Microsoft chứng minh GPT-4 có thể đánh bại Google Gemini Ultra bằng kỹ thuật nhắc nhở mới
![]() 2 phút đọc
2 phút đọc
![]() Được đăng trên
Được đăng trên
Chia sẻ bài báo này

Cải thiện hướng dẫn này
Đọc trang tiết lộ của chúng tôi để tìm hiểu cách bạn có thể giúp MSPoweruser duy trì nhóm biên tập Tìm hiểu thêm
Tuần trước, Google đã công bố Gemini, mô hình chung và có khả năng nhất của nó. Mô hình Google Gemini mang lại hiệu suất vượt trội trên nhiều tiêu chuẩn hàng đầu. Google nhấn mạnh rằng hiệu suất của mô hình Gemini Ultra có khả năng cao nhất vượt quá kết quả của OpenAI GPT-4 trên 30 trong số 32 điểm chuẩn học thuật được sử dụng rộng rãi trong nghiên cứu và phát triển mô hình ngôn ngữ lớn (LLM).
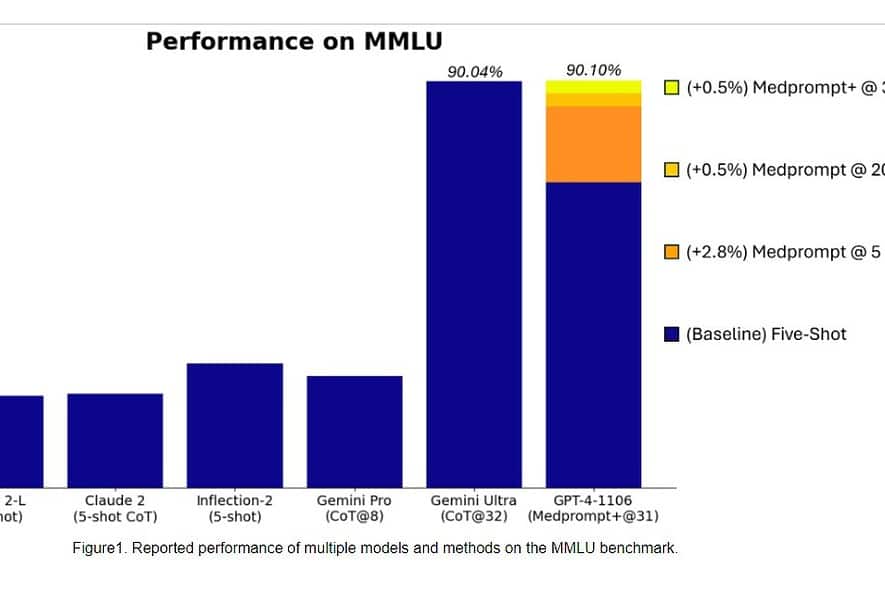
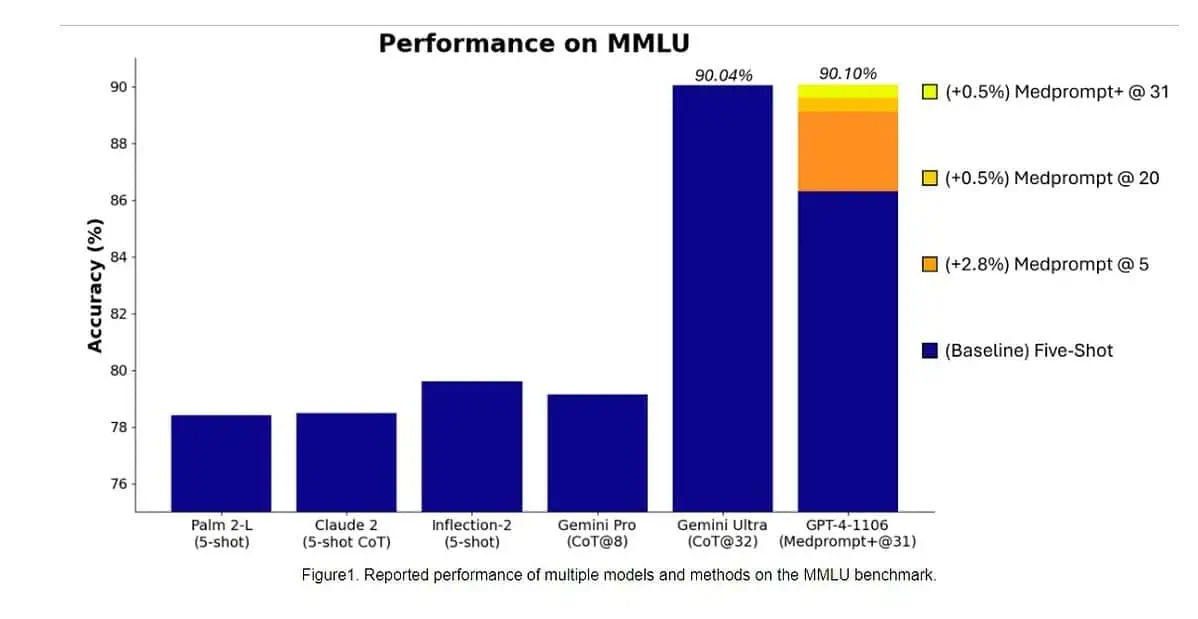
Cụ thể, Gemini Ultra trở thành mô hình đầu tiên vượt trội hơn các chuyên gia con người về MMLU (hiểu ngôn ngữ đa nhiệm lớn) với số điểm 90%, sử dụng kết hợp 57 môn như toán, vật lý, lịch sử, luật, y học và đạo đức để kiểm tra cả kiến thức thế giới. và khả năng giải quyết vấn đề.
