Googlov generator besedila v sliko Imagen ustvarja slike z "neprimerljivo stopnjo fotorealizma"
![]() 3 min. prebrati
3 min. prebrati
![]() Objavljeno dne
Objavljeno dne
Dajte v skupno rabo ta članek

Izboljšajte ta vodnik
Preberite našo stran za razkritje, če želite izvedeti, kako lahko pomagate MSPoweruser vzdrževati uredniško skupino Preberi več
google predstavil novo kreacijo z imenom »Slika,” generator besedila v sliko z opisi, ki jih bo oseba zagotovila. Podjetje trdi, da presega zmogljivost DALL-E 2, drugega generatorja slike AI. Predstavil je nekaj vzorcev, ki nedvomno kažejo izvrstne podrobnosti, a Imagen trenutno javnosti ni na voljo.
Novi model difuzije besedila v sliko je opisan, da ima "nevidljivo stopnjo fotorealizma in globoko raven razumevanja jezika." Besedilo razume prek velikih jezikovnih modelov transformatorjev in naj bi se zanašal na difuzijske modele za izvajanje generiranja slike visoke zvestobe.

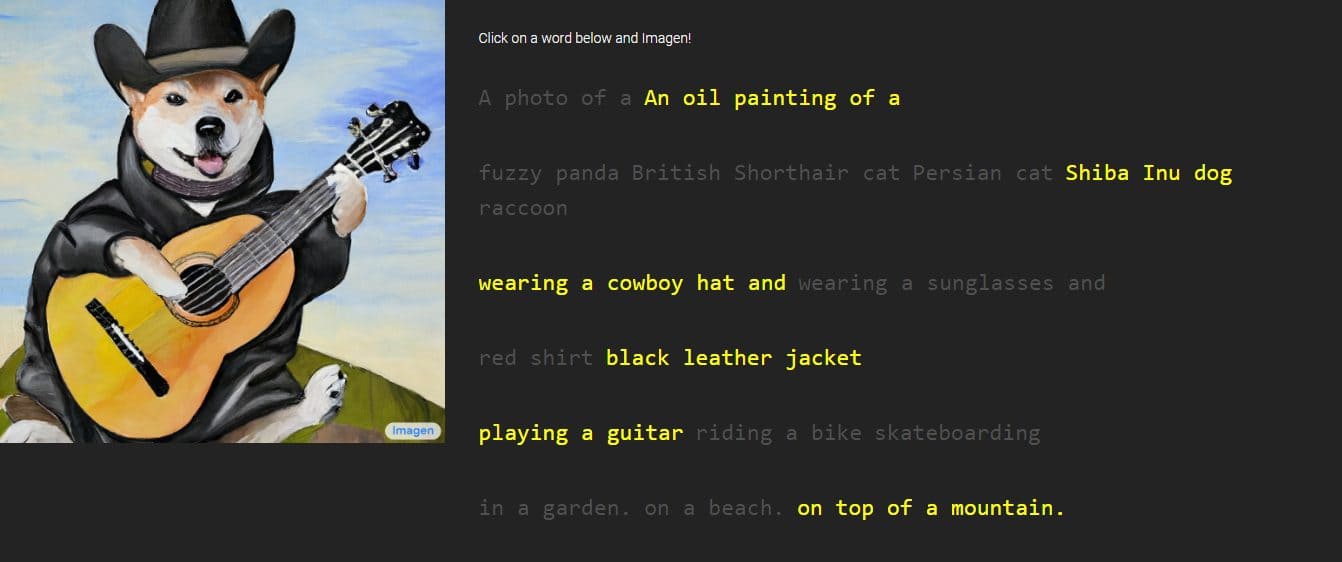
Google je zagotovil slike in vzorce Imagenovega dela, v slogih, ki se razlikujejo od risb do oljnih slik in CGI. Spremljajo jih besede in besedne zveze, ki se uporabljajo za njihovo ustvarjanje. Na primer, en vzorec se glasi »zmajev sadež, ki nosi karate pas na snegu«, drugi pa ima opis »majhen kaktus s slamnatim klobukom in neonskimi sončnimi očali v puščavi Sahara«.
Ustvarjene slike so videti neverjetno resnične, kot da bi jih ustvarila dejanska oseba. Vendar Google pravi, da se to izvaja s pomočjo difuzijskih tehnologij z uporabo čiste slike šuma in jo izboljša na najboljši možni način. Z razumevanjem predloženega besedilnega opisa bo Imagen ustvaril sliko velikosti 64 x 64 slikovnih pik, izvedel dve izboljšavi in sliko pretvoril v večji kos 1024 x 1024 slikovnih pik.
Google Research, Brain Team pravi, da se je Imagen odlično odrezal COCO (obsežen nabor podatkov za zaznavanje, segmentacijo in podnapise objektov), čeprav o tem niste usposobljeni. Ekipa je poročala, da je prejela novo najsodobnejšo oceno FID 7.27.
Google je tudi primerjal zmogljivost Imagena z drugimi modeli besedila v sliko, tako da jih je ocenil z uporabo »DrawBench«. Služi kot merilo za modele besedila v sliko, kjer je Google testiral Imagen z drugimi metodami, kot so VQ-GAN+CLIP, modeli latentne difuzije in DALL-E 2. Po testiranju njihove kompozicije, kardinalnosti, prostorskih odnosov, dolge oblike besedilo, redke besede in zahtevne pozive, je ekipa dejala, da »ljudski ocenjevalci močno dajejo prednost Imagenu pred drugimi metodami, tako pri poravnavi slike-besedila kot pri zvestobi sliki.«
Kljub tem impresivnim poročilom raziskovalne skupine, testiranje Imagen sami ne bo mogoče, saj ni dostopen javnosti. Google ima za to razloge, kot so etični izzivi, možna tveganja zlorabe, družbene pristranskosti, omejitve velikih jezikovnih modelov in tveganje kodiranih škodljivih stereotipov in predstavitev. Ekipa povzema, da ob vseh teh izzivih Imagen še vedno ni popoln, ko gre za ustvarjanje slik, povezanih z ljudmi.
"Imagen kaže resne omejitve pri ustvarjanju slik, ki prikazujejo ljudi," pojasnjuje ekipa v objavi na blogu. »Naše človeške ocene so pokazale, da ima Imagen bistveno višje stopnje preferenc, če ga ocenjujemo na slikah, ki ne prikazujejo ljudi, kar kaže na poslabšanje zvestobe slike. Preliminarna ocena tudi kaže, da Imagen kodira več družbenih pristranskosti in stereotipov, vključno s splošno pristranskostjo k ustvarjanju podob ljudi s svetlejšimi toni kože in težnjo, da se slike, ki prikazujejo različne poklice, uskladijo z zahodnimi stereotipi o spolu. Nazadnje, tudi ko se generacije osredotočamo stran od ljudi, naša predhodna analiza kaže, da Imagen kodira vrsto družbenih in kulturnih pristranskosti pri ustvarjanju podob dejavnosti, dogodkov in predmetov. Želimo napredovati pri več od teh odprtih izzivov in omejitev v prihodnjem delu."