Microsoft publica análise de causa raiz para os grandes problemas de login do Microsoft 365 desta semana
![]() 6 minutos. ler
6 minutos. ler
![]() Atualizado em
Atualizado em
Compartilhe este artigo

Melhore este guia
Leia nossa página de divulgação para descobrir como você pode ajudar o MSPoweruser a sustentar a equipe editorial Saiba mais
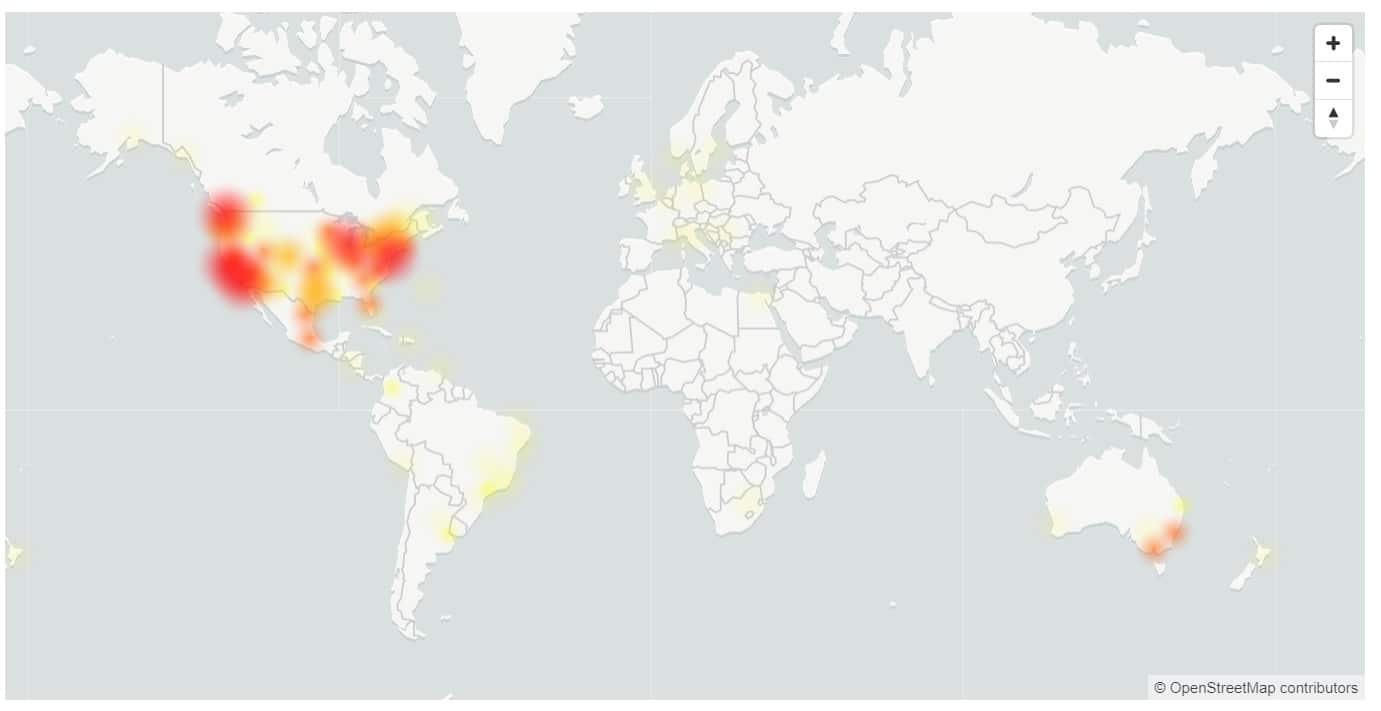
Esta semana tivemos um tempo de inatividade de quase 5 horas para o Microsoft 365, com usuários incapazes de fazer login em vários serviços, incluindo OneDrive e Microsoft Teams.
