Microsoft DeBERTa overgår ynkelige mennesker i SuperGlue leseforståelsestest
![]() 2 min. lese
2 min. lese
![]() Publisert på
Publisert på
Del denne artikkelen

Forbedre denne veiledningen
Les vår avsløringsside for å finne ut hvordan du kan hjelpe MSPoweruser opprettholde redaksjonen Les mer
Det har vært massiv fremgang nylig i treningsnettverk med millioner av parametere. Microsoft oppdaterte nylig DeBERTa (Decoding-enhanced BERT with disentangled attention)-modellen ved å trene opp en større versjon som består av 48 transformatorlag med 1.5 milliarder parametere. Den betydelige ytelsesøkningen gjør at enkelt DeBERTa-modellen overgår den menneskelige ytelsen på SuperGLUE-språkbehandlingen og -forståelsen for første gang når det gjelder makro-gjennomsnittlig poengsum (89.9 mot 89.8), og overgår den menneskelige grunnlinjen med en anstendig margin (90.3 mot 89.8) . SuperGLUE-referansen består av et bredt spekter av Natural Language Understanding-oppgaver, inkludert svar på spørsmål, naturlig språkslutning. Modellen ligger også på toppen av GLUE-benchmark-rangeringen med en makro-gjennomsnittlig poengsum på 90.8.
DeBERTa forbedrer tidligere toppmoderne PLM-er (for eksempel BERT, RoBERTa, UniLM) ved å bruke tre nye teknikker: en løst oppmerksomhetsmekanisme, en forbedret maskedekoder og en virtuell motstridende treningsmetode for finjustering.
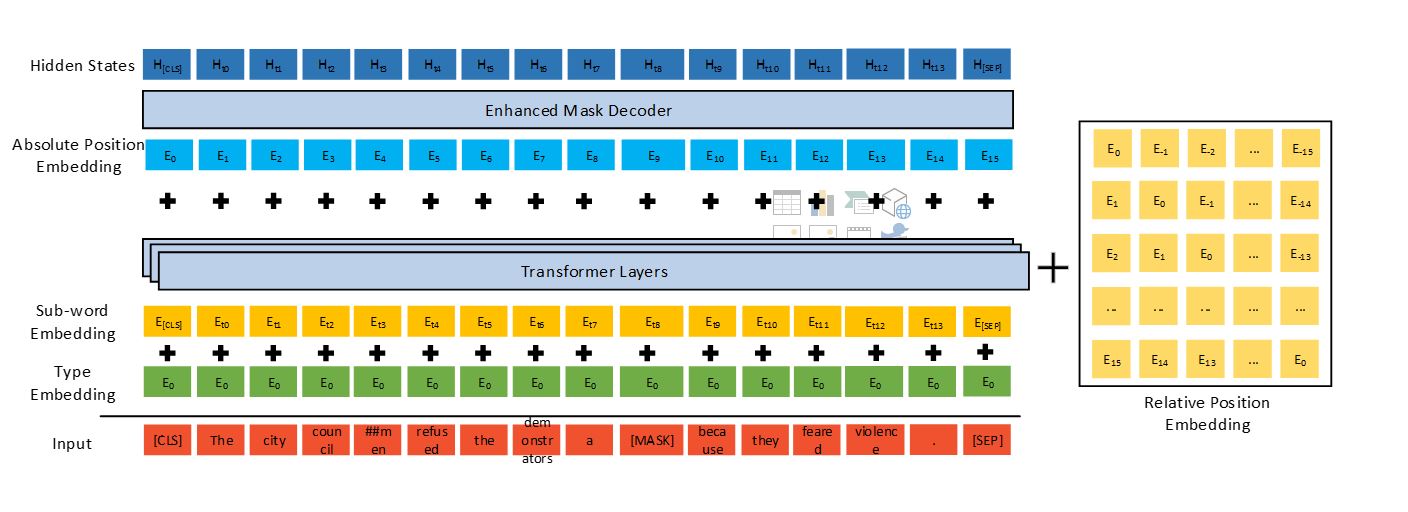
Sammenlignet med Googles T5-modell, som består av 11 milliarder parametere, er DeBERTa med 1.5 milliarder parametere mye mer energieffektiv å trene og vedlikeholde, og den er lettere å komprimere og distribuere til apper med ulike innstillinger.
DeBERTa som overgår menneskelig ytelse på SuperGLUE markerer en viktig milepæl mot generell AI. Til tross for sine lovende resultater på SuperGLUE, når modellen på ingen måte NLUs intelligens på menneskelig nivå. Mennesker er ekstremt flinke til å utnytte kunnskapen som er lært fra ulike oppgaver til å løse en ny oppgave med ingen eller liten oppgavespesifikk demonstrasjon.
Microsoft vil integrere teknologien i den neste versjonen av Microsoft Turing-modellen for naturlig språkrepresentasjon, brukt på steder som Bing, Office, Dynamics og Azure Cognitive Services, og drive en lang rekke scenarier som involverer menneske-maskin og menneske-menneske interaksjoner via naturlig språk (som chatbot, anbefaling, svar på spørsmål, søk, personlig assistanse, kundestøtteautomatisering, innholdsgenerering og andre). I tillegg vil Microsoft gi ut DeBERTa-modellen med 1.5 milliarder parametere og kildekoden til offentligheten.
Les alle detaljene hos Microsoft her..