ChatGPT Plus サブスクライバーが GPT-4 を利用できるようになりました
![]() 3分。 読んだ
3分。 読んだ
![]() 上で公開
上で公開
この記事を共有する

このガイドを改善する
MSPoweruser の編集チームの維持にどのように貢献できるかについては、開示ページをお読みください。 続きを読む

OpenAIがついに発表 GPT-4. 同社によると、同社の最新の AI モデルは、より多くの入力を混乱なく処理できるため、より正確で効率的です。 それに加えて、GPT-4には確かに マルチモーダル 画像を処理できるようにする機能。 ChatGPT Plus サブスクライバーは GPT-4 を利用できるようになり、開発者は API としてアクセスできるようになりました。
後 レポート 先週の到着について、GPT-4 がついに登場し、Azure の AI に最適化されたインフラストラクチャを介して配信されます。 これは Microsoft Azure AI スーパーコンピューターでトレーニングされており、GPT-3.5 とは顕著な違いがいくつかあります。 特に、GPT-4 ゴール さまざまなテストとベンチマークで 88 パーセンタイル以上。
「カジュアルな会話では、GPT-3.5 と GPT-4 の違いは微妙な場合があります」と OpenAI はブログ投稿で述べています。 「タスクの複雑さが十分なしきい値に達すると、違いが現れます。GPT-4 は、GPT-3.5 よりも信頼性が高く、創造的であり、はるかに微妙な指示を処理できます。」
一般に、OpenAI は、新しいモデルが制限されたトピックや要求に応答する可能性が 82% 低く、ユーザーにとって安全であると述べています。 回答の質も向上し、事実に基づいた回答が得られる可能性が最大 40% になりました。
GPT-4 の大部分は、クエリをより効果的に処理する能力に重点を置いています。 OpenAI が指摘したように、今では 25,000 語のテキストを混乱なく受け入れることができます。 これは、モデルの可能性を最大限に活用したいユーザーにとって朗報です。質問やリクエストで詳細や指示を提供できるようになるからです。 ただし、GPT-4 の最大のハイライトは、マルチモーダル機能の追加です。これは、先週報告されて以来、モデルからの最大の期待の 4 つでした。 この新しい機能を使用して、GPT-XNUMX は画像入力を処理し、テキストで説明できるようになりましたが、Be My Eyes とその仮想ボランティア機能の助けを借りてまだ技術的にテスト中であるため、OpenAI のすべてのお客様が利用できるわけではありません。 .
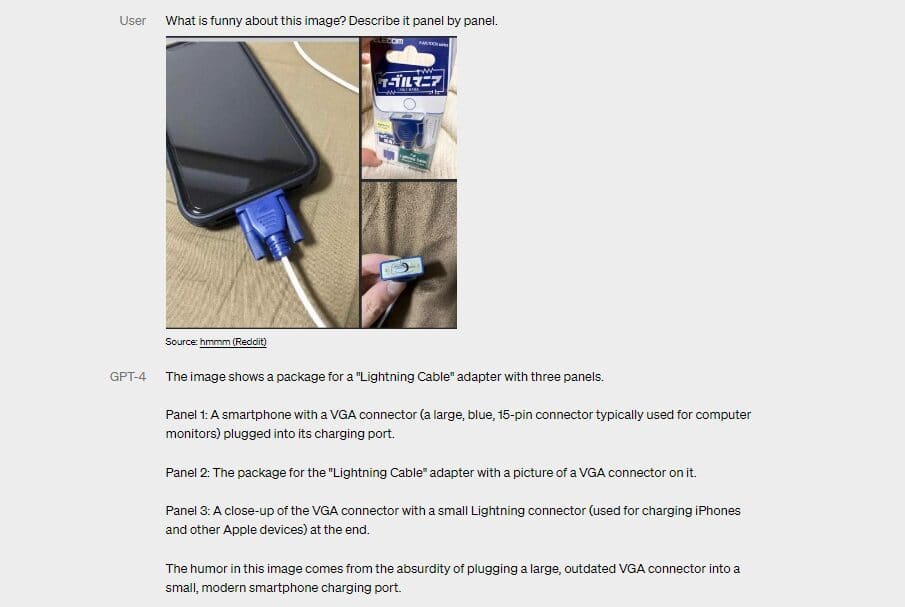

「たとえば、ユーザーが冷蔵庫の内部の写真を送信すると、仮想ボランティアはその中に何が入っているかを正しく識別するだけでなく、それらの材料で何が準備できるかを推測して分析することもできます」と OpenAi は機能について説明しました。 . 「このツールはまた、それらの材料のレシピを多数提供し、それらの作り方に関する段階的なガイドを送信することもできます。」
Wow Bing は、GPT-4 を使用していることを認識したので、実際に画像を記述できるようになりました!
byu/BroskiPlaysYT inチーン
それにもかかわらず、このマルチモダリティ機能は部分的に 新しいビング. マイクロソフトによると、同社の検索エンジンのチャットボットは先週からこのモデルを実行しているという。 ただし、Bing のマルチモーダル機能はまだ制限されていることに注意することが重要です。 まず、Web 上で提供されるリンクを介してのみ画像を受け入れることができます。これは応答として記述されます。 一方、説明を使用して画像を要求すると、チャットボットは画像の結果など、最も関連性の高いコンテンツを提供します。
余談ですが、GPT-4 でのこれらの改善は、すべてのジェネレーティブ AI 製品に共通して存在する既存の問題の終わりを意味するものではありません。 OpenAI は、このモデルが有害な指示への応答を拒否するという点で GPT-3.5 よりも安全であると約束しましたが、それでも幻覚や社会的偏見を生み出す可能性があります。 OpenAI の CEO である Sam Altman でさえ 記載された GPT-4は「まだ欠陥があり、まだ制限されている」ものとして。 それにもかかわらず、チームはモデルの継続的な改善に専念しています.これは、一般の人々からより多くの注目を集め続け、Microsoftがより多くの製品にモデルを注入するためです.







ユーザーフォーラム
0メッセージ