Microsoft DeBERTa överträffar ynkliga människor i SuperGlue läsförståelsetest
![]() 2 min. läsa
2 min. läsa
![]() Publicerad den
Publicerad den
Dela den här artikeln

Förbättra den här guiden
Läs vår informationssida för att ta reda på hur du kan hjälpa MSPoweruser upprätthålla redaktionen Läs mer
Det har skett enorma framsteg nyligen inom utbildningsnätverk med miljontals parametrar. Microsoft uppdaterade nyligen DeBERTa-modellen (Decoding-enhanced BERT with disentangled attention) genom att träna upp en större version som består av 48 transformatorlager med 1.5 miljarder parametrar. Den betydande prestandaökningen gör att den enda DeBERTa-modellen överträffar den mänskliga prestandan på SuperGLUE-språkbehandlingen och förståelsen för första gången i termer av makrogenomsnitt (89.9 mot 89.8), vilket överträffar den mänskliga baslinjen med en anständig marginal (90.3 mot 89.8) . SuperGLUE-riktmärket består av ett brett utbud av naturliga språkförståelseuppgifter, inklusive svar på frågor, naturliga språkinferenser. Modellen ligger också i toppen av GLUE benchmark-rankingen med ett makromedelvärde på 90.8.
DeBERTa förbättrar tidigare toppmoderna PLM:er (till exempel BERT, RoBERTa, UniLM) med hjälp av tre nya tekniker: en uppmärksam uppmärksamhetsmekanism, en förbättrad maskavkodare och en virtuell motstridig träningsmetod för finjustering.
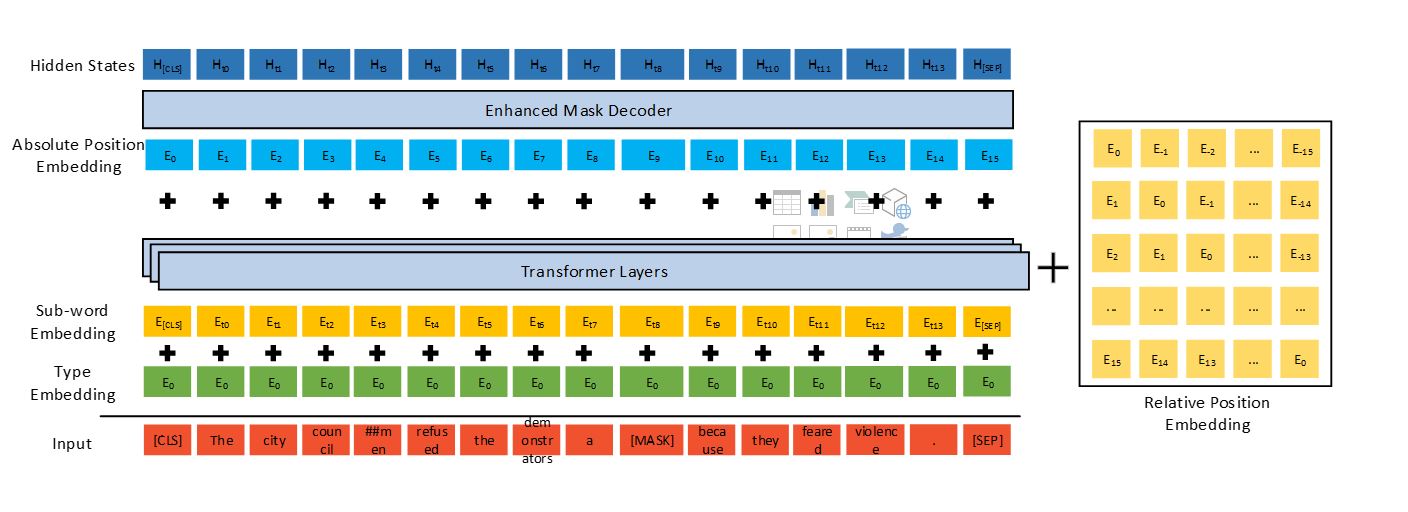
Jämfört med Googles T5-modell, som består av 11 miljarder parametrar, är 1.5 miljarder-parametern DeBERTa mycket mer energieffektiv att träna och underhålla, och den är lättare att komprimera och distribuera till appar med olika inställningar.
DeBERTa som överträffar mänskliga prestationer på SuperGLUE markerar en viktig milstolpe mot allmän AI. Trots dess lovande resultat på SuperGLUE når modellen inte på något sätt NLU:s intelligens på mänsklig nivå. Människor är extremt bra på att utnyttja kunskapen som lärts från olika uppgifter för att lösa en ny uppgift med ingen eller liten uppgiftsspecifik demonstration.
Microsoft kommer att integrera tekniken i nästa version av Microsoft Turing-modellen för naturlig språkrepresentation, som används på platser som Bing, Office, Dynamics och Azure Cognitive Services, som driver ett brett utbud av scenarier som involverar människa-maskin och människa-människa interaktioner via naturligt språk (som chatbot, rekommendation, frågesvar, sökning, personlig assistans, automatisering av kundsupport, innehållsgenerering och annat). Dessutom kommer Microsoft att släppa den 1.5 miljarder stora DeBERTa-modellen och källkoden till allmänheten.
Läs alla detaljer hos Microsoft här..