Microsoft membuktikan bahwa GPT-4 dapat mengalahkan Google Gemini Ultra menggunakan teknik prompt baru
![]() 2 menit Baca
2 menit Baca
![]() Ditampilkan di
Ditampilkan di
Bagikan artikel ini

Sempurnakan panduan ini
Baca halaman pengungkapan kami untuk mengetahui bagaimana Anda dapat membantu MSPoweruser mempertahankan tim editorial Baca lebih lanjut
Minggu lalu, Google mengumumkan Gemini, modelnya yang paling mumpuni dan umum. Model Google Gemini memberikan kinerja tercanggih di banyak tolok ukur terkemuka. Google menyoroti bahwa performa model Gemini Ultra yang paling mumpuni melebihi hasil OpenAI GPT-4 pada 30 dari 32 tolok ukur akademik yang banyak digunakan dalam penelitian dan pengembangan model bahasa besar (LLM).
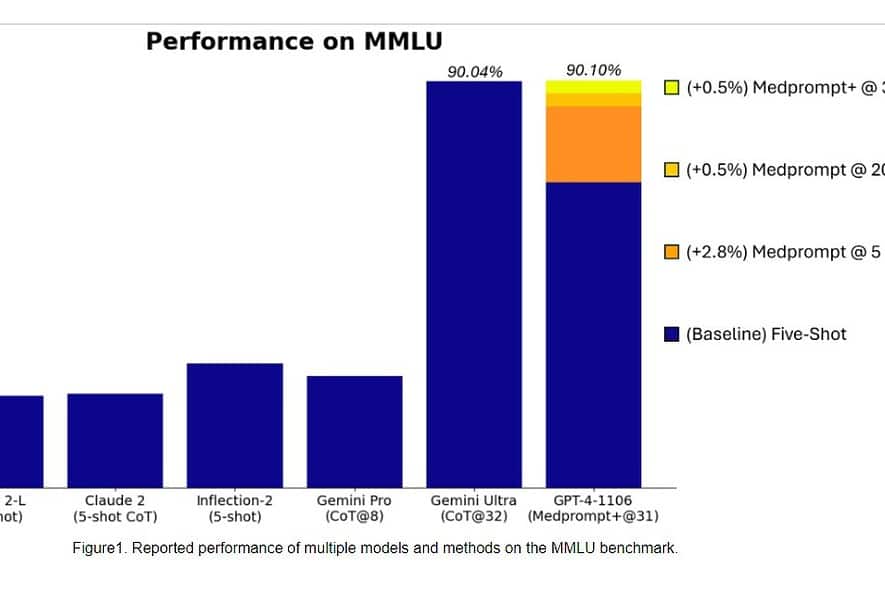
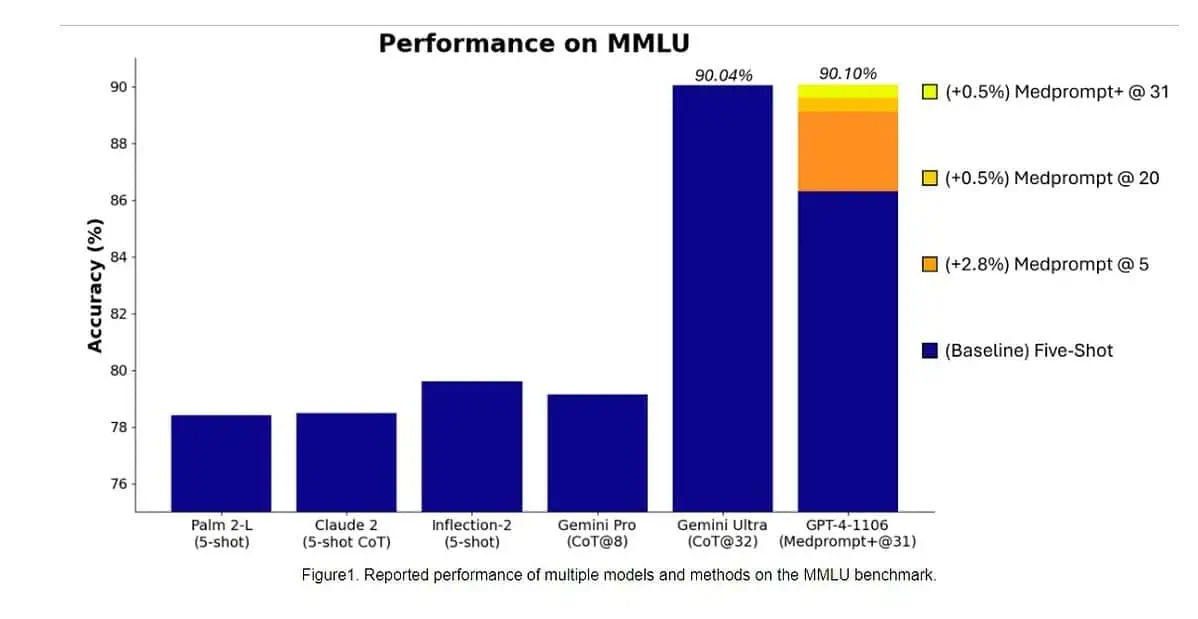
Secara khusus, Gemini Ultra menjadi model pertama yang mengungguli pakar manusia dalam MMLU (pemahaman bahasa multitugas masif) dengan skor 90%, yang menggunakan kombinasi 57 mata pelajaran seperti matematika, fisika, sejarah, hukum, kedokteran, dan etika untuk menguji pengetahuan dunia. dan kemampuan memecahkan masalah.
Kemarin, tim Riset Microsoft mengungkapkan bahwa model GPT-4 OpenAI dapat mengalahkan Google Gemini Ultra ketika teknik prompt baru digunakan. Bulan lalu, Microsoft Research mengungkapkan cepat med, komposisi dari beberapa strategi pendorong yang sangat meningkatkan kinerja GPT-4 dan mencapai hasil canggih dalam rangkaian MultiMedQA. Microsoft kini telah menerapkan teknik prompt yang digunakan di Medprompt untuk domain umum juga. Menurut Microsoft, model GPT-4 OpenAI bila digunakan dengan