Scopri Microsoft DeepSpeed, una nuova libreria di deep learning in grado di addestrare enormi modelli da 100 miliardi di parametri
![]() 2 minuto. leggere
2 minuto. leggere
![]() Aggiornato su
Aggiornato su
Condividi questo articolo

Migliora questa guida
Leggi la nostra pagina informativa per scoprire come puoi aiutare MSPoweruser a sostenere il team editoriale Per saperne di più
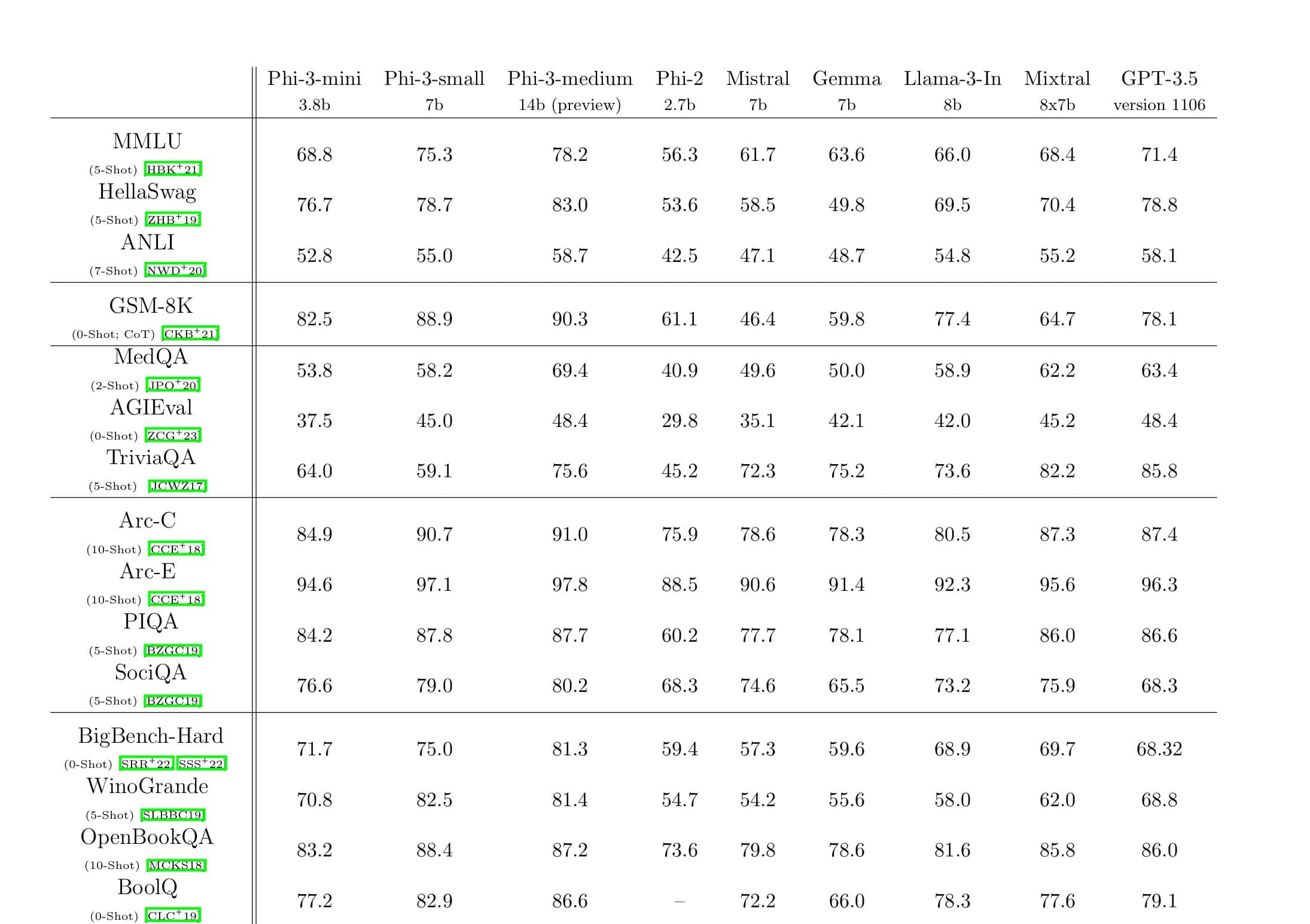
Microsoft Research ha annunciato oggi DeepSpeed, una nuova libreria di ottimizzazione del deep learning in grado di addestrare enormi modelli da 100 miliardi di parametri. Nell'IA, è necessario disporre di modelli di linguaggio naturale più grandi per una migliore precisione. Ma la formazione di modelli di linguaggio naturale più ampi richiede tempo e i costi associati sono molto elevati. Microsoft afferma che la nuova libreria di deep learning DeepSpeed migliora la velocità, i costi, la scalabilità e l'usabilità.