Agora A Microsoft publicou uma análise da causa raiz do problema, que a Microsoft diz que foi devido à atualização do serviço que deveria visar um anel de teste de validação interno, mas que foi implantado diretamente no ambiente de produção da Microsoft devido a um defeito de código latente no sistema de processo de implantação segura (SDP) do serviço de back-end do Azure AD.
A Microsoft diz que entre aproximadamente 21:25 UTC de 28 de setembro de 2020 e 00:23 UTC de 29 de setembro de 2020, os clientes encontraram erros ao realizar operações de autenticação para todos os aplicativos e serviços da Microsoft e de terceiros que dependem do Azure Active Directory (Azure AD ) para autenticação. O problema só foi completamente mitigado para todos às 2h25 do dia seguinte.
Os EUA e a Austrália foram os mais atingidos, com apenas 17% dos usuários nos EUA conseguindo fazer login com sucesso.
O problema foi agravado porque a Microsoft não conseguiu reverter a atualização devido ao defeito latente em seu sistema SDP corromper os metadados de implantação, o que significa que a atualização teve que ser revertida manualmente.
A Microsoft pediu desculpas aos clientes afetados e diz que continua tomando medidas para melhorar a plataforma Microsoft Azure e seus processos para ajudar a garantir que tais incidentes não ocorram no futuro. Uma das etapas planejadas inclui a aplicação de proteções adicionais ao sistema SDP de back-end de serviço do Azure AD para evitar a classe de problemas identificados.
Leia a análise completa abaixo:
RCA – Erros de autenticação em vários serviços da Microsoft e aplicativos integrados do Azure Active Directory (ID de rastreamento SM79-F88)
Resumo do Impacto: Entre aproximadamente 21:25 UTC de 28 de setembro de 2020 e 00:23 UTC de 29 de setembro de 2020, os clientes podem ter encontrado erros ao realizar operações de autenticação para todos os aplicativos e serviços da Microsoft e de terceiros que dependem do Azure Active Directory (Azure AD) para autenticação. Os aplicativos que usam o Azure AD B2C para autenticação também foram afetados.
Os usuários que ainda não foram autenticados nos serviços de nuvem usando o Azure AD tiveram maior probabilidade de enfrentar problemas e podem ter visto várias falhas de solicitação de autenticação correspondentes aos números médios de disponibilidade mostrados abaixo. Eles foram agregados em diferentes clientes e cargas de trabalho.
- Europa: 81% de taxa de sucesso durante o incidente.
- Américas: taxa de sucesso de 17% durante a duração do incidente, melhorando para 37% pouco antes da mitigação.
- Ásia: taxa de sucesso de 72% nos primeiros 120 minutos do incidente. À medida que o tráfego de pico no horário comercial começou, a disponibilidade caiu para 32% em seu nível mais baixo.
- Austrália: 37% de taxa de sucesso durante o incidente.
O serviço foi restaurado para a disponibilidade operacional normal para a maioria dos clientes às 00:23 UTC de 29 de setembro de 2020, no entanto, observamos falhas de solicitação de autenticação pouco frequentes que podem ter afetado os clientes até as 02:25 UTC.
Os usuários que se autenticaram antes do horário de início do impacto tinham menos probabilidade de enfrentar problemas, dependendo dos aplicativos ou serviços que estavam acessando.
As medidas de resiliência em vigor protegeram os serviços de Identidades Gerenciadas para Máquinas Virtuais, Conjuntos de Dimensionamento de Máquinas Virtuais e Serviços de Kubernetes do Azure com uma disponibilidade média de 99.8% durante a duração do incidente.
Causa raiz: Em 28 de setembro às 21:25 UTC, uma atualização de serviço visando um anel de teste de validação interno foi implantada, causando uma falha na inicialização nos serviços de back-end do Azure AD. Um defeito de código latente no sistema de processo de implantação segura (SDP) do serviço de back-end do Azure AD fez com que isso fosse implantado diretamente em nosso ambiente de produção, ignorando nosso processo de validação normal.