versi Medprompt yang dimodifikasi mencapai skor tertinggi yang pernah dicapai pada MMLU lengkap. Ya, OpenAI GPT-4 dapat mengalahkan model Gemini Ultra yang akan datang hanya dengan menggunakan teknik prompt. Hal ini menunjukkan bahwa kami belum mencapai potensi penuh dari model yang sudah dirilis seperti GPT-4.
Lihatlah perbandingan benchmark antara GPT-4 (permintaan yang ditingkatkan) dan model Gemini Ultra di bawah ini.
| patokan | Perintah GPT-4 | Hasil GPT-4 | Hasil Ultra Gemini |
|---|---|---|---|
| MMLU | medprompt+ | 90.10% | 90.04% |
| GSM8K | Tembakan nol | 95.27% | 94.4% |
| MATH | Tembakan nol | 68.42% | 53.2% |
| Evaluasi Manusia | Tembakan nol | 87.8% | 74.4% |
| Bangku BESAR-Keras | Beberapa tembakan + CoT* | 89.0% | 83.6% |
| DROP | Tembakan nol + CoT | 83.7% | 82.4% |
| HellaSwag | 10 tembakan** | 95.3% | 87.8% |
Pertama, Microsoft menerapkan Medprompt asli ke GPT-4 untuk mencapai skor 89.1% di MMLU. Kemudian, Microsoft meningkatkan jumlah panggilan gabungan di Medprompt dari lima menjadi 20, yang menghasilkan peningkatan skor sebesar 89.56%. Microsoft kemudian memperluas Medprompt ke Medprompt+ dengan menambahkan metode dorongan yang lebih sederhana dan merumuskan kebijakan untuk mendapatkan jawaban akhir dengan mengintegrasikan keluaran dari strategi dasar Medprompt dan perintah sederhana. Hal ini menyebabkan GPT-4 mencapai rekor skor 90.10%. Tim Riset Microsoft menyebutkan bahwa tim Google Gemini juga menggunakan teknik dorongan serupa untuk mencapai rekor skor di MMLU.
Anda dapat mempelajari lebih lanjut tentang teknik prompt yang digunakan Microsoft untuk mengalahkan Gemini Ultra di sini.