Hôm qua, nhóm nghiên cứu của Microsoft tiết lộ rằng mô hình GPT-4 của OpenAI có thể đánh bại Google Gemini Ultra khi sử dụng các kỹ thuật nhắc nhở mới. Tháng trước, Microsoft Research đã tiết lộ Medprompt, sự kết hợp của một số chiến lược thúc đẩy giúp cải thiện đáng kể hiệu suất của GPT-4 và đạt được kết quả hiện đại trong bộ MultiMedQA. Microsoft hiện cũng đã áp dụng các kỹ thuật nhắc nhở được sử dụng trong Medprompt cho các miền chung. Theo Microsoft, mẫu GPT-4 của OpenAI khi sử dụng với phiên bản sửa đổi của Medprompt sẽ đạt được số điểm cao nhất từng đạt được trên MMLU hoàn chỉnh. Có, OpenAI GPT-4 có thể đánh bại mẫu Gemini Ultra sắp ra mắt chỉ bằng cách sử dụng các kỹ thuật nhắc nhở. Điều này cho thấy chúng ta vẫn chưa phát huy hết tiềm năng của những mẫu xe đã ra mắt như GPT-4.
Hãy xem so sánh điểm chuẩn giữa các mẫu GPT-4 (lời nhắc được cải thiện) và mẫu Gemini Ultra bên dưới.
| điểm chuẩn | Lời nhắc GPT-4 | Kết quả GPT-4 | Kết quả siêu Song Tử |
|---|---|---|---|
| MMLU | Medprompt+ | 90.10% | 90.04% |
| GSM8K | bắn không | 95.27% | 94.4% |
| MÔN TOÁN | bắn không | 68.42% | 53.2% |
| con người | bắn không | 87.8% | 74.4% |
| LỚN-Băng-Cứng | Ít ảnh + CoT* | 89.0% | 83.6% |
| Thả | Không bắn + CoT | 83.7% | 82.4% |
| HellaSwag | 10 phát** | 95.3% | 87.8% |
Đầu tiên, Microsoft áp dụng Medprompt ban đầu cho GPT-4 để đạt được số điểm 89.1% trong MMLU. Sau đó, Microsoft đã tăng số lượng cuộc gọi tổng hợp trong Medprompt từ 20 lên 89.56, dẫn đến số điểm tăng lên 4%. Microsoft sau đó đã mở rộng Medprompt thành Medprompt+ bằng cách thêm một phương pháp nhắc nhở đơn giản hơn và xây dựng chính sách để đưa ra câu trả lời cuối cùng bằng cách tích hợp các kết quả đầu ra từ cả chiến lược Medprompt cơ bản và các lời nhắc đơn giản. Điều này khiến GPT-90.10 đạt số điểm kỷ lục XNUMX%. Nhóm Nghiên cứu của Microsoft đã đề cập rằng nhóm Google Gemini cũng đang sử dụng kỹ thuật nhắc nhở tương tự để đạt được số điểm kỷ lục trên MMLU.
Bạn có thể tìm hiểu thêm về các kỹ thuật nhắc nhở mà Microsoft đã sử dụng để đánh bại Gemini Ultra tại đây.