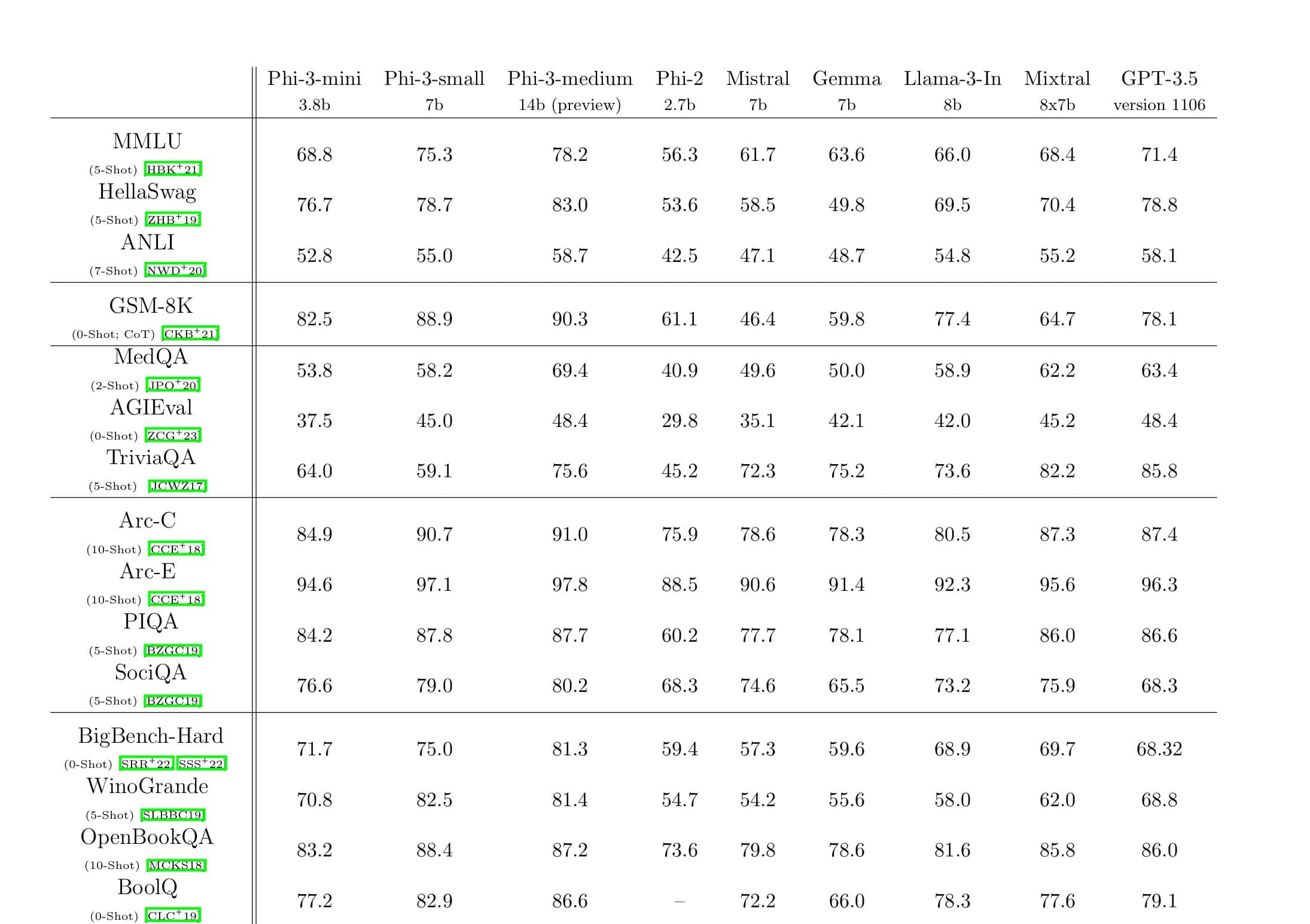
Zoznámte sa s Microsoft DeepSpeed, novou knižnicou pre hlboké vzdelávanie, ktorá dokáže trénovať obrovské modely so 100 miliardami parametrov
![]() 2 min. čítať
2 min. čítať
![]() Aktualizované na
Aktualizované na
Zdieľajte tento článok

Vylepšite túto príručku
Prečítajte si našu informačnú stránku a zistite, ako môžete pomôcť MSPoweruser udržať redakčný tím Čítaj viac
Microsoft Research dnes oznámil DeepSpeed, novú knižnicu na optimalizáciu hlbokého učenia, ktorá dokáže trénovať obrovské modely s 100 miliardami parametrov. V AI musíte mať väčšie modely prirodzeného jazyka pre lepšiu presnosť. Ale trénovanie väčších modelov prirodzeného jazyka je časovo náročné a náklady s tým spojené sú veľmi vysoké. Microsoft tvrdí, že nová knižnica hlbokého učenia DeepSpeed zlepšuje rýchlosť, náklady, rozsah a použiteľnosť.
