Microsoft annuncia la disponibilità pubblica di due utilità di data science
![]() 1 minuto. leggere
1 minuto. leggere
![]() Edizione del
Edizione del
Condividi questo articolo

Migliora questa guida
Leggi la nostra pagina informativa per scoprire come puoi aiutare MSPoweruser a sostenere il team editoriale Per saperne di più
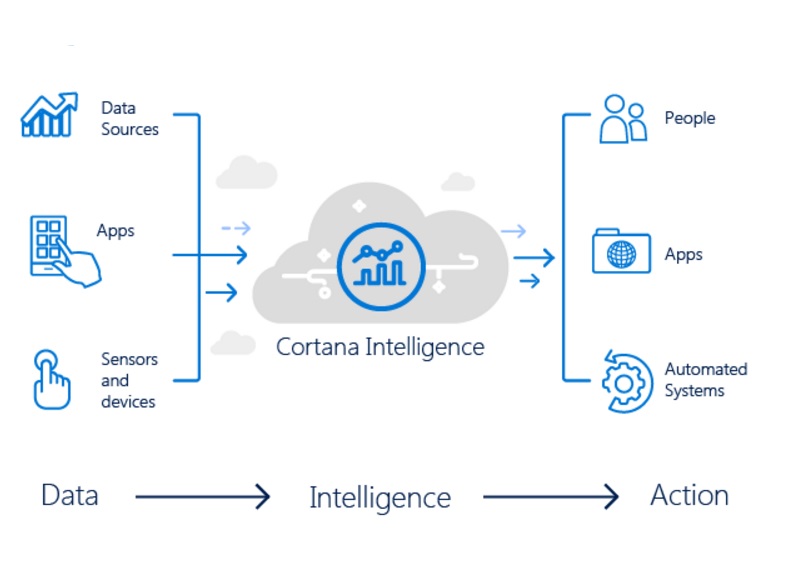
I data scientist trascorrono una notevole quantità di tempo a scrivere codice alla ricerca di risposte alle domande seguenti per la maggior parte del tempo.
- Che aspetto hanno i dati? Qual è lo schema?
- Qual è la qualità dei dati? Qual è la gravità dei dati mancanti?
- Come sono distribuite le singole variabili? Devo fare la trasformazione delle variabili?
- Quanto sono rilevanti i dati per l'attività di apprendimento automatico? Quanto è difficile l'attività di apprendimento automatico in sé?
- Quali variabili sono più rilevanti per l'obiettivo del machine learning?
- Esiste un modello di clustering specifico nei dati?
- Come funzioneranno i modelli ML sui dati? Quali variabili sono significative nei modelli?
Gran parte del codice può essere generalizzato in utilità di data science che possono essere riutilizzate nei progetti aiutando i data scientist a lavorare su attività specifiche in un progetto in modalità guidata, garantendo coerenza e completezza delle attività sottostanti. Per aiutare i data scientist, Microsoft sta rilasciando due utilità di data science,
- Esplorazione interattiva dei dati, analisi e reporting (IDEAR) e
- Modellazione e reporting automatizzati (AMAR).
È possibile accedere a queste due utilità, eseguite in CRAN-R questo sito GitHub.
Ulteriori informazioni su queste utilità qui.







