像素塊。
Google Research,Brain Team 表示 Imagen 在 COCO (一個大規模的對象檢測、分割和字幕數據集)儘管沒有接受過訓練。 該團隊報告說,它獲得了 7.27 的最新 FID 分數。
谷歌還通過使用“DrawBench”評估 Imagen 與其他文本到圖像模型的性能進行比較。 它作為文本到圖像模型的基準,谷歌在其中使用 VQ-GAN+CLIP、潛在擴散模型和 DALL-E 2 等其他方法測試了 Imagen。在測試了它們的組合性、基數、空間關係、長格式之後文本、稀有詞和具有挑戰性的提示,該團隊表示,“在圖像文本對齊和圖像保真度方面,人類評估者更喜歡 Imagen,而不是其他方法。”
儘管研究團隊提供了這些令人印象深刻的報告,但由於公眾無法訪問 Imagen,因此無法自行測試 Imagen。 谷歌這樣做是有原因的,例如道德挑戰、潛在的誤用風險、社會偏見、大型語言模型的局限性以及編碼有害的刻板印象和表示的風險。 該團隊總結說,面對所有這些挑戰,Imagen 在生成與人相關的圖像方面仍然不完美。
“Imagen 在生成描繪人物的圖像時表現出嚴重的局限性,”該團隊在一篇博文中解釋道。 “我們的人工評估發現,在對不描繪人物的圖像進行評估時,Imagen 獲得了顯著更高的偏好率,這表明圖像保真度有所下降。 初步評估還表明,Imagen 編碼了幾種社會偏見和刻板印象,包括總體偏向於生成膚色較淺的人的圖像,以及描繪不同職業的圖像傾向於與西方性別刻板印象保持一致。 最後,即使我們將幾代人的注意力放在遠離人的地方,我們的初步分析表明,Imagen 在生成活動、事件和對象的圖像時編碼了一系列社會和文化偏見。 我們的目標是在未來的工作中在其中一些開放的挑戰和限制上取得進展。”