Google's tekst-naar-afbeelding generator Imagen produceert afbeeldingen met 'ongekende mate van fotorealisme'
![]() 3 minuut. lezen
3 minuut. lezen
![]() Uitgegeven op
Uitgegeven op
deel dit artikel

Verbeter deze handleiding
Lees onze openbaarmakingspagina om erachter te komen hoe u MSPoweruser kunt helpen het redactieteam te ondersteunen Lees meer
Kopen Google Reviews onthulde een nieuwe creatie genaamd “Beeld', een tekst-naar-beeldgenerator door middel van beschrijvingen die een persoon zal geven. Het bedrijf beweert dat het de prestaties van DALL-E 2, een andere AI-beeldgenerator, overtreft. Het presenteerde enkele voorbeelden, die onmiskenbaar prachtige details laten zien, maar Imagen is momenteel niet beschikbaar voor het publiek.
Van het nieuwe tekst-naar-beeld diffusiemodel wordt beschreven dat het "een ongekende mate van fotorealisme en een diep niveau van taalbegrip" heeft. Het begrijpt tekst via grote transformatortaalmodellen en er wordt gezegd dat het vertrouwt op diffusiemodellen om high-fidelity beeldgeneratie uit te voeren.

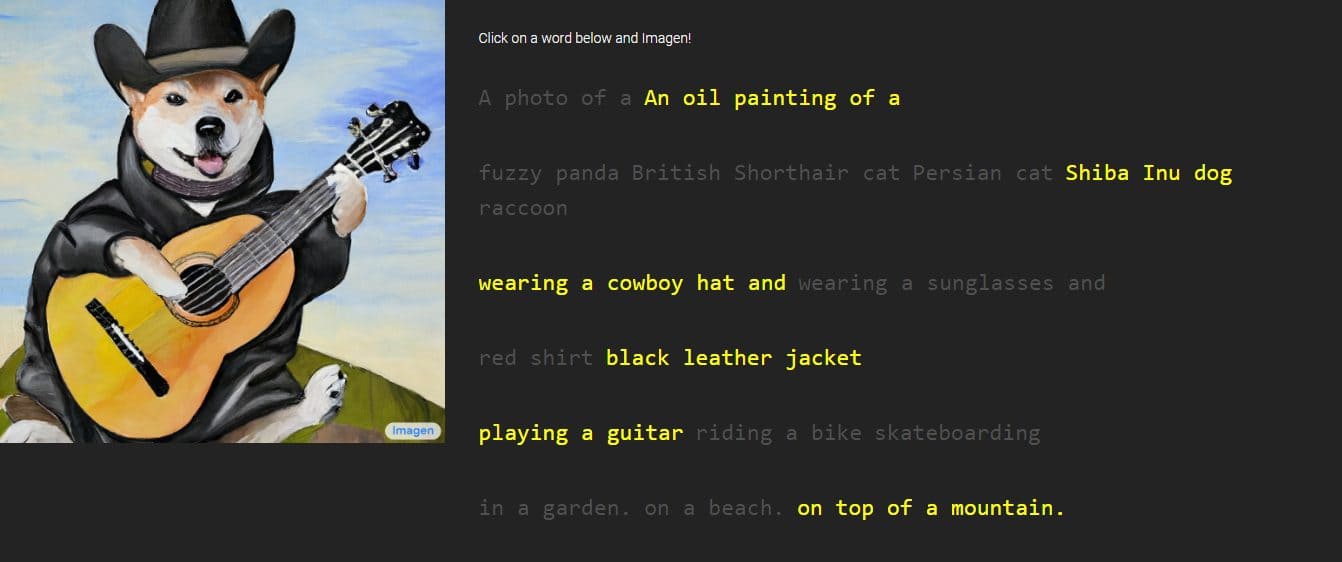
Google leverde afbeeldingen en voorbeelden van het werk van Imagen, met stijlen variërend van tekeningen tot olieverfschilderijen en CGI's. Ze gaan vergezeld van de woorden en zinnen die zijn gebruikt om ze te genereren. Een voorbeeld luidt bijvoorbeeld: "een drakenvrucht met een karateriem in de sneeuw", terwijl het andere de beschrijving heeft "een kleine cactus met een strohoed en een neonzonnebril in de Sahara-woestijn."
De gegenereerde afbeeldingen zien er ongelooflijk echt uit alsof ze door een echt persoon zijn gemaakt. Google zegt echter dat dit wordt gedaan door middel van diffusietechnologieën door een puur ruisbeeld te gebruiken en dit op de best mogelijke manier te verfijnen. Door de verstrekte tekstbeschrijving te begrijpen, genereert Imagen een afbeelding van 64 x 64 pixels, voert twee verbeteringen uit en converteert de afbeelding naar een groter stuk van 1024 x 1024 pixels.
Google Research, Brain Team zegt dat Imagen uitblonk op COCO (een grootschalige dataset voor objectdetectie, segmentatie en ondertiteling) ondanks dat u er niet op getraind bent. Het team meldde dat het een nieuwe state-of-the-art FID-score van 7.27 ontving.
Google vergeleek ook de prestaties van Imagen met andere tekst-naar-afbeelding-modellen door ze te beoordelen met "DrawBench". Het dient als een benchmark voor tekst-naar-afbeelding-modellen waarbij Google Imagen heeft getest met andere methoden zoals VQ-GAN+CLIP, Latent Diffusion Models en DALL-E 2. Na het testen op hun compositie, kardinaliteit, ruimtelijke relaties, lange vorm tekst, zeldzame woorden en uitdagende prompts, zei het team dat "menselijke beoordelaars Imagen sterk verkiezen boven andere methoden, zowel wat betreft beeld-tekstuitlijning als beeldgetrouwheid."
Ondanks deze indrukwekkende rapporten van het onderzoeksteam, is het niet mogelijk om Imagen zelf te testen omdat het niet toegankelijk is voor het publiek. Google heeft daar redenen voor, zoals ethische uitdagingen, potentiële risico's van misbruik, sociale vooroordelen, beperkingen van grote taalmodellen en het risico van gecodeerde schadelijke stereotypen en representaties. Het team vat samen dat met al deze uitdagingen Imagen nog steeds niet perfect is als het gaat om het genereren van afbeeldingen met betrekking tot mensen.
"Imagen vertoont ernstige beperkingen bij het genereren van afbeeldingen van mensen", legt het team uit in een blogpost. "Uit onze menselijke evaluaties bleek dat Imagen aanzienlijk hogere voorkeurspercentages behaalt wanneer het wordt beoordeeld op afbeeldingen die geen mensen afbeelden, wat wijst op een verslechtering van de beeldgetrouwheid. Voorlopige beoordeling suggereert ook dat Imagen codeert voor verschillende sociale vooroordelen en stereotypen, waaronder een algemene voorkeur voor het genereren van afbeeldingen van mensen met lichtere huidtinten en de neiging dat afbeeldingen die verschillende beroepen uitbeelden, aansluiten bij westerse genderstereotypen. Ten slotte, zelfs wanneer we generaties buiten de mensen focussen, geeft onze voorlopige analyse aan dat Imagen een reeks sociale en culturele vooroordelen codeert bij het genereren van afbeeldingen van activiteiten, evenementen en objecten. We streven ernaar om in toekomstig werk vooruitgang te boeken met een aantal van deze openstaande uitdagingen en beperkingen.”