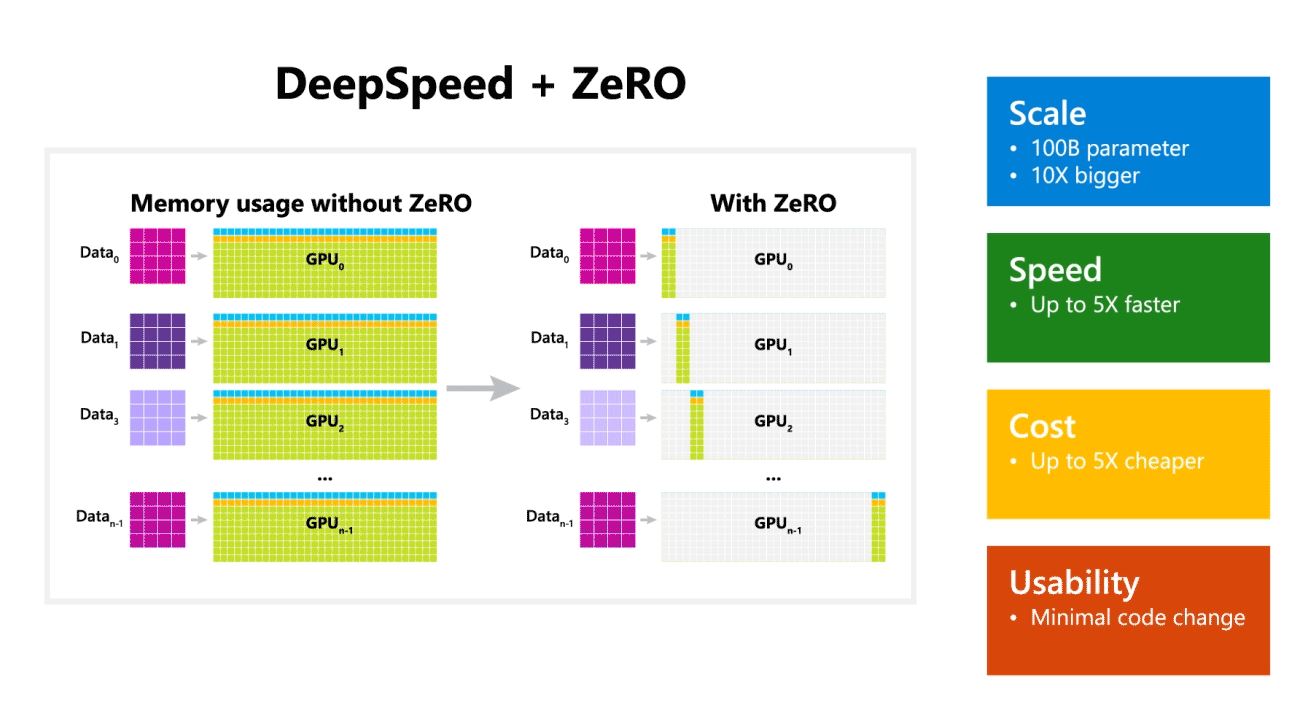
Microsoft ha anche affermato che DeepSpeed abilita modelli linguistici con un massimo di 100 miliardi di modelli di parametri e include ZeRO (Zero Redundancy Optimizer), un ottimizzatore parallelizzato che riduce le risorse necessarie per il parallelismo di modelli e dati aumentando il numero di parametri che possono essere addestrati . Utilizzando DeepSpeed e ZeRO, i ricercatori Microsoft hanno sviluppato la nuova Turing Natural Language Generation (Turing-NLG), il più grande modello linguistico con 17 miliardi di parametri.
Punti salienti di DeepSpeed:
- Scala: I modelli di grandi dimensioni all'avanguardia come OpenAI GPT-2, NVIDIA Megatron-LM e Google T5 hanno dimensioni rispettivamente di 1.5 miliardi, 8.3 miliardi e 11 miliardi di parametri. ZeRO stage uno in DeepSpeed fornisce il supporto del sistema per eseguire modelli fino a 100 miliardi di parametri, 10 volte più grandi.
- Velocità: Osserviamo un throughput fino a cinque volte superiore rispetto allo stato dell'arte su vari hardware. Sui cluster di GPU NVIDIA con interconnessione a larghezza di banda ridotta (senza NVIDIA NVLink o Infiniband), otteniamo un miglioramento del throughput di 3.75 volte rispetto all'utilizzo di Megatron-LM da solo per un modello GPT-2 standard con 1.5 miliardi di parametri. Sui cluster NVIDIA DGX-2 con interconnessione a larghezza di banda elevata, per modelli da 20 a 80 miliardi di parametri, siamo da tre a cinque volte più veloci.
- Costo: Il miglioramento della produttività può essere tradotto in costi di formazione notevolmente ridotti. Ad esempio, per addestrare un modello con 20 miliardi di parametri, DeepSpeed richiede tre volte meno risorse.
- usabilità: Sono necessarie solo poche righe di modifiche al codice per consentire a un modello PyTorch di utilizzare DeepSpeed e ZeRO. Rispetto alle attuali librerie di parallelismo del modello, DeepSpeed non richiede una riprogettazione del codice o un refactoring del modello.
Microsoft sta acquistando sia DeepSpeed che ZeRO, puoi verificarlo qui su GitHub.
Fonte: Microsoft