Googles text-till-bild-generator Imagen producerar bilder med "oöverträffad grad av fotorealism"
![]() 3 min. läsa
3 min. läsa
![]() Publicerad den
Publicerad den
Dela den här artikeln

Förbättra den här guiden
Läs vår informationssida för att ta reda på hur du kan hjälpa MSPoweruser upprätthålla redaktionen Läs mer
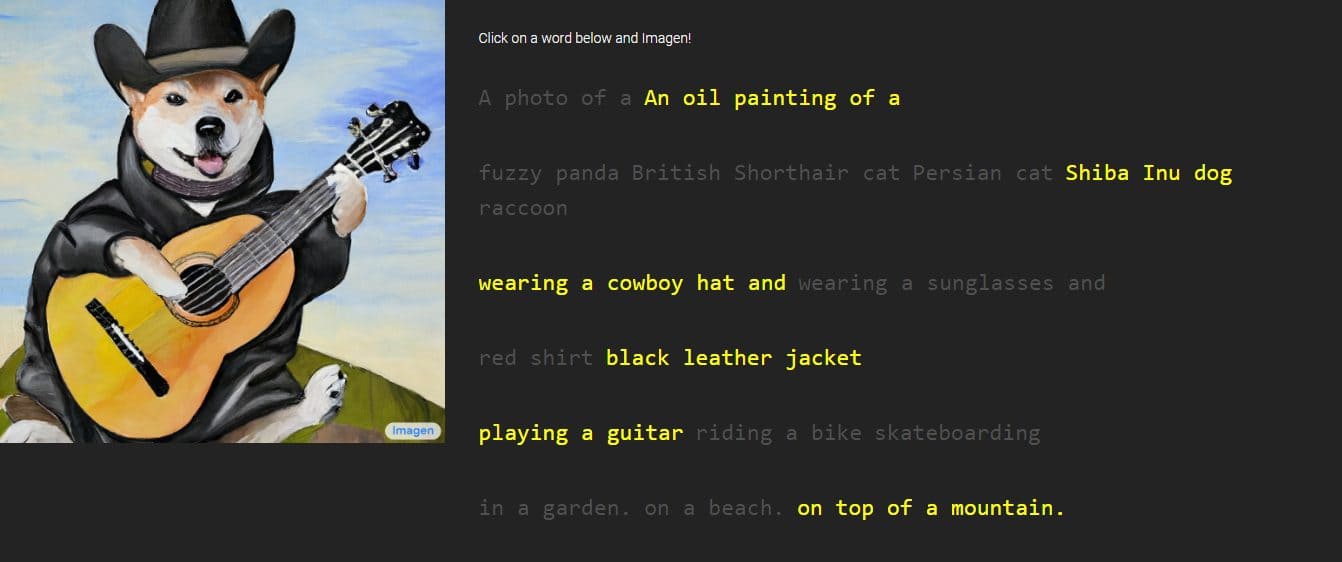
Google avtäckte en ny skapelse som heter "Bild,” en text-till-bild-generator genom beskrivningar som en person kommer att tillhandahålla. Företaget hävdar att det överträffar prestandan hos DALL-E 2, en annan AI-bildgenerator. Den presenterade några prover, som onekligen visar utsökta detaljer, men Imagen är för närvarande inte tillgänglig för allmänheten.
Den nya text-till-bild-diffusionsmodellen beskrivs ha "en oöverträffad grad av fotorealism och en djup nivå av språkförståelse." Den förstår text genom stora transformatorspråksmodeller och sägs förlita sig på diffusionsmodeller för att utföra högfientlig bildgenerering.

Google gav bilder och prover på Imagens arbete, med stilar som varierade från teckningar till oljemålningar och CGI:er. De åtföljs av de ord och fraser som används för att skapa dem. Till exempel läser det ena provet "en drakfrukt som bär karatebälte i snön", medan det andra har beskrivningen "en liten kaktus som bär en stråhatt och neonsolglasögon i Saharaöknen."
De genererade bilderna ser otroligt verkliga ut som om de skapades av en verklig person. Google säger dock att det görs genom diffusionsteknik genom att utnyttja en ren brusbild och förfina den på bästa möjliga sätt. Genom att förstå textbeskrivningen kommer Imagen att generera en bild på 64 x 64 pixlar, utföra två förbättringar och konvertera bilden till en större bit på 1024 x 1024 pixlar.
Google Research, Brain Team säger att Imagen utmärkte sig Kokos (en storskalig objektdetektering, segmentering och textningsdatauppsättning) trots att den inte är utbildad i det. Teamet rapporterade att det fick en ny toppmodern FID-poäng på 7.27.
Google jämförde också Imagens prestanda med andra text-till-bild-modeller genom att bedöma dem med "DrawBench". Den fungerar som ett riktmärke för text-till-bild-modeller där Google testade Imagen med andra metoder som VQ-GAN+CLIP, Latent Diffusion Models och DALL-E 2. Efter att ha testat för deras komposition, kardinalitet, rumsliga relationer, långform text, sällsynta ord och utmanande uppmaningar, sa teamet att "mänskliga bedömare starkt föredrar Imagen framför andra metoder, både när det gäller bild-textjustering och bildtrohet."
Trots dessa imponerande rapporter från forskargruppen kommer det inte att vara möjligt att testa Imagen själv eftersom det inte är tillgängligt för allmänheten. Google har skäl till det, såsom etiska utmaningar, potentiella risker för missbruk, sociala fördomar, begränsningar av stora språkmodeller och risk för kodade skadliga stereotyper och representationer. Teamet sammanfattar att med alla dessa utmaningar är Imagen fortfarande inte perfekt när det kommer till att generera bilder relaterade till människor.
"Imagen uppvisar allvarliga begränsningar när de genererar bilder som föreställer människor", förklarar teamet i ett blogginlägg. "Våra mänskliga utvärderingar fann att Imagen får betydligt högre preferensfrekvenser när den utvärderas på bilder som inte porträtterar människor, vilket tyder på en försämring av bildtrohet. Den preliminära bedömningen tyder också på att Imagen kodar för flera sociala fördomar och stereotyper, inklusive en övergripande partiskhet mot att generera bilder av människor med ljusare hudtoner och en tendens för bilder som porträtterar olika yrken att överensstämma med västerländska könsstereotyper. Slutligen, även när vi fokuserar generationer bort från människor, indikerar vår preliminära analys att Imagen kodar en rad sociala och kulturella fördomar när de genererar bilder av aktiviteter, händelser och föremål. Vi siktar på att göra framsteg på flera av dessa öppna utmaningar och begränsningar i framtida arbete.”