Maak kennis met Microsoft DeepSpeed, een nieuwe deep learning-bibliotheek die enorme modellen van 100 miljard parameters kan trainen
![]() 2 minuut. lezen
2 minuut. lezen
![]() Bijgewerkt op
Bijgewerkt op
deel dit artikel

Verbeter deze handleiding
Lees onze openbaarmakingspagina om erachter te komen hoe u MSPoweruser kunt helpen het redactieteam te ondersteunen Lees meer
Microsoft Research heeft vandaag DeepSpeed aangekondigd, een nieuwe bibliotheek voor deep learning-optimalisatie die enorme modellen van 100 miljard parameters kan trainen. In AI heb je grotere natuurlijke taalmodellen nodig voor een betere nauwkeurigheid. Maar het trainen van grotere natuurlijke taalmodellen is tijdrovend en de kosten die ermee gepaard gaan zijn erg hoog. Microsoft beweert dat de nieuwe DeepSpeed deep learning-bibliotheek snelheid, kosten, schaal en bruikbaarheid verbetert.
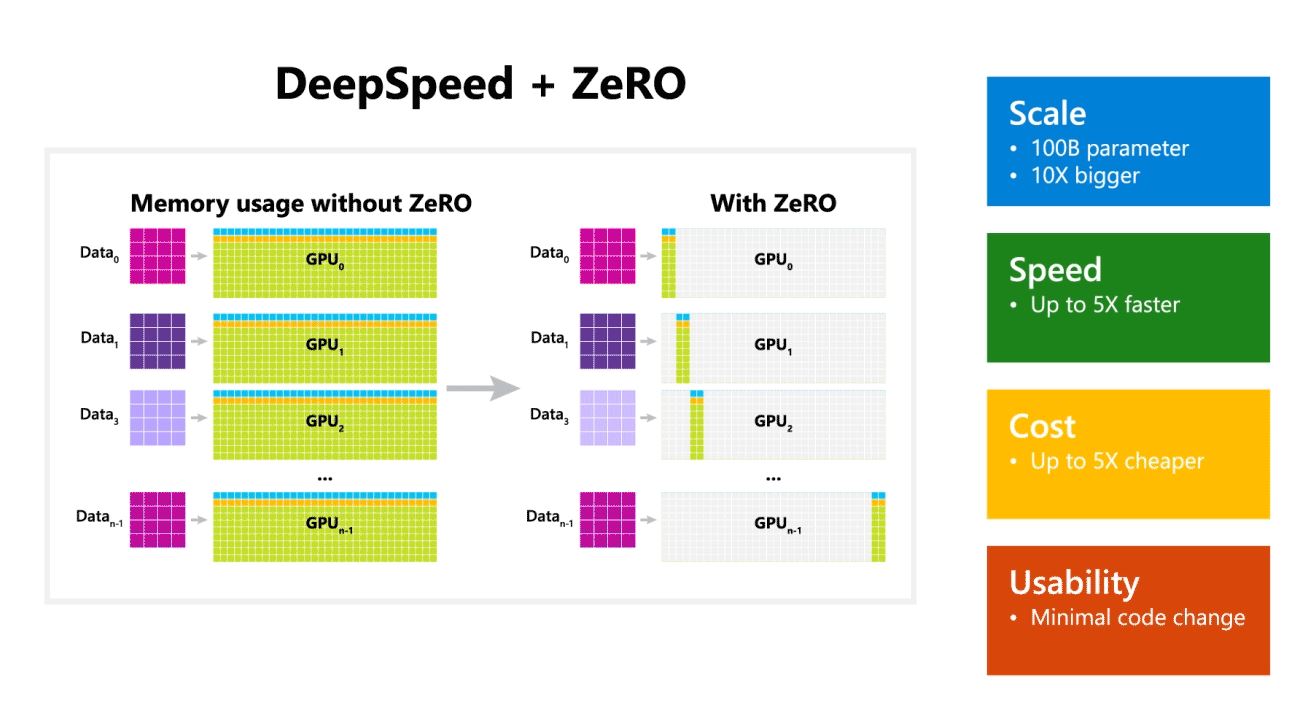
Microsoft vermeldde ook dat DeepSpeed taalmodellen mogelijk maakt met modellen tot 100 miljard parameters en dat het ZeRO (Zero Redundancy Optimizer) bevat, een geparallelliseerde optimizer die de middelen vermindert die nodig zijn voor model- en gegevensparallellisme, terwijl het aantal parameters dat kan worden getraind toeneemt. . Met behulp van DeepSpeed en ZeRO hebben Microsoft-onderzoekers de nieuwe Turing Natural Language Generation (Turing-NLG) ontwikkeld, het grootste taalmodel met 17 miljard parameters.
Hoogtepunten van DeepSpeed:
- Scale: State-of-the-art grote modellen zoals OpenAI GPT-2, NVIDIA Megatron-LM en Google T5 hebben een grootte van respectievelijk 1.5 miljard, 8.3 miljard en 11 miljard parameters. ZeRO stage één in DeepSpeed biedt systeemondersteuning om modellen tot 100 miljard parameters uit te voeren, 10 keer groter.
- Speed: We nemen een tot vijf keer hogere doorvoer waar dan state-of-the-art voor verschillende hardware. Op NVIDIA GPU-clusters met een lage bandbreedte-interconnect (zonder NVIDIA NVLink of Infiniband), bereiken we een doorvoerverbetering van 3.75x ten opzichte van het gebruik van alleen Megatron-LM voor een standaard GPT-2-model met 1.5 miljard parameters. Op NVIDIA DGX-2-clusters met interconnect met hoge bandbreedte zijn we voor modellen met 20 tot 80 miljard parameters drie tot vijf keer sneller.
- Kosten: Verbeterde doorvoer kan worden vertaald in aanzienlijk lagere opleidingskosten. Om bijvoorbeeld een model met 20 miljard parameters te trainen, heeft DeepSpeed drie keer minder middelen nodig.
- Usability: Er zijn slechts een paar regels codewijzigingen nodig om een PyTorch-model DeepSpeed en ZeRO te laten gebruiken. Vergeleken met de huidige parallellisme-bibliotheken van modellen, vereist DeepSpeed geen herontwerp van code of modelrefactoring.
Microsoft is zowel DeepSpeed als ZeRO open source, u kunt het bekijken hier op GitHub.
Bron: Microsoft