Microsoft introduserer Phi-3-familien av modeller som overgår andre modeller i sin klasse
![]() 2 min. lese
2 min. lese
![]() Publisert på
Publisert på
Del denne artikkelen

Forbedre denne veiledningen
Les vår avsløringsside for å finne ut hvordan du kan hjelpe MSPoweruser opprettholde redaksjonen Les mer
Tilbake i desember 2023 ga Microsoft ut Phi-2 modell med 2.7 milliarder parametere som leverte toppmoderne ytelse blant basisspråkmodeller med mindre enn 13 milliarder parametere. I løpet av de siste fire månedene har flere andre modeller som ble sluppet klart bedre enn Phi-2. Nylig ga Meta ut Llama-3-familien av modeller som overgikk alle de tidligere utgitte modellene med åpen kildekode.
I går kveld kunngjorde Microsoft Research Phi-3-familien av modeller via en teknisk rapport. Det er tre modeller i Phi-3-familien:
- phi-3-mini (3.8B)
- phi-3-small (7B)
- phi-3-medium (14B)
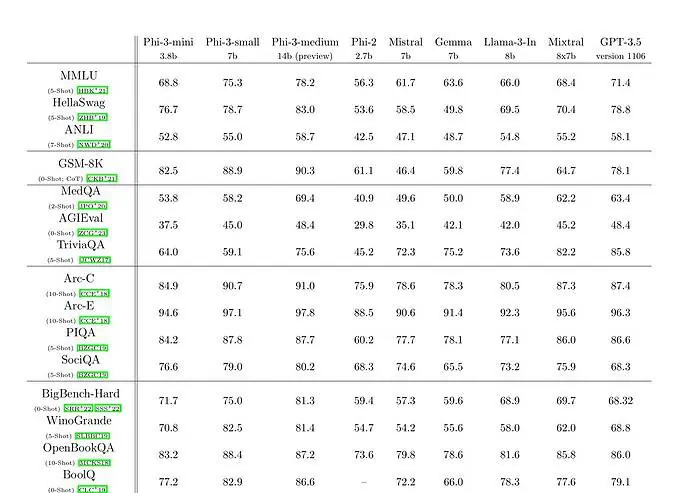
phi-3-mini med en språkmodell på 3.8 milliarder parametere er trent på 3.3 billioner tokens. I følge benchmarks slår phi-3-mini Mixtral 8x7B og GPT-3.5. Microsoft hevder at denne modellen er liten nok til å kunne distribueres på en telefon. Microsoft brukte en oppskalert versjon av datasettet som ble brukt for phi-2, sammensatt av sterkt filtrerte nettdata og syntetiske data. I følge Microsofts benchmark-resultater på Technical Paper oppnår phi-3-small og phi-3-medium en imponerende MMLU-score på henholdsvis 75.3 og 78.2.
Når det gjelder LLM-evner, mens Phi-3-mini-modellen oppnår et lignende nivå av språkforståelse og resonneringsevne som for mye større modeller, er den fortsatt fundamentalt begrenset av størrelsen for visse oppgaver. Modellen har rett og slett ikke kapasitet til å lagre omfattende faktakunnskap, noe man for eksempel kan se med lav ytelse på TriviaQA. Vi tror imidlertid at denne svakheten kan løses ved å utvide med en søkemotor.