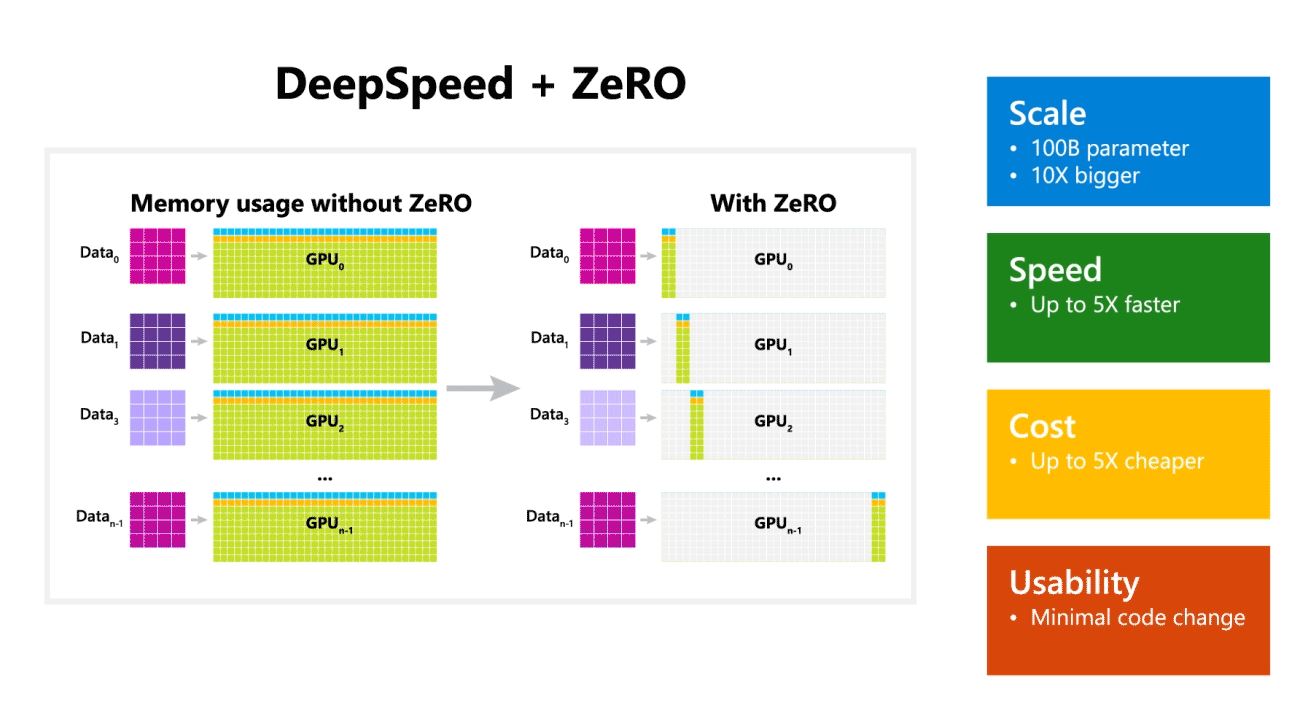
Microsoft tiež uviedol, že DeepSpeed umožňuje jazykové modely s modelmi až so 100 miliardami parametrov a zahŕňa ZeRO (Zero Redundancy Optimizer), paralelizovaný optimalizátor, ktorý znižuje zdroje potrebné na paralelizmus modelov a údajov a zároveň zvyšuje počet parametrov, ktoré je možné trénovať. . Pomocou DeepSpeed a ZeRO vyvinuli výskumníci Microsoftu novú Turingovu generáciu prirodzeného jazyka (Turing-NLG), najväčší jazykový model so 17 miliardami parametrov.
Hlavné prvky DeepSpeed:
- Mierka: Najmodernejšie veľké modely ako OpenAI GPT-2, NVIDIA Megatron-LM a Google T5 majú veľkosti 1.5 miliardy, 8.3 miliardy a 11 miliárd parametrov. Prvý stupeň ZeRO v DeepSpeed poskytuje systémovú podporu pre spustenie modelov až do 100 miliárd parametrov, 10-krát väčších.
- Rýchlosť: Pozorujeme až päťkrát vyššiu priepustnosť v porovnaní so stavom techniky na rôznych hardvéroch. Na klastroch GPU NVIDIA s prepojením s nízkou šírkou pásma (bez NVIDIA NVLink alebo Infiniband) dosahujeme 3.75-násobné zlepšenie priepustnosti oproti použitiu samotného Megatron-LM pre štandardný model GPT-2 s 1.5 miliardami parametrov. Na klastroch NVIDIA DGX-2 s vysokorýchlostným prepojením sme pri modeloch s 20 až 80 miliardami parametrov tri až päťkrát rýchlejší.
- Štát: Vylepšená priepustnosť sa môže premietnuť do výrazne znížených nákladov na školenie. Napríklad na trénovanie modelu s 20 miliardami parametrov vyžaduje DeepSpeed trikrát menej zdrojov.
- Použiteľnosť: Na to, aby model PyTorch mohol používať DeepSpeed a ZeRO, je potrebných len niekoľko zmien v kóde. V porovnaní so súčasnými knižnicami paralelizmu modelov DeepSpeed nevyžaduje prepracovanie kódu ani refaktorovanie modelu.
Microsoft má otvorené zdroje pre DeepSpeed aj ZeRO, môžete si to overiť tu na GitHub.
zdroj: Microsoft