O Azure AD foi projetado para ser um serviço distribuído geograficamente implantado em uma configuração ativa-ativa com várias partições em vários data centers em todo o mundo, criados com limites de isolamento. Normalmente, as alterações visam inicialmente um anel de validação que não contém dados do cliente, seguido por um anel interno que contém apenas usuários da Microsoft e, por último, nosso ambiente de produção. Essas mudanças são implantadas em fases em cinco anéis ao longo de vários dias.
Nesse caso, o sistema SDP falhou ao direcionar corretamente o anel de teste de validação devido a um defeito latente que afetou a capacidade do sistema de interpretar metadados de implantação. Consequentemente, todos os anéis foram direcionados simultaneamente. A implantação incorreta causou a degradação da disponibilidade do serviço.
Poucos minutos após o impacto, tomamos medidas para reverter a alteração usando sistemas de reversão automatizados que normalmente limitariam a duração e a gravidade do impacto. No entanto, o defeito latente em nosso sistema SDP corrompeu os metadados de implantação e tivemos que recorrer a processos de reversão manual. Isso ampliou significativamente o tempo para mitigar o problema.
Mitigação: Nosso monitoramento detectou a degradação do serviço minutos após o impacto inicial e nos envolvemos imediatamente para iniciar a solução de problemas. As seguintes atividades de mitigação foram realizadas:
- O impacto começou às 21:25 UTC e, em 5 minutos, nosso monitoramento detectou uma condição insalubre e a engenharia foi imediatamente acionada.
- Nos próximos 30 minutos, em simultâneo com a resolução do problema, uma série de etapas foram realizadas para tentar minimizar o impacto no cliente e agilizar a mitigação. Isso incluiu o dimensionamento proativo de alguns dos serviços do Azure AD para lidar com a carga antecipada assim que uma mitigação fosse aplicada e o failover de determinadas cargas de trabalho para um sistema de autenticação do Azure AD de backup.
- Às 22:02 UTC, estabelecemos a causa raiz, iniciamos a correção e iniciamos nossos mecanismos de reversão automatizados.
- A reversão automatizada falhou devido à corrupção dos metadados do SDP. Às 22:47 UTC, iniciamos o processo de atualização manual da configuração do serviço que ignora o sistema SDP, e toda a operação foi concluída às 23:59 UTC.
- Às 00:23 UTC, instâncias de serviço de back-end suficientes retornaram a um estado íntegro para alcançar os parâmetros operacionais de serviço normais.
- Todas as instâncias de serviço com impacto residual foram recuperadas às 02:25 UTC.
Próximas etapas: Pedimos sinceras desculpas pelo impacto aos clientes afetados. Estamos continuamente tomando medidas para melhorar a Plataforma Microsoft Azure e nossos processos para ajudar a garantir que tais incidentes não ocorram no futuro. Nesse caso, isso inclui (mas não se limita a) o seguinte:
Nós já completamos
- Corrigido o defeito de código latente no sistema SDP de back-end do Azure AD.
- Corrigido o sistema de reversão existente para permitir a restauração dos últimos metadados válidos para proteção contra corrupção.
- Expanda o escopo e a frequência dos exercícios de operação de reversão.
As etapas restantes incluem
- Aplique proteções adicionais ao sistema SDP de back-end do serviço Azure AD para evitar a classe de problemas identificados aqui.
- Acelere a implantação do sistema de autenticação de backup do Azure AD para todos os principais serviços como prioridade máxima para reduzir significativamente o impacto de um tipo semelhante de problema no futuro.
- Cenários do Azure AD integrados ao pipeline de comunicações automatizadas que publicam a comunicação inicial para os clientes afetados em até 15 minutos após o impacto.
Dar uma resposta: Ajude-nos a melhorar a experiência de comunicação com o cliente do Azure respondendo à nossa pesquisa: https://aka.ms/AzurePIRSurvey
via ZDNet