Apakah Claude 3 lebih baik dari GPT-4? Pembandingan Promptbase mengatakan berbeda
Tes head-to-head menunjukkan GPT-4 Turbo mengungguli Claude 3 di semua kategori.
![]() 2 menit Baca
2 menit Baca
![]() Ditampilkan di
Ditampilkan di
Bagikan artikel ini

Sempurnakan panduan ini
Baca halaman pengungkapan kami untuk mengetahui bagaimana Anda dapat membantu MSPoweruser mempertahankan tim editorial Baca lebih lanjut
Catatan kunci
- Anthropic baru-baru ini meluncurkan Claude 3, disebut-sebut mengungguli GPT-4 dan Google Gemini 1.0 Ultra.
- Skor benchmark yang diposting menunjukkan Claude 3 Opus unggul di berbagai bidang dibandingkan rekan-rekannya.
- Namun, analisis lebih lanjut menunjukkan bahwa GPT-4 Turbo mengungguli Claude 3 dalam perbandingan langsung, yang menyiratkan potensi bias dalam hasil yang dilaporkan.

Antropik baru saja meluncurkan Claude 3 belum lama ini, model AI-nya dikatakan mampu mengalahkan OpenAI GPT-4 dan Google Gemini 1.0 Ultra. Muncul dengan tiga varian: Claude 3 Haiku, Soneta, dan Opus, semuanya untuk kegunaan berbeda.
Dalam nya pengumuman awal, perusahaan AI mengatakan bahwa Claude 3 sedikit lebih unggul dari dua model yang baru diluncurkan ini.
Menurut skor benchmark yang diposting, Claude 3 Opus lebih baik dalam pengetahuan tingkat sarjana (MMLU), penalaran tingkat pascasarjana (GPQA), matematika sekolah dasar dan pemecahan masalah matematika, matematika multibahasa, coding, penalaran melalui teks, dan lain-lain. daripada GPT-4 dan Gemini 1.0 Ultra dan Pro.
Namun, hal itu tidak sepenuhnya menggambarkan keseluruhan gambaran yang sebenarnya. Skor benchmark yang diposting pada pengumuman tersebut (khusus untuk GPT-4) ternyata diambil dari GPT-4 pada versi rilis Maret 2023 tahun lalu (kredit untuk penggila AI @TolgaBilge_ di X)
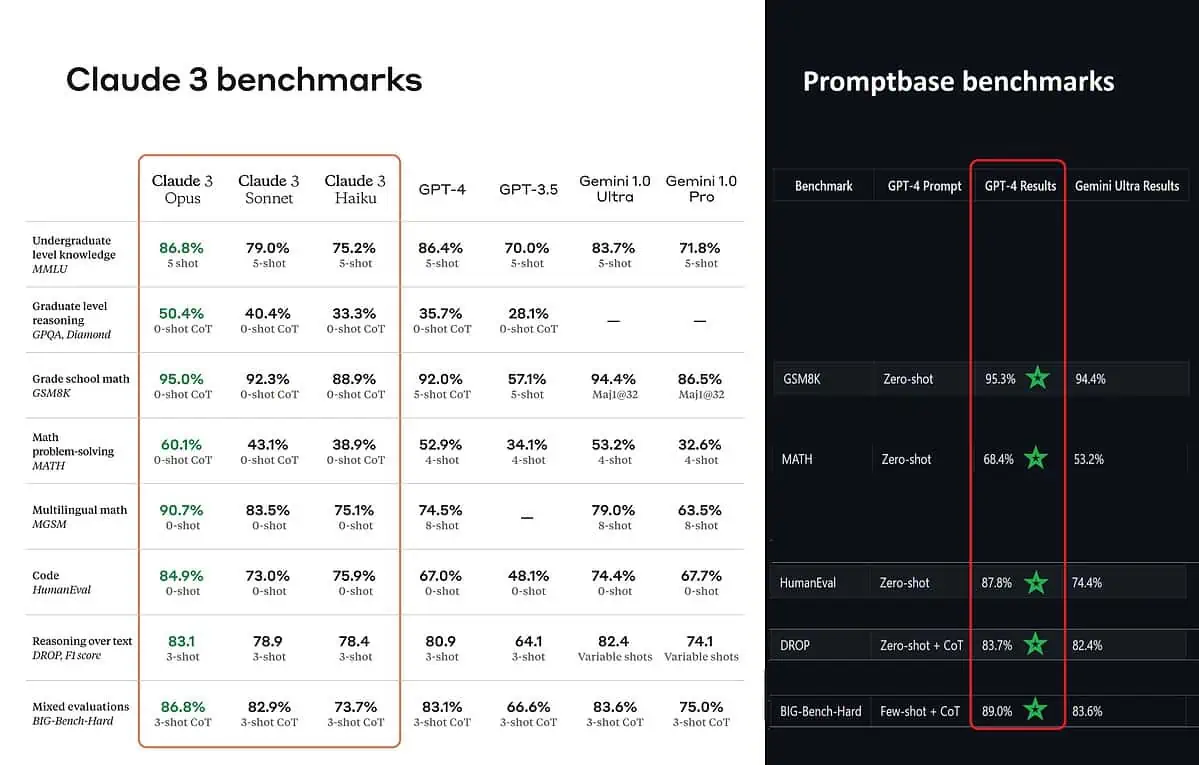
Alat yang menganalisis kinerja (benchmark analisa) disebut basis cepat menunjukkan bahwa GPT-4 Turbo benar-benar mengalahkan Claude 3 di semua pengujian yang dapat mereka bandingkan secara langsung. Tes ini mencakup hal-hal seperti keterampilan matematika dasar (GSM8K & MATH), menulis kode (HumanEval), penalaran melalui teks (DROP), dan berbagai tantangan lainnya.
Saat mengumumkan hasilnya, Anthropic juga disebutkan dalam catatan kaki bahwa teknisi mereka dapat meningkatkan kinerja GPT-4T lebih lanjut dengan menyempurnakannya secara khusus untuk pengujian. Hal ini menunjukkan bahwa hasil yang dilaporkan mungkin tidak mencerminkan kemampuan sebenarnya dari model dasar.
Aduh.